SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation 阅读笔记
SimCC:一种用于人体姿态估计的简单坐标分类方法
ECCV 2022
论文链接
代码链接
摘要: 近几年,高性能的2D热图法在人体姿态估计(HPE)领域独领风骚。但2D热图法中长期存在的量化误差导致了几个常见的缺点:1) 对低分辨率输入的性能有限;2) 需要多个高代价上采样层恢复特征图分辨率以提高定位精度;3) 需采用额外的后处理来减少量化误差。为解决这些问题,我们旨在探索一种全新的方案 SimCC,它将HPE重新定义为水平和垂直方向坐标的两个分类任务。SimCC将每个像素均匀划分为若干个bins,从而实现 sub-pixel 定位精度和低量化误差,得益于此,SimCC可以省略额外的细化后处理步骤,并在某些设置下摒弃上采样层,从而为HPE提供更简单有效的pipeline。在COCO、CrowdPose和MPII数据集上的大量实验表明,SimCC优于热图法,尤其能很大程度提高低分辨率输入的性能。
文章目录
- SimCC:一种用于人体姿态估计的简单坐标分类方法
- 1 Introduction
- 2 Related Work
- 3 SimCC: Reformulating HPE from Classification Perspective
-
- 3.1 与2D热图法对比
- 4 Experiments
-
- 4.1 COCO Keypoint Detection
- 4.2 Ablation Study
- 4.3 CrowdPose
- 4.4 MPII Human Pose Estimation
- 5 Limitation and Future Work
- 6 Conclusion
- 7 个人感悟
1 Introduction
2D HPE旨在定位单幅图像的人体关键点,近几年热图法已成为该领域的标准做法,2D热图生成为以 GT 关节位置为中心的二维高斯分布,为每个位置分配概率值来抑制假阳性并平滑训练过程。
尽管热图法取得了成功,但将连续坐标值映射到离散的2D下采样热图会引起量化误差。 大量量化误差带来了几个常见的缺点:1) 采用高代价的上采样层(例如转置卷积层)增加特征图分辨率以减轻量化误差;2) 引入额外的后处理(例如,empirical shift, DARK)以改进预测;3) 由于严重的量化误差,低分辨率输入的性能令人大失所望。高分辨率2D热图带来高计算成本,降低量化误差自然而然的方法是先将2D热图解耦为1D热图,再提高分辨率,Yin等人对面部标志区域进行了探索,但为实现此目标,Yin等人引入了额外的解耦层(即,一个 co-attention 模块和多个卷积层)和高代价的反卷积模块,形成比2D热图法更复杂的pipeline,如图1所示。

因此,本项工作试图探索一种全新方案来抗衡基于热图的HPE方法。具体而言,我们提出了一种简单且有效的坐标分类pipeline: SimCC,将HPE视为水平和垂直坐标的两个分类任务。 SimCC先采用基于CNN 或 Transformer的backbone来提取关键点表示,然后独立执行垂直和水平坐标的坐标分类来生成最终预测。为降低量化误差,SimCC将每个像素均匀划分为若干个bins,实现了 sub-pixel 定位精度。 注意,不同于可能引入多个反卷积层的热图法,SimCC只需要两个轻量级分类器头(即每个头只需要一个线性层)。
图1所示为SimCC和1D/2D热图法的比较。相比于2D热图法,SimCC有三个优点:1)它通过将每个像素均匀划分为几个bins来减少量化误差;2) SimCC在某些设置下省略了上采样层,并排除了高代价的细化后处理,这对现实的应用更友好;3) SimCC在低分辨率输入情况下的性能也差强人意。我们的贡献总结如下:
- 我们提出了一种用于人体姿态估计的坐标分类pipeline:SimCC,将该问题重新表述为水平和垂直坐标的两个分类任务。SimCC是一种通用方案,易于应用在现有的基于CNN或基于Transformer的HPE模型。
- SimCC通过省略热图法中额外的耗时上采样和后处理来实现高效率。特别是,应用SimCC的SimBa-Res50减少了高达55%的GFLOPs,实现了比热图法更高的性能。
- 在COCO、CrowdPose和MPII数据集上的实验验证了具有不同backbone和多输入大小的SimCC的有效性。
我们认为,因为热图法计算成本高,后处理复杂,在低输入分辨率下性能差,它可能不是HPE的最佳方案。我们希望SimCC能为HPE的潜在研究工作和实际部署提供新角度。
2 Related Work
基于回归的HPE. 回归法常见于2D人体姿态估计的早期阶段,不同于依赖2D grid-like 热图,这条工作线在计算友好的框架中直接回归关键点坐标,但由于其低性能,仅少数现有方法采用该方案。最近,Li等人引入了残差对数似然(RLE),利用归一化流(normalizing flows)来捕获潜在的输出分布,并使回归法与sota热图法的精度相匹配。RLE的核心思想是基于归一化流构建自适应loss,因此是对我们工作的补充。
基于2D热图的HPE. 另一条工作线采用二维高斯分布(即热图)来表示关节坐标。热图上的每个位置都被指定为GT点的概率。作为热图的最早应用之一,Tompson等人提出了一种由深度卷积网络和马尔可夫随机场组成的混合架构。Newell等人引入沙漏架构;Papandreou等人提出聚集热图和偏移预测来提高定位精度;Xiao等人提出了一个简单的baseline,利用主干网络后的三个反卷积层来获得最终预测热图。相反,Sun等人提出了一种新的网络,在整个过程中保持高分辨率表示,实现了显著的改进。由于涉及空间不确定性,这种学习模式具有对抖动错误的容忍度,因此,热图法多年来保持稳定的sota性能。但量化误差仍然是热图法一个不可忽略的问题,尤其对于低分辨率输入。
量化误差. 为了解决离散化2D下采样热图造成的较大量化误差,Zhang等人提出采用基于泰勒展开的分布近似作为后处理,综合考虑热图激活的分布信息。Yin等人探索了缓解量化误差的另一种尝试,用于面部 lanmark 检测,该方法采用可学习的解耦层将2D热图转换为1D热图,然后使用额外的反卷积层提高1D热像图分辨率。
面部landmark的1D热图回归. 人体姿态估计领域外,基于一维热图的方法用于面部landmark检测,Yin等人提出了一种 attentive 一维热图回归方法,旨在通过使用反卷积层来提高解耦的一维热图分辨率来缓解量化误差。为了捕获解耦的一维热图间的联合分布信息,在一维热图回归中引入了co-attention模块。
坐标分类。 Chen等人提出Pix2Seq将目标检测转换为语言建模任务,其中对象被描述为五个离散token序列,用于进一步分类。在Pix2Seq中,Transformer Encoder 架构对“read out”每个对象(产生预测)至关重要。相比之下,SimCC旨在探索一种新的途径来抗衡基于热图的人体姿态估计方法,SimCC可以容易地与CNN或基于 Transformer 的HPE方法相结合,且不需要额外的Transformer Encoder来生成预测。
3 SimCC: Reformulating HPE from Classification Perspective
SimCC的关键思想是将人体姿态估计视为垂直和水平坐标的两个分类任务,并通过将每个像素划分为多个bins来减少量化误差。图2所示为由主干网络和两个分类器头组成的SimCC示意图。本节详细描述每个组件。

图2:SimCC pipeline。SimCC先通过基于CNN或Transformer的backbone提取 n 个关键点表示。对基于CNN的主干,我们简单地将关键点表示从(n,H′,W′)展平到(n,H′×W′)用于后续分类。基于n个关键点表示,SimCC独立地对水平轴和垂直轴执行坐标分类,以产生最终预测。具体而言,给定第 i 个关键点表示作为输入,水平和垂直坐标分类器(即,每个分类器仅一个线性层)分别生成第 i 个关键点预测oix和oiy。注意,SimCC将每个像素均匀地划分为多个bins,从而减少量化误差并实现 sub-pixel 定位精度。
Backbone. 给定大小为H×W×3的输入图像,SimCC使用基于CNN或基于 Transformer 的网络(例如,HRNet,TokenPose)作为backbone 来提取n个关键点表示。
Head. 如图2所示,水平和垂直分类器(即,每个分类器仅一个线性层)分别附加在 backbone 后来执行坐标分类。对于基于 CNN 的 backbone ,我们简单地将输出的关键点表示从(n,H′,W′)展平到(n,H′×W′)进行分类。相比于使用多个高代价的反卷积层作 head 的热图法,SimCC头部更轻且简单。
n个关键点对应n个embedding,也就是网络输出n条一维向量,再通过线性投影(MLP等)为n个SimCC表征。具体地讲,对于CNN-based模型,可以将输出的特征图拉直为d维的一维向量,再通过线性投影把d维升高到 Wk 维和 Hk 维。而对于Transformer-based模型,输出则已经是一维向量,同样地进行投影即可。
Coordinate classification. 为了实现分类,我们将每个连续坐标值统一离散化为整数作为模型训练的类标签: c x ∈ [ 1 , N x ] , c y ∈ [ 1 , N y ] ,其中 N x = W ⋅ k , N y = H ⋅ k c_x ∈ [1, N_x], c_y ∈ [1, N_y],其中 N_x = W · k , N_y = H · k cx∈[1,Nx],cy∈[1,Ny],其中Nx=W⋅k,Ny=H⋅k 分别表示水平轴和垂直轴的 bins 数。k是 splitting 因子,设置为:≥ 1以减少量化误差,从而产生sub-pixel 定位精度。为生成最终预测,SimCC基于 backbone 学习的n个关键点表示独立地执行垂直和水平坐标分类。具体而言,给定第 i 个关键点表示作为输入,分别由水平坐标分类器和垂直坐标分类器生成第 i 关键点预测 o x i 和 o y i o^i_x 和 o^i_y oxi和oyi。此外,Kullback–Leibler散度用作训练的损失函数。
Label smoothing. 在传统分类任务中,标签平滑广泛用于增强模型性能。因此,我们将其用于SimCC,本文称之为 equal label smoothing 。然而,equal label smoothing 不加区分地惩罚错误标签会忽略相邻标签在人体姿态估计任务中的空间相关性。一个更合理的解决方案应该鼓励模型以这种方式工作:输出类别越接近 groundtruth ,惩罚越小。为解决此问题,我们还探索了使用拉普拉斯或高斯标签平滑,从而使平滑标签遵循相应的分布。除非另有说明,否则SimCC用作具有 equal label smoothing 变体的缩写。
(上面所述的SimCC存在一个问题,即作为分类问题标签是one-hot的,除了正确的那一个点外其他错误坐标是平等,会受到同等的惩罚,但实际上模型预测的位置越接近正确坐标,受到的惩罚应该越低才更合理。因此,本文进一步提出通过1D高斯分布来生成监督信号,使用KL散度作为损失函数,计算目标向量和预测向量的KL散度进行训练)
3.1 与2D热图法对比
该部分对SimCC方案相较于2D热图法的优越性进行了全面调查。
Quantization error. 由于获得或保持高分辨率二维结构具有高昂的计算成本,基于二维热图的方法倾向于输出具有λ×输入分辨率下采样的特征图,这显著增大了量化误差。相反,SimCC将离散化地将每个像素均匀划分为k(≥ 1) 个bins,减少了量化误差并获得sub-pixle定位精度。
Refinement post-processing. 热图法严重依赖额外的后处理(例如,empirical shift 和 DARK) 来减少量化误差。如表1所示,如果不使用后处理进行细化,热图法的性能会显著下降。然而,这些后处理策略通常计算量大,因此对实际应用不友好。例如,DARK 使用 Taylor 展式,需要根据获得的2D热图计算更高的导数。相比之下,SimCC由于其 sub-pixle 定位精度而省略了后处理步骤,从而为HPE提供了更简单的方案。
Low/high resolution robustness. 图3所示为比较结果。得益于低量化误差,SimCC可以在各种输入大小(64×64、128×128、256×192和384×288)下优于热图法,特别在低分辨率下增益显著。第4节讨论了更具体的定量结果。

Speed. SimCC使用SimpleBaseline 等方法摆脱了耗时的反卷积模块,从而加快了推理速度。值得注意的是,去除上采样层后,SimCC的SimpleBaseline-Res50减少了57.3%的GFLOPs,提高了23.5%的速度,相比热图法增加了+0.4 AP。
4 Experiments
在接下来的章节中,我们实证研究了SimCC对2D人体姿态估计的有效性。我们在三个基准数据集上进行了实验:COCO、CrowdPose和MPII。
4.1 COCO Keypoint Detection
作为HPE最大和最具挑战性的数据集之一,COCO包含超过200000张图像和250000个人实例,标记17个关键点(如鼻子、左耳等)。COCO数据集分为三部分:57k图像用于 train set ,5k图像用于 val set,20k图像用于 test-dev set。本文遵循 HRNet 的数据增强。
评估指标: 基于对象关键点相似性(OKS)计算得到的标准average precision(AP)用作COCO数据集的评价指标:
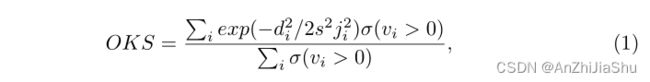
其中, d i d_i di是第 i 个预测关键点坐标与其对应的 groundtruth 坐标间的欧几里德距离, j i j_i ji是常数, v i v_i vi是关键点可视标志,σ表示指标函数,s是对象scale。
Baselines. 有许多基于 CNN 和 Transformer 的HPE方法。为显示SimCC的优越性,CNN选择了两种sota模型(即SimpleBaseline和HRNet),Transformer 选择 TokenPose 作为 baseline。
实现细节. 选择的baseline遵循其论文中的原始设置。具体而言,对于SimpleBaseline,基本学习率设为1e− 3,并分别在第 90 和120 epoch 下降到1e− 4和1e−5 。对HRNet,基本学习率设置为1e− 3,并分别在第 170 和200 epoch 降至1e− 4和1e− 5。
SimpleBaseline和HRNet 的训练epoch分别为140和210。注意,TokenPose-S的训练过程也遵循 HRNet。本文使用两阶段自上而下的人体姿态估计pipelien:先检测人体实例再估计关键点。对COCO val set,采用 SimpleBaseline 中提供的具有56.4%AP的人体检测器。此外,模型训练中使用标签平滑,这通常用于分类任务中,以更好地进行泛化(根据[Rethinking the inception architecture for computer vision],equal smoothing 默认将系数设为0.1)。实验在4个NVIDIA Tesla V100 GPU中进行。
COCO val set上的实验结果。 在COCO2017 val set 上进行了大量实验,以比较不同输入分辨率(64×64、128×128、256×192和384×288)下的二维热图和SimCC方法。注意,评估和网络训练的输入大小相同。我们选择了一些基于CNN和基于transformer的sota方法作为baseline。表1的结果表明,SimCC的性能与热图法相抗衡,尤其在低分辨率输入情况下。例如,基于SimCC的HRNet-W48 在输入大小为256×192时,比热图法高+0.8 AP,在64×64的低输入分辨率下,SimCC性能增益显著(+11.2AP)。
根据表1中的结果,可以进一步得出以下结论:1)热图法严重依赖后处理进行细化,这带来了额外的计算成本,并使整个过程复杂化。例如,若不进行DARK后处理,在输入大小为64×64的情况下,TokenPose-S性能下降了21.2AP;2) 相较于热图法,SimCC在没有任何细化后处理的情况下性能良好,是更简单高效的方案。例如,在输入大小为256×192的情况下,基于SIMCCN的HRNet-W48(不带额外后处理)比热图法(使用empirical shift)高0.8AP。
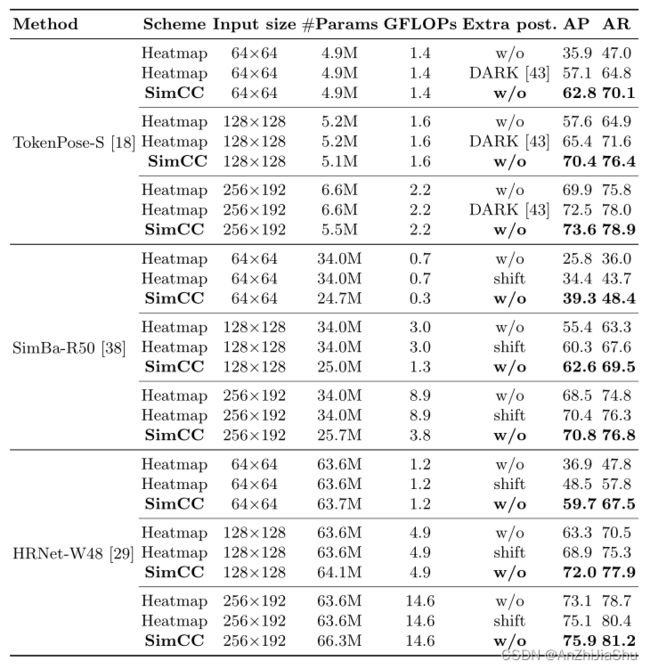
COCO test-dev set 上的实验结果。 表2为COCO test-dev set 上的实验结果。384×288的输入分辨率下,基于SimCC的HRNet-W48和SimpleBaseline-Res50分别超过热图 +0.5AP 和+1.2AP。

推理速度: 我们讨论了 SimCC对SimpleBaseline、TokenPose-S 和HRNet-W48 推理速度的影响。这里的“推断速度”是指模型前馈的平均时间消耗(我们计算了300个样本,batchsize =1)。我们采用FPS来定量说明推理延迟。在同一台机器:Intel(R)Xeon(R)Gold 6130 [email protected] 上显示CPU实现结果。
1) 采用SimCC的SimpleBaseline允许去除 SimpleBaseline 的高代价反卷积层。我们采用SimpleBaselineRes50在输入大小为256×192的COCO-val set上进行实验。基于SimCC的方法w/o反卷积模块超过基于2D热图法+0.4AP(70.8 vs.70.4),速度快23.5%(21 vs. 17 FPS)。第4.2节对反卷积模块进行了更具体的消融研究。
2) 由于SimpleBaseline 使用 encoder-decoder 架构,所以可以用SimCC的分类器头替换其解码器部分(反卷积)。但 HRNet 和 TokenPose 没有额外独立的模块作解码器,为应用SimCC,对HRNet,直接将分类器头 append 到原始HRNet,对TokenPose,替换其MLP head。这些都是对原始架构的微小改变,因此仅为HRNet带来很少的计算开销,甚至减少了TokenPose的模型参数,如表1所示。因此,SimCC仅对HRNet和TokenPose的推理延迟有轻微影响。例如,在输入大小为256×192时,使用热图或SimCC的HRNet-W48的FPS几乎相同(4.5/4.8)。
Is 1D heatmap regression a promising solution for HPE? 我们还研究了将一维热图扩展到HPE上的性能。表3所示,1D热图回归不仅增加了模型参数和计算成本,而且降低了性能。潜在原因可能是面部 landmark 和HPE的核心挑战不同:面部 landmark 具有刚性变形,而人体关节具有更高的自由度。由于 co-attention 模块以及解耦层仅在经验上被验证对面部 landmark 任务有效,因此其推广到其他领域(如HPE)仍不清楚。

4.2 Ablation Study
Splitting factor k. 分裂因子 k 控制SimCC中每个像素的 bins 数,具体而言,k 越大,SimCC的量化误差越小。然而,当k增加时,模型训练变得更加困难。 因此,需要权衡量化误差和模型性能,我们测试基于各种输入分辨率下的SimpleBaseline 和HRNet 下的 k∈ {1,2,3,4}。如图4所示,随着k的增长,模型性能趋于先增加,然后降低。对于HRNet-W32,128×128和256×192输入大小下,k=2。对于SimBa-Res50,对于128×128和256×192输入大小,分别设k=3和k=2。

Upsampling modules. 热图法必不可少的上采样模块通常计算成本高,并大大降低了网络的推理速度。因此,探索应用SimCC是否可以降低HPE对上采样模块的依赖性具有实际意义。请注意,SimpleBaseline 中采用的上采样模块独立于 backbone,因此可以轻松移除。因此,我们基于SimpleBaseline对SimCC w/和w/o反卷积模块进行消融研究。表4显示了COCO2017 val set 上的结果。可以观察到,与热图相比,SimCC允许去除SimpleBaseline中高代价的反卷积层,从而在各种输入分辨率上降低计算成本。例如,基于SimCC的SimpleBaseline-Res50 w/o上采样模块比基于热图的 w/上采样模块高出+0.4AP,在256×192的输入大小下,GFLOPs减少了57.3%。

Label smoothing. 标签平滑是一种用于改进分类任务泛化的常用策略。为了研究其对我们方法的影响,我们使用各种标签平滑策略训练基于SimCC的SimpleBaseline-Res50:{w/o, equal, Gaussian, Laplace}。表5证明了标签平滑策略确实起到了作用。因此,进一步改进SimCC的一个有希望的方法可能是以自适应方式取代启发式标签平滑策略。 进一步的讨论超出了本文的范围,我们将其视为未来的工作。

4.3 CrowdPose
CrowdPose数据集包含比COCO关键点数据集更拥挤的场景。在CrowdPose中有20K个图像和80K个人物实例。训练、验证和测试子集分别由约10K、2K和8K个图像组成。采用与COCO相似的评估指标,额外的 A P E AP^E APE(相对简单样本的AP分数)和 A P H AP^H APH(较难样本的AP评分)。遵循原始论文,采用YoloV3作为人体检测器,batchsize=64。分别在64×64和256×192的输入大小下对CrowdPose测试数据集进行了比较实验。表6中的结果表明,基于SimCC的方法优于基于热图的方法。

4.4 MPII Human Pose Estimation
MPII人体姿态数据集包含4万个具有16个关节标签的人体样本。MPII数据集上使用的数据增强与COCO数据集上的数据增强相同。
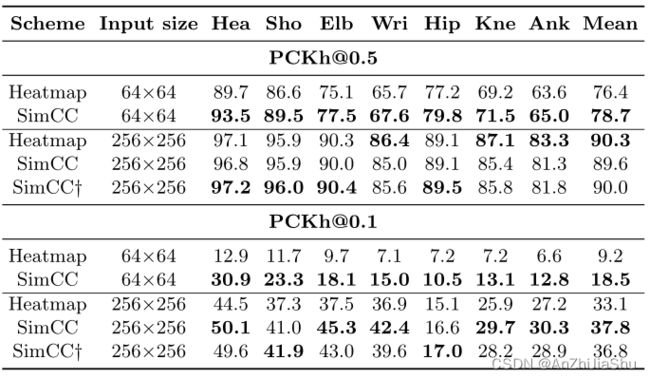
Validatein set 结果。 遵循HRNet中的评估程序。head-normalized probability of correct keypoint (PCKh)分数用于模型评估。结果如表7所示,输入大小为256×256时,基于SimCC的方法在[email protected]下实现了与热图相当的性能,并在更严格的测量[email protected]下增益显著。
5 Limitation and Future Work
本文介绍的SimCC工作是基于自上而下的人体姿态估计。当涉及到自底向上的多人姿态估计时,多人会导致识别模糊。未来工作是以类似于AE(Associative Embedding)的方式引入额外嵌入,以解决候选坐标 x 和 y 值间的匹配问题。
6 Conclusion
本文探索了一种简单且有前景的坐标表示SimCC,它将关键点定位任务视为水平轴和垂直轴分类的两个子任务,将关节位置的x坐标和y坐标表示为两个独立的 1D 向量。实验结果表明,2D结构可能不是保持坐标表示优异性能的关键因素。SimCC在模型性能上优于基于热图表示。此外,它还可能激发HPE轻量化模型设计工作。
7 个人感悟
个人感觉这篇论文实验大于方法,本文做了大量的实验来验证SimCC的有效性,但是并没有讲清楚他为何有效。实验不断提及:通过解耦坐标分类,将像素均匀划分为bins来降低量化误差,但是没有讲清楚具体是如何实现的,以及label smooth讲的也不是很清楚。感觉文章写的不是很详细,具体的实现还是得看代码。