编译原理(六)活前缀,LR文法初步介绍
规范规约就是最左规约,没什么好讲的。一般就是先做规约,再做推导就是这样。
LR(0)文法是什么呢?怎么造出来的呢?它是怎么工作的?
LR分析器的工作过程实际上就是逐步产生规范句型的活前缀。
活前缀就是句柄的子集,状态机一直在分析活前缀,分析出一个句柄之后就分析到头了,然后立马规约这个句柄,就一直在规约句柄。活前缀之所以称为活前缀就是这么来的。为了防止歧义,就不能用NFA。
协议族就是一个闭包。
用Item0表示DFA的初始状态,对应分析的开始,并期待着逐步将输入符号串归约为开始符号S‘。因此将S' --> .S 放到 Item0 中,意即等待归约出S,且目前尚未得到S的任何符号,首先要弄成扩展文法,所谓扩展文法就是加上一个S`开头而已,它们之间是空串连接的。
Item0 = CLOSURE({S' --> .S}) = {S' --> .S,S --> .BB,B --> .aB,B --> .b} 该项目集合中所有的项目都是从S' --> .S 出发 ε-可达的,称为{S' --> .S}的项目集闭包(每个项目集闭包对应着分析器的一个状态),就这么写,非常标准。
5、后继项目:项目 A --> αX.β 称为 A --> α.Xβ 的后继项目
6、后继项目集:假定Item0是文法G的一个LR(0)项目集,则称 Item2 = GO(Item0,B) = CLOSURE({S --> B.B}) = {S --> B.B,B --> .aB,B --> .b} 为 Item0 关于X的后继项目集。GO为项目集的转移函数。
7、项目集规范族:项目集的全体,一个 节点可以由一个闭包表示。
也可以说,实际上每一个文法,都是一个句柄对吧。都是一个直接短语,等到规约了,就是一个短语。
那它的缺点是什么?
2.例子
文法:
S --> BB
B --> aB
B --> b
1.扩展文法
S' --> S
S --> BB
B --> aB
B --> b
2.求出项目集规范族
Item0 = CLOSURE({S' --> .S}) = {S' --> .S,S --> .BB,B --> .aB,B --> .b}
Item1 =GO(Item0,S) = CLOSURE({S' --> S.}) = {S' --> S.}
Item2 = GO(Item0,B) = CLOSURE({S --> B.B}) = {S --> B.B,B --> .aB,B --> .b}
Item3 = GO(Item0,a) = CLOSURE({B --> a.B}) = {B --> a.B,B --> .aB,B --> .b}
Item4 = GO(Item0,b) = CLOSURE({B --> b.}) = {B --> b.}
至此Item0已经遍历完,开始遍历下一个,由于Item1圆点已经到达末尾,所以跳过Item1。
Item5 = GO({Item2,B) = CLOSURE({S --> BB.}) = {S --> BB.}
由于 GO(Item2,a) 和 GO(Item2,b) 重复,所以去掉。反映在图上就是叛经离道的各种线条。
Item6 = GO(Item3,B) = CLOSURE({B --> aB.}) = {B --> aB.}
由于 GO(Item3,a) 和 GO(Item3,b) 重复,所以去掉。
至此,项目集闭包不再增加,所以项目集规范族构造完毕!这种运算方法,就是文字层面上的加点操作。
方法很简单,看一下结果就懂了,在这里就不赘述了。
需要注意的是:要找到每个集合和其他集合所有的转移路径,容易遗漏!
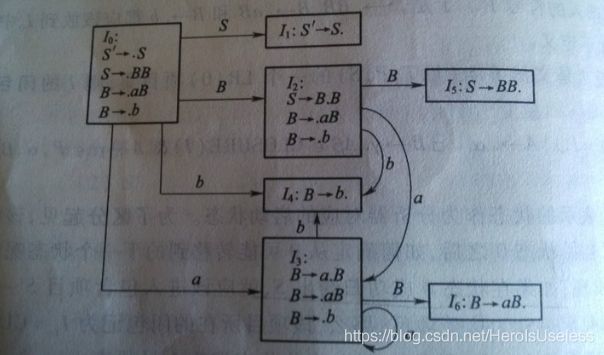
4.构造LR(0)分析表(根据自己画出的DFA图,将分析表填充)
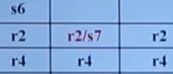
下面讲讲action表和goto表,action表纵列是各状态,横列是转移条件(终结符),格子内有两种元素,以s开头的表示移进并进入状态n,以r开头的表示用第n个产生式规约。
goto表横列是非终结符,里面元素只有一种,就是进入后继状态n,action表是规约,进入后继状态n,而goto表就是直接进入后继状态,它适用于规约后,栈顶是一个非终结符,这时候goto表就在这里用。
大致分析方法是,首先一个状态栈一个符号栈,符号栈里每一个符都有一个状态,如果移入,就把那个顺带的状态移入状态栈,如果是规约,那么弹出多少符号就弹出多少状态,同时不是移入一个新非终结符吗,在goto表里,把这个状态添加上,就可以继续读下面的字符了。一个指针指着字符串的开头,分析器知道这个指针的值,并查表,是移入sn,那么就移入,并在状态栈中添加上该符号的状态。如果是规约,就规约,别忘添加上新非终结符的状态数字,然后进行下一轮的嗯。
图是没法驱动分析的,必须表驱动,或者说表+状态栈驱动,看图比看表费劲,图是如何转化成表的(表是如何制造出来的)?
首先看图,在图中,你要标好每一个图节点的数字是什么,然后看goto表,goto表比较简单,找非终结符的边,看左右节点数字,然后按照约定填入数字即可(因为只是转移),看action表时,如果后面不是到达终点了(嗯怎么说呢,就是在中间的意思),就是移入,添加上状态sn,如果是终点,那么就是规约,按照产生式,填产生式就可以了。
注意规约状态,不管是什么符号,都要填规约符号的(那一行都是)。这个地方看似不合理,其实是LR(0)的特性,它比SLR的FOLLOW集还宽泛。出现任何字符都要规约。虽然后面并没有什么线了。是句柄后的下一个字符。
接受状态只有一个是吧,而且它占一个节点,谁过来就一个acc,就是如此。它一般是状态1,直接从起始节点引过来。也就是S‘->·S是起始项目,S'->S·是接受项目,就是最后的项目。圆点处于末尾就是规约项目。
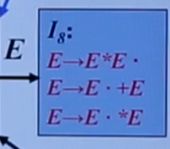
冲突是什么?举例:

这是一个简单算数描述,可以看到,普通数字规约和乘法规约形成了移进-规约冲突,这样,当后继符号是*号,这就出错了。规约项只能单独一个节点。没有任何冲突的文法才是LR(0)文法。不是所有的CFG都能用LR(0)分析。但都是SLR文法知道吧。
这里的一个问题是,如果归结为E->T,后面是*号,但*号不在E的FOLLOW集中!是不是出问题了?即使归结了,也会产生错误。SLR就是看这一个符号的,SLR用FOLLOW集来约束规约。SLR解决的是什么冲突?移进-规约冲突(按理说也不能解决),即移进和规约都在一个节点内,这肯定是不行的,一般是这条线,末端是规约啦移入啦,再看它们接下来的线,就是这样。用FOLLOW集拆开。当然就不是线了,一般规约节点没有后面的线(但是绝对有FOLLOW集),因为整张图就是以活前缀为过程,句柄识别作为结束的,并且规约节点就是到头了,规约节点后还有,没见过。
如果所有规约节点内的产生式的FOLLOW集都不相交,而且与移进项目的点后面的那个终结符不相交。这样,就可以看这个a,或者归约项的follow集来决定哪一项产生式,因为此时的归约项已经点到最后了,只能看follow集,这个点后面符是不是指针符?看哈,在规约的时候,是进入这个规约格,为什么进入这个规约格呢?因为遇到了一个字符和该状态,但现在,矛盾了!例如,它是看见了*号才解决移进还是规约的,还是说这个星号是在前面啊?之前的a应该也是一个follow集。这样,在图中根本体现不出来(指的是规约节点),所以这个字符仍然是指针字符,只不过规约的时候向前看,代表表中规约行(规约状态,节点)的开始区分,只不过LR(0)的规约向前看根本没使用!它也看了!其实SLR本身,FOLLOW仍然不是正确的,所以才会如此规定。向前看一个符号,就是指针后面的符号。K=1的时候,1可以省略,因此叫SLR分析法,而不是SLR(1)分析法。。。
因为FOLLOW集的缘故把一个节点拆出两个节点,在规约行里甚至可以移入,是吧。改正移进-规约冲突就是在规约行里有移入动作就好了。看的这个字符肯定是上一个线上符号的FOLLOW集。这个线上的符号是谁啊?谁是谁的FOLLOW集?很明显,看这个字符,之前线段上的符号的FOLLOW集是这些终结符,来确定这些符号的是哪一个移入规约。
因此说,SLR跟LR的处理是类似的,唯一不同之处是对规约项目的处理上。仅对于具有FOLLOW集(规约的最后一个,就是线上的吧)中的符号进行规约动作。注意SLR也是没有",xxx"那种奇怪的后缀,只有LR(1)才会有。
SLR也是有冲突的,除非不相交是吧。一旦说,规约项的follow集与移入项的后面冲突了怎么办?或者两个归约项的follow集中有相同怎么办?
LR(1)将follow进一步缩减,实际上,在不同的位置,也会使用不同的后继符号,例如赋值语句的左右表达式,左边的表达式后继只能是"=",而右边表达式后面只能是$,就是这么个意思。LR(1)将后继符具体化,通过",XXX"一个一个地指出来,例如“R->L, =”只有当后继符为=时,才可以有产生式进行规约,"R->L, $"两种,这时候叫展望符,实际上仍是指针字符。这里针对表的定义就是之前还在用follow批量操作,这时候就是一个个精准操作。后继符,这里是为了区分移进还是规约,因此移进也会有后继符,这个后继符通常就是后面线上的字符

例如这一个,很明显,大写字母代表非终结符,小写字母代表终结符,那么这里的a代表什么意思,很明显这里是移入项,怎么这么奇怪?但是,它的确符合文法。。。那么它接下来该怎么走呢?这个应该是一个“核”,它不直接走,它通过展开走下边的,核不直接走,后面的a就没有意义。。。那么这个a最多就是规约B用。也不应该放这里。这个a肯定是展望符。

这个问题,嗯,a肯定是展望符,b是B产生式的展望符,它是B的follow集的一部分,但是现在,它就是β对不对,如果β可以为空,那么b就可以是a,实际上,b就是β|a的first集中的元素对不对,原理就是这个。

嗯,名字起的不错。继承是很重要的展望符生成法。
下面咱们再看看,这个展望符,到底是啥呢?展望符就是规约后面的符。对于LR(0)而言,不论碰到什么符,都会规约,就相当于没有符了,对于LR(1)而言,后面的符号决定着规约还是出错。抑或是移进,那么移进的展望符呢?本来就有啊,只不过移进的展望符就作用于该展望符。
那么,Item0的展望符是什么呢?按理说,转移到那个状态之后,再读入这个字符,再决定是规约还是出错,那么现在就是放到前面了,作为产生式的后缀,那么这样的话,假设知道了这个后缀,就可以决定是否移入那个节点,原地报错,现在来看,后缀更多的是一个计算属性,并不能上代码,一个规约节点后面的字符被提到这个规约节点前面的那个节点,这就是展望符的含义。在编程过程中,想不出如何实现,但是比较清晰了。可能就仅仅是一种表达,任何产生式后面都有一个展望符了。
明天再说吧。。。今天失败了,败得很彻底。。。
展望符与后面移入的那个符号是不同的!!!这是怎么回事呢?一般来说,展望符是继承的,移入动作的展望符是不起作用的,规约动作接下来的符号也只是展望符前面的符号,那么这个展望符有什么用呢?这个展望符,在语义上,就是接下来的符号,更确切的说,是非终结符后面的符号。非常直观,在中间的展望符不一定有用,它只起到一个继承的作用,展望符真正有用在终结符之后才有用。而且移入动作后面跟的是等号,也是没有作用的,展望符只在规约动作中有效,移入动作的展望符只是用来继承。这就明白了。凡是后面是非终结符的,展望符仅仅表示继承关系,没有实际意义。

嗯,这个就是同心定义,怎么了?求闭包的时候也就要需要修改展望符了,因为展望符是从上往下继承下来的,一开始就要继承一个$符号。继承取自first(βa)中的符号。但是,它跟SLR,LR(0)的不同之处也只是在规约项目的处理上。通过具体到特定终结符的操作来实现不同的跳转,而这个终结符(展望符)是什么就是通过继承来实现的。
LR(1)文法缺点是什么?它反正改正了移进规约冲突了。
LALR,将同心项目集合并,没问题吧,反正规约只是最后一步,之前的路径已经都区分开了。
但是,就不容易发现错误了,比如=和$,若后面不允许出现=呢?它会照样规约,但是会在之后出现错误,这样错误就不是很精准了,而且会向后延伸,但它与SLR是不一样的,它解决了移进规约冲突。
而且会产生规约-规约冲突!原因正是在于扩大了展望符集,添加了不该添加的展望符,那么它就不知道该用哪一个产生式进行规约了,如果有多个产生式的话。因此,LALR要求不允许产生规约-规约冲突,而LR(1)文法是没有规约-规约冲突的,因为具体到单个展望符的话就什么问题也没有了,如果还有问题的话那就是你本身语法设计不合理。
LALR是没有移进-规约冲突的,为什么呢?因为LR(1)文法是不会产生移进-规约冲突的,而LALR文法仅仅改动了规约部分,对于移进是没有任何影响的。LALR大小与LR(0),SLR的大小是相当的。LALR的分析能力低于LR了。
移进规约冲突和规约-规约冲突本质上都是bug级别的。
任何二义性的文法都不是LR的,因为会发现动作冲突。但没有二义性的文法不一定是SLR(或LR,LALR)的,这几个文法是自身的bug。
二义性文法转非二义性的文法,就要在多个选择中,选一个,就是这样。

例如这个LR(0)造二义性文法,有*号,根据运算符优先级,去别的节点,有加号,因为是左结合的(从左边开始计算,右结合就是从右边开始计算,例如=),因此先执行规约产生式E->E+E·,然后再移入加号
而这个,来了+号,无论如何也要先执行乘法规约。用优先级和结合性,就解决了移进-规约冲突,移进-移进冲突没有吧,这应该是低级的文法错误。在文法设计阶段就有的错误。
也就是说,通过优先级和结合性的判断,就可以魔改LR(0)的那一长串规约操作。比如说,能移进就移进,移进的优先级比较高,这样不就解决了移进-规约冲突了吗。这也是if语句所干的事情,也叫最近匹配原则。
错误恢复。
恐慌模式:找到这个出错的非终结符,然后丢弃多个输入,直到找到一个合法后继符,这样A就可以正常规约,虽然它的内容并不是对的,但是它把错误包裹起来了。
短语层次错误恢复:针对这个错误,构造合适的符号,从而满足A这个非终结符。这是一个构造的过程。
一旦你说,移进符根本就不是,表格中空白的部分,这时候直接转向错误处理例程,就是这样,因此短语层次错误恢复更好一点。根据不同情况,替换这个指针字符,为合理的字符,从而能继续运行下去,是不是。啊,就这样。既然能捕捉错误,什么不能干啊,是吧。每一种情况都是有具体环境的,具体问题具体分析不难。
举个例子:
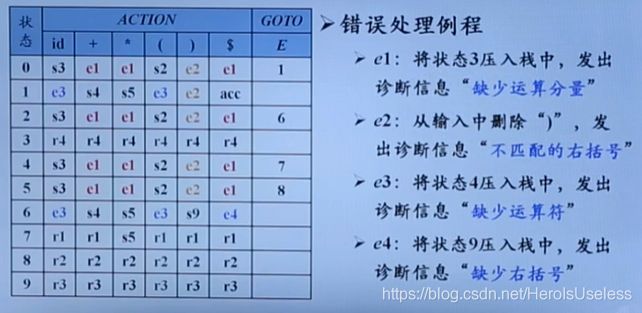
下面是之前很傻的时候学习的
————————————————————————————————————————————-
LR(0)文法要求文法的每一个LR(0)项目都不含有冲突的项目,移进-规约,规约-规约都没有,这个条件比较苛刻。对于大多数程序设计语言来说,一般都不能满足LR(0)文法的条件。移进冲突规约冲突都不能有。
对含有冲突的项目集向前查看一个输入符号的办法来解决冲突,这种分析法称为简单的LR分析法,即SLR(1)分析法。例如:
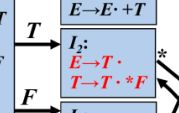
输入一个T到达I2后是该规约还是继续移入呢?如果向前看一个字符,前面不是空串就是*,那么就可以区分了对吧,这就是SLR。
关键是这个表还是没明白,都知道第一个式子至关重要,下面的都是上面的推出来的,下面的不重要,上面第一个叫做核,并不是一开始是全部都放进来,是一个闭包,求first集的那种,并不是全部,这样的话,第一个的确是核心,整个集都采取核的移进规约方式。它的关键之处在以后有用。
那么怎么判别是不是SLR呢?
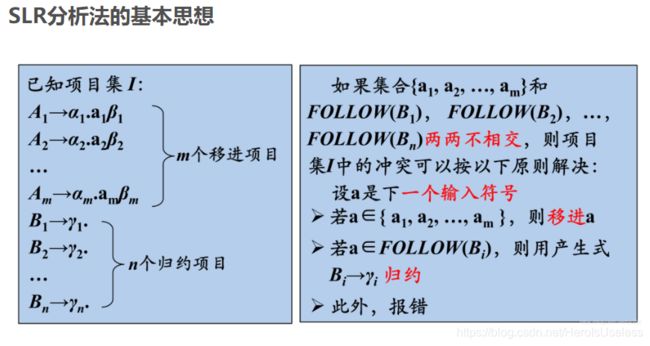
什么意思呢?这是为了解决分析动作冲突,同时都存在的情况下,到底是移入呢,还是规约。这里中间a代表的是向前看符号,而不是移进栈中了,如果是B的follow集的话,就用B->r的产生式规约,为什么呢?基本上还是只是进行分叉而已吧。
- SLR使用follow集来解决LR(0)的规约/移入冲突问题
- LR通过展望符预测来解决Follow集预测不准确的问题
- 而LR又存在将状态划分得过细,导致状态数过多的问题,因此又诞生了LALR,该算法剪除了LR中相同性质的状态,缩减了状态数,但是又带来了延迟报错的问题...
之所有有文法就是为了求一个自动机,这个自动机可以去掉多余的移入规约方法,只保留一个规范规约。
- 对于项`B->B·b`,如果looahead是b,就可以移进.
- 对于项`A->B·`,如果lookahead ∈ Follow(A),那么就可以归约.
因为自动机并不是说等串完了才会规约吧,如果是B·,而且后面的还不是follow集,那么就是出错的,因为不是移进就是规约的。
那么SLR(1)就可以避免移进-规约冲突。
存在两个可归约项,如何确定选择哪一个呢?例如:
A->c·
B->c·仍然是求A和B的follow集,如果是不一样的,那么还是可以区分的。一般的,终结符匹配在
- 可移入项的后继符号组成的集合(记为 next—set )
- 每个可归约项的Follow集(记为 Follow(X1)...Follow(Xn))
综上,SLR通过向前看一个终结符,通过查这个终结符在哪个Follow集中,能有效解决移进-规约冲突,能解决一部分规约-规约冲突。a可能同时归属多个集合的, 这种情况SLR无法作出唯一的选择
实际上,是a是如何到达这里的,将决定它后面能接什么, 而不是通过Follow判断,例如:
- 如果通过I3进入I6,则lookhead必须为=
- 如果通过I4进入I6,则lookhead必须为id
- 如果通过I9进入I6,则lookhead必须为$
就是这么个意思。事实上,一个归约项可接受的符号,是该项左侧非终结符的Follow集的子集. 换句话说,SLR把「可归约的情况」预测多了.
之所以SLR能解决移进规约冲突,是因为它就是为了解决冲突而设计的,通过Follow集已经足够能解决移进-规约冲突了。因为该移进还是该规约的时候,后面跟的终结符是不同的,为什么不同呢?因为移进规约用的是加点的方法,点加到最后就说明可以规约了为什么可以规约,因为那就是一个非终结符的全部了,自然是可以规约的,这里就是只要形成非终结符就马上规约,也就是说,一个非终结符的follow集与它本身所含有的没有交集。
等一下,什么是移进规约冲突?就是在同一个页框里有移进项和规约项,为什么会产生这种结果,先别管了想不通。反正能由follow集解决。
LR(1)就是加了一个展望符,这个展望符是SLR的follow集的精细化管理,而LALR文法就是LR(1)的精简。老师只是简单介绍了一下它。
可能下面就不讲了。。。