Java OOM问题如何排查
目录
什么是OOM
导致OOM问题的原因
排查手段
调优命令有哪些?JAVA虚拟机命令详解:
JAVA OOM问题排查记录
一、一个Java内存泄漏的排查案例
什么是OOM
OOM为out of memory的简称,来源于java.lang.OutOfMemoryError,指程序需要的内存空间大于系统分配的内存空间,OOM后果就是程序crash;可以通俗理解:程序申请内存过大,虚拟机无法满足,然后崩溃了。
导致OOM问题的原因
1、内存加载的数据量太大:一次性从数据库取太多数据;
2、集合类中有对对象的引用,使用后未清空,GC不能进行回收;
3、代码中存在循环产生过多的重复对象;
4、启动参数堆内存值小。
为什么会没有内存了呢?原因不外乎有两点:
1)分配的少了:比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
2)应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
内存泄露:申请使用完的内存没有释放,导致虚拟机不能再次使用该内存,此时这段内存就泄露了,因为申请者不用了,而又不能被虚拟机分配给别人用。
内存溢出:申请的内存超出了JVM能提供的内存大小,此时称之为溢出。
最常见的OOM情况有以下四种:
- java.lang.OutOfMemoryError: Java heap space ------>java堆内存溢出,此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。-----------重点是确认内存中的对象是否是必要的,先分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。-------------如果是内存泄漏,可进一步通过工具查看泄漏对象到GCRoots的引用链。于是就能找到泄漏对象是通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收。---------如果不存在泄漏,那就应该检查虚拟机的参数(-Xmx与-Xms)的设置是否适当。(堆大小可以通过虚拟机参数-Xms,-Xmx等修改)。
- java.lang.OutOfMemoryError: PermGen space 或 java.lang.OutOfMemoryError:MetaSpace ------>java方法区,(java8 元空间)溢出了,---------------方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。也有可能是方法区中保存的class对象没有被及时回收掉或者class信息占用的内存超过了我们配置。---------------一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。此种情况可以通过更改方法区的大小来解决,使用类似-XX:PermSize=64m -XX:MaxPermSize=256m的形式修改。另外,过多的常量尤其是字符串也会导致方法区溢出。
- java.lang.StackOverflowError ------> 不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小。
- 虚拟机栈和本地方法栈溢出
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常
排查手段
一般手段是:先通过内存映像工具对Dump出来的堆转储快照进行分析,重点是确认内存中的对象是否是必要的,也就是要先分清楚到底是出现了内存泄漏还是内存溢出。
-
如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链。这样就能够找到泄漏的对象是通过怎么样的路径与GC Roots相关联的导致垃圾回收机制无法将其回收。掌握了泄漏对象的类信息和GC Roots引用链的信息,就可以比较准确地定位泄漏代码的位置。
-
如果不存在泄漏,那么就是内存中的对象确实必须存活着,那么此时就需要通过虚拟机的堆参数( -Xmx和-Xms)来适当调大参数;从代码上检查是否存在某些对象存活时间过长、持有时间过长的情况,尝试减少运行时内存的消耗。
调优命令有哪些?JAVA虚拟机命令详解:

1、查看 Java进程------------jps 命令
命令jps类似于linux下的ps, 但它只用于列出Java的进程。
注意:jps命令类似于ps命今, 但是它只列出系统中所有的Java应用程序。 通过JPS命令可以方便地查看Java进程的启动类、 传入参数和Java虚拟机参数等信息。
2、查看虚拟机运行时信息----------jstat命令
jstat是个可以用于观察Java应用程序运行时相关信息的工具。 它的功能非常强大, 可以通过它查看堆信息的详细情况。 jstat -gc 2972
jstat命令格式为: jstat [ option vmid [interval[s|ms] [count]] ]
使用命令如下: jstat -gcutil 20954 1000 意思是每1000毫秒查询一次,一直查。
gcutil的意思是已使用空间站总空间的百分比。
结果如下图:

3、导出堆到文件------jmap 命令
一个多功能的命令,它可以生成Java程序的堆Dump文件, 也可以查看堆内对象实例的统计信息、 查看ClassLoader的信息以及finalizer队列。
下例使用jmap生成PID为2972的Java程序的对象统计信息, 并输出到 s.txt文件中。 jmap -histo 2972 >c:\s.txt
输出文件有如下结构:
jmap另一个更为重要的功能是得到Java程序的当前堆快照:
 4、MAT工具----内存泄漏分析工具
4、MAT工具----内存泄漏分析工具
- Histogram可以列出内存中的对象,对象的个数以及大小。
- Dominator Tree可以列出那个线程,以及线程下面的那些对象占用的空间。
- Top consumers通过图形列出最大的object。
- Leak Suspects通过MAT自动分析泄漏的原因----泄露嫌疑分析
JAVA OOM问题排查记录
一、一个Java内存泄漏的排查案例
某个业务系统在一段时间突然变慢,我们怀疑是因为出现内存泄露问题导致的,于是踏上排查之路。
最常见的场景,假设你把new完的对象放在队列或者Map里,然后这个定时任务不停地添加这种对象,那最后肯定会OOM的。GC只能回收那些没有被引用的对象,而如果你个个都引用并且并不释放(方法结束或者主动置为null,或者将存放的集合销毁,没有设置过期时间),那再无敌的GC也帮不了你。所以不要把所有希望都寄托在GC上面。
concurrenthashmap增加缓存删除设计
实际开发中有个定时任务的应用,运行一段时间后就会OOM,通过jvm的各种监控来排查OOM的原因,特此记录在这里。
2.1 确定频繁Full GC现象
首先通过“虚拟机进程状况工具:jps”找出正在运行的虚拟机进程,最主要是找出这个进程在本地虚拟机的唯一ID(LVMID,Local Virtual Machine Identifier),因为在后面的排查过程中都是需要这个LVMID来确定要监控的是哪一个虚拟机进程。 同时,对于本地虚拟机进程来说,LVMID与操作系统的进程ID(PID,Process Identifier)是一致的,使用Windows的任务管理器或Unix的ps命令也可以查询到虚拟机进程的LVMID。
jps命令格式为: jps [ options ] [ hostid ]
使用命令如下: 使用jps:jps -l 使用ps:ps aux | grep tomat
找到你需要监控的ID(假设为20954),再利用“虚拟机统计信息监视工具:jstat”监视虚拟机各种运行状态信息。
jstat命令格式为: jstat [ option vmid [interval[s|ms] [count]] ]
使用命令如下: jstat -gcutil 20954 1000 意思是每1000毫秒查询一次,一直查。
gcutil的意思是已使用空间站总空间的百分比。 结果如下图:
 jstat执行结果
jstat执行结果
查询结果表明:这台服务器的新生代Eden区(E,表示Eden)使用了28.30%(最后)的空间,两个Survivor区(S0、S1,表示Survivor0、Survivor1)分别是0和8.93%,老年代(O,表示Old)使用了87.33%。程序运行以来共发生Minor GC(YGC,表示Young GC)101次,总耗时1.961秒,发生Full GC(FGC,表示Full GC)7次,Full GC总耗时3.022秒,总的耗时(GCT,表示GC Time)为4.983秒。
2.2 找出导致频繁Full GC的原因
分析方法通常有两种:
1)把堆dump下来再用MAT等工具进行分析,但dump堆要花较长的时间,并且文件巨大,再从服务器上拖回本地导入工具,这个过程有些折腾,不到万不得已最好别这么干。
2)更轻量级的在线分析,使用“Java内存影像工具:jmap”生成堆转储快照(一般称为headdump或dump文件)。
jmap命令格式: jmap [ option ] vmid
使用命令如下: jmap -histo:live 20954 查看存活的对象情况,如下图所示:

存活对象
按照一位IT友的说法,数据不正常,十有八九就是泄露的。在我这个图上对象还是挺正常的。
我在网上找了一位博友的不正常数据,如下:
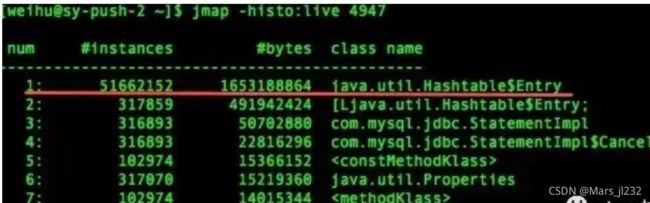
可以看出HashTable中的元素有5000多万,占用内存大约1.5G的样子。这肯定不正常。
2.3 定位到代码
定位带代码,有很多种方法,比如前面提到的通过MAT查看Histogram即可找出是哪块代码.
2.4、jmap -dump:format=b,file=heapdump.bin pid
生成堆转储快照dump文件
sh-4.2# jmap -dump:format=b,file=heapdump.bin 10
Dumping heap to /a-one/bin/heapdump.bin ...
Heap dump file created
2.5、sz heapdump.bin
下载导出的堆快照dump文件,导入到MAT工具中
- Histogram可以列出内存中的对象,对象的个数以及大小。
- Dominator Tree可以列出那个线程,以及线程下面的那些对象占用的空间。
- Top consumers通过图形列出最大的object。
- Leak Suspects通过MA自动分析泄漏的原因