S03: 1.1 Autograd 自动求导
笔者手写了简单的深度学习框架),这个小项目源于笔者学习pytorch的过程中对autograd的探索。项目名称为kitorch。该项目基于numpy实现,代码的执行效率比cpu的pytorch要慢。虽然如此,我想对于初学者来说,有兴趣的同学还是可以看一下的。本项目代码见github。
第一章 基于Autograd的Tensor类
1.1 Autograd 自动求导
本章是《手写深度学习框架》的第一章节。与很多教程不同的是,我们不从神经网络基本原理开始,这方面优秀的教程实在是太多了。强烈建议初学者阅读一个简短的教程Neural Networks and Deep Learning,阅读完这个教程后,你至少懂得神经网络基本原理,模型训练,以及如何用Python实现一个简单的网络。
我们直接从自动求导讲起。依据自动求导我们就可以搭建一个简易的深度学习框架了。让我们开始吧。下面让我们了解一些导数的基本知识。
链式法则
链式法则是微积分中的基本求导法则,用于求一个复合函数的导数。复合函数的导数是将构成这个复合函数的所有子函数在相应点的导数的乘积,就像锁链一样一环套一环,故称链式法则。比如 f f f是 x x x的函数, g g g是 f f f的函数, h h h是 g g g的函数, L L L是 h h h的函数,简单表示:
L ← h ← g ← f ← x L \leftarrow {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} h \leftarrow g \leftarrow f \leftarrow x L←h←g←f←x
那么 L L L对 x x x的导数为:
∂ L ∂ x = ∂ L ∂ h ⋅ ∂ h ∂ g ⋅ ∂ g ∂ f ⋅ ∂ f ∂ x \frac{{\partial L}}{{\partial x}} = \frac{{\partial L}}{{\partial h}}{\kern 1pt} \cdot \frac{{\partial h}}{{\partial g}}{\kern 1pt} \cdot {\kern 1pt} \frac{{\partial g}}{{\partial f}}{\kern 1pt} \cdot {\kern 1pt} {\kern 1pt} \frac{{\partial f}}{{\partial x}} ∂x∂L=∂h∂L⋅∂g∂h⋅∂f∂g⋅∂x∂f
全导数
连式法则也可以应用到多元函数,多元函数导数称为全导数:
L ← ( u , v ) ← ( x , y ) L \leftarrow \left( {u,v} \right) \leftarrow \left( {x,y} \right) L←(u,v)←(x,y)
它的导数:
∂ L ∂ x = ∂ L ∂ u ⋅ ∂ u ∂ x + ∂ L ∂ v ⋅ ∂ v ∂ x ∂ L ∂ y = ∂ L ∂ u ⋅ ∂ u ∂ y + ∂ L ∂ v ⋅ ∂ v ∂ y \frac{{\partial L}}{{\partial x}} = {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \frac{{\partial L}}{{\partial u}}{\kern 1pt} \cdot \frac{{\partial u}}{{\partial x}}{\kern 1pt} + {\kern 1pt} \frac{{\partial L}}{{\partial v}}{\kern 1pt} \cdot {\kern 1pt} {\kern 1pt} \frac{{\partial v}}{{\partial x}}\\ \frac{{\partial L}}{{\partial y}} = {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \frac{{\partial L}}{{\partial u}}{\kern 1pt} \cdot \frac{{\partial u}}{{\partial y}}{\kern 1pt} + {\kern 1pt} \frac{{\partial L}}{{\partial v}}{\kern 1pt} \cdot {\kern 1pt} {\kern 1pt} \frac{{\partial v}}{{\partial y}} ∂x∂L=∂u∂L⋅∂x∂u+∂v∂L⋅∂x∂v∂y∂L=∂u∂L⋅∂y∂u+∂v∂L⋅∂y∂v
上面这个两个知识点就是自动求导的骨架。神经网络就是一个及其复杂的多元函数,我们不可能手动去计算整个网络,但是后面我们会对一些单层进行详细的推导。
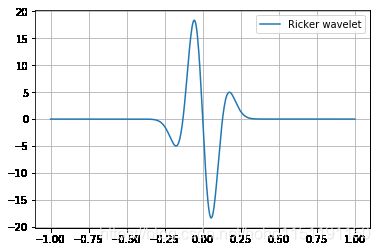
我们举一个小例子,这个函数是雷克子波(Ricker wavelet)
y = ( 1 − 2 ( π f m t ) 2 ) e − π f m t y = \left( {1 - 2{{\left( {\pi {f_m}t} \right)}^2}} \right){e^{ - \pi {f_m}t}} y=(1−2(πfmt)2)e−πfmt
其中 t t t 是自变量。它长得这个样子:
import math
import numpy as np
from matplotlib import pyplot as plt
def plot(x,y=[],title=None):
if title:
plt.title(title)
if y:
for line in y:
plt.plot(x,line[0],label=line[1])
else:
plt.plot(x)
plt.grid(True)
plt.legend()
plt.show()
fm = 3
pi = 3.14
num_points = 500
t = np.linspace(-1,1,num_points)
ricker = (1-2*(pi*fm*t)**2)*np.exp(-(pi*fm*t)**2)
plot(t,[(ricker,'Ricker wavelet')])

好了,我们求下它的导数,然后… …
&%exp^%@#%%&)(&+)_
我太难了(>_<),求不出来呀,还是借助其他的方式吧(^ _ ^),我们先了解下符号导数。
符号求导
符号求导就是用计算机推导数学公式。符号计算可以得到精确的解,但是计算量大且表达形式庞大。我们借助sympy体会下符号求导的威力。
import sympy
t = sympy.Symbol('t')
fm = sympy.Symbol('fm')
pi = sympy.Symbol('pi')
s_ricker = (1-2*(pi*fm*t)**2)*sympy.exp(-(pi*fm*t)**2)
diff_t = sympy.simplify(sympy.diff(s_ricker,t))
输出结果是:
#2*fm**2*pi**2*t*(2*fm**2*pi**2*t**2 - 3)*exp(-fm**2*pi**2*t**2)
fm = 3
pi = 3.14
num_points = 500
t = np.linspace(-1,1,num_points)
sd_ricker = 2*fm**2*pi**2*t*(2*fm**2*pi**2*t**2 - 3)*np.exp(-fm**2*pi**2*t**2)
plot(t,[(sd_ricker,'Ricker wavelet')])
上面我们用符号求导计算出了 Ricker wavelet 的导数。这是精确解,它将作为其他方法的验证标准。下面我们看一下数值微分。
数值微分
数值微分(numerical differentiation)根据函数在一些离散点的函数值,推算它在某点的导数或高阶导数的近似值的方法.
数值微分一般包括有限差分、有限元、伪谱法等。这里简单介绍最简单的有限差分。有限差分就是按照导数的定义进行计算计算的,利用差商代替微商。
f ′ ( x ) = lim h → ∞ f ( x + h ) − f ( x ) h f'(x) = \mathop {\lim }\limits_{h \to \infty } \frac{{f(x + h) - f(x)}}{h}\\ f′(x)=h→∞limhf(x+h)−f(x)
用差商近似微商:
f ′ ( x ) ≈ f ( x + h ) − f ( x ) h ≈ f ( x + h ) − f ( x − h ) 2 h f'(x) \approx \frac{{f(x + h) - f(x)}}{h} \approx \frac{{f(x + h) - f(x-h)}}{2h} f′(x)≈hf(x+h)−f(x)≈2hf(x+h)−f(x−h)
对于上式子,我们可以得到一组 $ [1,-1] $ 的系数,这称作一阶近似。下面看 Ricker wavelet 的例子:
delta_t = t[1]-t[0]
fd_ricker = np.zeros(num_points)
fd_ricker[1:-1] = (ricker[2::]-ricker[0:-2])/(2*delta_t)
plot(t,[(fd_ricker,'FD'),(sd_ricker,'Sym')])
plot(t,[(fd_ricker-sd_ricker,'error')])
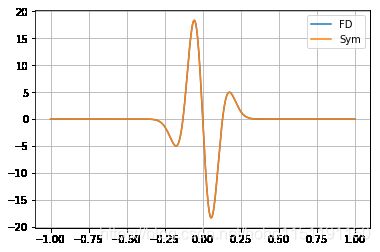

从上图我们可以看到,数值微分是具有截断误差的。下面进入主角,自动微分。
自动微分
自动微分有两种形式,Forward mode 和 Reverse Mode。这里我们只讲 Reverse mode。
两个基本知识点:连式法则和全导数。
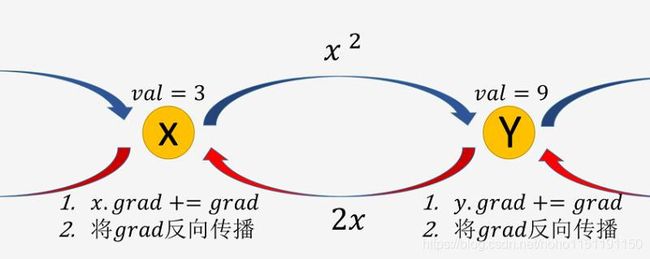
上图的蓝色箭头表示的是正向计算: x x x 经过一个 f o r w a r d = x 2 forward = x^2 forward=x2 的运算得到 y y y
红色箭头表示反向计算:对于 y y y 获得的 g r a d grad grad,它首先要加到自己的 g r a d grad grad 上,即 y . g r a d + = g r a d y.grad+=grad y.grad+=grad,该点是全导数的体现,
然后通过 f o r w a r d forward forward 的逆运算 b a c k w a r d = 2 ∗ g r a d backward= 2*grad backward=2∗grad 将梯度传递下去,该点是链式法则的体现。
具体看,下面这段代码
import numpy as np
class Var:
def __init__(self,val,
requires_grad = False,
grad_fn=None,
depends_on = []):
self.val = val
self.requires_grad = requires_grad
self.grad_fn = grad_fn
self.depends_on = depends_on
self.grad = 0
def backward(self,grad):
self.grad += grad
for edge in self.depends_on:
var,cache = edge
_grad = self.grad_fn(grad,var,cache)
var.backward(_grad)
def __add__(self,other):
depends_on = []
grad_fn = AddBackward
requires_grad = self.requires_grad
if self.requires_grad:
depends_on.append((self,[]))
if isinstance(other,Var):
val = self.val + other.val
requires_grad = requires_grad or other.requires_grad
if other.requires_grad:
depends_on.append((other,[]))
else:
val = self.val + other
return Var(val,
requires_grad=requires_grad,
grad_fn = grad_fn,
depends_on = depends_on
)
def __radd__(self,other):
return self.__add__(other)
def __mul__(self,other):
depends_on = []
grad_fn = MulBackward
requires_grad = self.requires_grad
if isinstance(other,Var):
val = self.val * other.val
requires_grad = requires_grad or other.requires_grad
if self.requires_grad:
depends_on.append((self,[other.val]))
if other.requires_grad:
depends_on.append((other,[self.val]))
else:
val = self.val * other
if self.requires_grad:
depends_on.append((self,[other]))
return Var(val,
requires_grad=requires_grad,
grad_fn = grad_fn,
depends_on = depends_on
)
def __rmul__(self,other):
return self.__mul__(other)
def __pow__(self,power):
depends_on = []
grad_fn = PowBackward
requires_grad = self.requires_grad
val = np.power(self.val,power)
if self.requires_grad:
depends_on.append((self,[power]))
return Var(val,
requires_grad=requires_grad,
grad_fn = grad_fn,
depends_on = depends_on
)
def exp(self):
depends_on = []
grad_fn = ExpBackward
requires_grad = self.requires_grad
val = np.exp(self.val)
if self.requires_grad:
depends_on.append((self,[val]))
return Var(val,
requires_grad=requires_grad,
grad_fn = grad_fn,
depends_on = depends_on
)
def AddBackward(grad,var,cache):
return grad*np.ones_like(var.val)
def MulBackward(grad,var,cache):
return grad * cache[0]
def PowBackward(grad,var,cache):
power = cache[0]
return grad * power * np.power(var.val,power-1)
def ExpBackward(grad,var,cache):
return grad * cache[0]
我们重新定义了一个类Var,Var类具有自动微分的功能。
v_t = Var(t,requires_grad=True)
v_ricker = (1+(-2*(pi*fm*v_t)**2))*(-1*(pi*fm*v_t)**2).exp()
plot(t,[(ricker,'Ricker wavelet'),(v_ricker.val,'Var Ricker')])
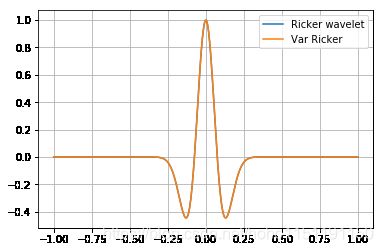
利用backward计算它的导数
v_ricker.backward(1)
plot(t,[(fd_ricker,'FD'),(sd_ricker,'Sym'),(v_t.grad,'BP')])
plot(t,[(fd_ricker-sd_ricker,'Sym-FD'),(v_t.grad-sd_ricker,'Sym-BP')])
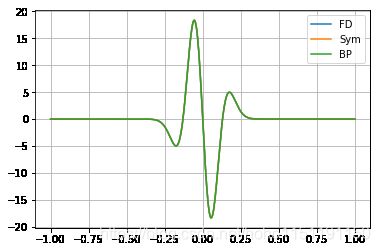
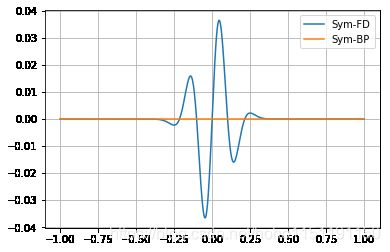
从上图我们可以看到,自动微分与精确解是没有误差的。
第一节,我们就到这里了。在这一节,我们回顾了关于导数的两个知识点链式法则和全导数,符号导数,数值微分,讲解了自动微分。下一节我们讲围绕自动微分,构建Tensor类。