CVPR2020 | 显著性目标检测,多尺度信息相互融合
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文是收录于CVPR2020的有关显著性目标检测的文章,主要的创新点在特征聚合操作,可以迁移到其他需要融合深层和浅层特征点的任务中。代码已开源并在不断维护中,值得学习!
论文地址:https://arxiv.org/pdf/2007.09062.pdf
代码地址:https://github.com/lartpang/MINet
基于深度学习的显著性目标检测方法取得了很大的进步,然而,物体的尺度变化和类别的未知一直是显著性目标检测任务的挑战,这些与多层次和多尺度特征的利用紧密相关。在本文中,提出了聚合交互模块来聚合相邻层的特征,由于整个工程中仅使用较小的上/下采样率即可因此引入的噪声较少。为了从聚合特征中获得更有效的多尺度特征,本文将自交互模块(self-interaction modules )嵌入每个解码器单元中。此外,由尺度变化引起的类不平衡问题削弱了二元交叉熵损失的影响,并导致预测的空间不一致。因此,本文利用一致性增强的损失来突出显示前后差异,并保留类内一致性。最后,在五个基准数据集上的实验结果表明,与23种最新方法相比,本文方法无需进行任何后处理过程,就具有良好的性能。
简介
显著性物体检测(Salient object detection ,SOD)旨在区分视觉上最明显的区域。在数据驱动的深度学习方法的帮助下,它正在快速增长,并已应用于许多计算机视觉领域,例如视觉跟踪,图像检索,非照片级渲染,4D显著性检测,无参考的合成图像质量评估等。虽然目前已经取得了很大的进展,但仍有两个问题需要注意,一是如何从尺度变化的数据中提取更多的有效信息,二是如何提高这种情况下预测的空间一致性。由于显著区域的尺度不同,基于CNN的方法由于重复的子采样缺乏必要的细节信息,难以持续准确地分割不同尺度的突出物体(图1)。另外,考虑到卷积运算固有的局部性和交叉熵函数的像素级特征,很难实现物体的均匀显著性提取。

对于第一个问题,现有方法的主要解决方法是逐层整合较浅的特征。有些方法通过将编码器中相应层次的特征连接到解码器中(图2(a,c,e))。单层特征只能表征特定尺度的信息, 在自上而下的路径中,由于深层特征的不断积累,浅层特征的细节表示能力被削弱。为了利用多层次特征,一些方法将多层次的特征以完全连接的方式或启发式的方式进行整合(图2(b,f,g))。然而, 过多的特征整合和不同分辨率之间缺乏平衡, 容易导致计算成本高、噪声多、融合困难, 从而扰乱了后续自上而下路径的信息恢复。此外,空间金字塔池化模块(ASPP)和金字塔池化模块(PPM)被用于提取多尺度的上下文感知特征,并对单层特征表示进行了改进。然而,现有的方法通常是在编码器后面配备这些模块,这就导致它们的网络由于顶层特征的低分辨率的限制而错过了许多必要的细节。

图2.不同特征融合架构。绿色区块、橙色区块和灰色区块分别表示编码器、过渡层和解码器中不同的卷积块。左列:编码器与过渡层之间的连接模式;右列:过渡层与解码器之间的连接模式。 (a,e)FCN;(b)Amulet;(c)BMPM;(d)AIMs;(f)DSS;(g)DGRL;(h)SIMs。
受Zhang等提出的相互学习思想(《 Deep mutual learning》)的启发,本文提出了一种聚合交互策略(aggregated interaction strategy,AIM),以更好地利用多层次特征,避免大分辨率差异造成的特征融合干扰(图2(d)),并且通过协同学习知识引导,有效整合相邻分辨率的上下文信息。为了进一步从提取的特征中获得丰富的尺度特异性信息,本文还设计了一个自交互模块(SIM)(图2(h))。两个不同分辨率的交互分支被训练成从单个卷积块中学习多尺度特征, AIM和SIM有效地提高了SOD任务中处理尺度变化的能力。
与《 Deep mutual learning》中的设定不同,在这两个模块中,相互学习机制被纳入到特征学习中。每一个分支都可以通过交互学习更灵活地整合来自其他分辨率的信息。在AIM和SIM中,主分支(图4中的B1和图5中的B0)由辅助分支补充,其分辨能力得到了进一步的增强。此外,多尺度的问题也会导致数据集中前景和背景区域之间的严重失衡,因此在训练阶段引入了一个一致性增强损失(CEL),它对物体的尺度不敏感。同时,CEL可以更好地处理空间一致性问题,在不需要额外参数的情况下均匀地突出突出区域,因为其梯度具有保持类内一致性和扩大类间差异的特点。
本文的贡献可概括为三个方面:
1、所提出的MINet能够有效地应对SOD任务中的挑战。聚合交互模块可以通过相互学习的方式有效地利用相邻层的特征,而自我交互模块则使网络可以自适应地从数据中提取多尺度信息,并更好地应对尺度变化。
2、提出增强损失函数,以协助模型统一突出显示整个显著区域,并更好地处理由各种比例的物体引起的前、后区域之间的像素不平衡问题,而无需任何后处理或额外处理。
3、本文的方法与五个数据集上的23种最先进的SOD方法进行了比较。在不同的评估指标下,它都能实现最佳性能。此外,该模型在GPU上具有35 FPS的正向推理速度。
本文的方法
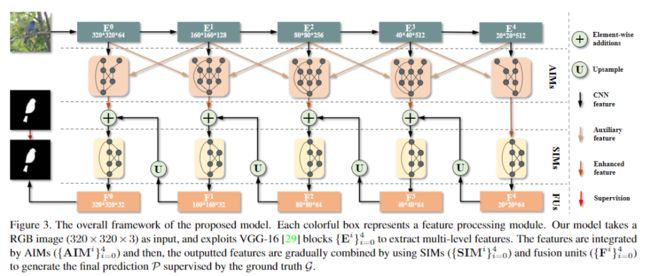
从上图可以看出,本文的模型是基于FCN架构,以预先训练的VGG-16 或ResNet-50作为主干网络,两者都只保留特征提取网络。具体来说,删除了最后一个最大池化层保留最后卷积层的细节。因此,对于VGG-16,下采样到1/16,对于ResNet-50,下采样到1/32。利用主干网络提取多层次的特征,然后每个AIM(图4)利用相邻层的特征作为输入,有效地利用多层次的信息,为当前的分辨率提供更多的相关和有效的补充。接下来,在解码器中,每一个SIM(图5)后面都有一个FU,它是卷积层、批归一化层和ReLU层的组合。SIM可以自适应地从特定的层次中提取多尺度信息,该信息由卷积层、批量归一化层和ReLU层组合而成,这些信息被FU进一步整合并反馈到浅层。此外,引入一致性增强损失作为辅助损失来监督训练阶段。
1 Aggregate Interaction Module
在特征提取网络中,不同level的卷积层对应于不同程度的特征抽象。多层特征聚合可以增强不同分辨率特征的表示能力:1)在浅层,可以进一步增强详细信息,抑制噪声;2)在中间层中,同时考虑了语义信息和详细信息,可以根据网络本身的需求自适应地调整特征中不同抽象信息的比例,从而实现了更灵活的特征利用;3)在顶层,考虑相邻的分辨率时,可以挖掘出更丰富的语义信息。本文提出了聚合交互模块(AIM)(图4),以通过交互式学习策略聚合特征。

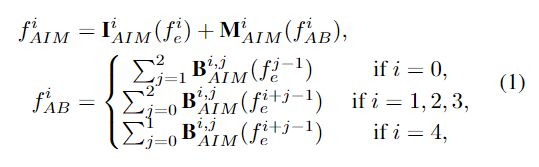
2 Self-Interaction Module
自交互模块(SIMs)的细节可以在图5中看到。同样,本文也在SIM中应用了变换-交互-融合的策略。具体来说,输入特征的分辨率和维度首先被卷积层降低,在每一个分支中,SIM都会执行转换-交互-融合策略。在每一个分支中,SIM都会进行一个初始的变换,以适应下面的交互操作:对低分辨率特征进行上采样,对高分辨率特征进行子采样,使其与其他分支的特征具有相同的分辨率。高、低分辨率特征与不同通道数的交互操作,可以获得大量的不同尺度的知识,并以较低的参数量化来主要保持高分辨率信息。为了便于优化,还采用了残差连接,如图5所示。在经过上采样、归一化和非线性处理后,采用FU对SIM和残差支路的双路径进行处理,将SIM集成到解码器中,使得网络在训练阶段能够自适应地处理不同样本的尺度变化。


3 Consistency-Enhanced Loss
在SOD任务中,广泛使用的二进制交叉熵函数在整个批次中累积了每个像素的损失,并且没有考虑像素间的关系,这无法明确地促使模型尽可能平滑地突出前景区域并很好地处理样本不平衡问题。为此,提出了一致性增强损失(CEL)。首先,最终预测的计算如下:
![]()
为了解决各种尺度引起的前/后台失衡问题,损失函数至少需要满足两个要求:1)它比背景更多地关注前景,而对象尺度上的差异并不能引起广泛的影响。计算的损失的波动;2)当预测的前景区域与地面真实区域完全不相交时,应该有最大的惩罚,基于这两点,我们考虑区域之间的拓扑关系来定义CEL,如下所示:
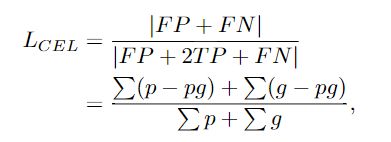
为了比较LCEL和LBCEL,分析了它们直接作用于网络预测的梯度。它们微分表达如下:

可以看出,∂LBCEL/∂依赖于单个位置的预测。而∂LCEL/∂p与预测P和标签值G中的所有像素有关。因此,CEL被认为对预测结果施加全局约束,这可以产生更有效的梯度传播。在上面等式中,除了分子项1-2是位置特定的,其他项是图像特定的。并且该分子与二元 ground truth密切相关,其结果是,类间导数具有较大的差异,而类内导数则相对一致。这有几个优点:1)确保有足够大的梯度在以后的训练阶段驱动网络;2)在一定程度上有助于解决类内不一致和类间不相容问题,从而使显着对象的预测边界更加清晰。最后,总损失函数可以写成:

实验与结果
数据集:DUTS 、DUT-OMRON 、ECSSD、HKU-IS 、PASCAL-S
实验细节:50 epochs with a mini-batch of 4 on an NVIDIA GTX 1080 Ti GPU
实验结果
1、对比实验
定量比较
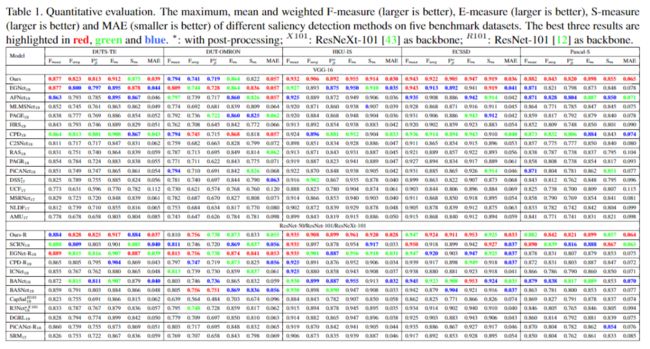
定性评估

2、消融实验
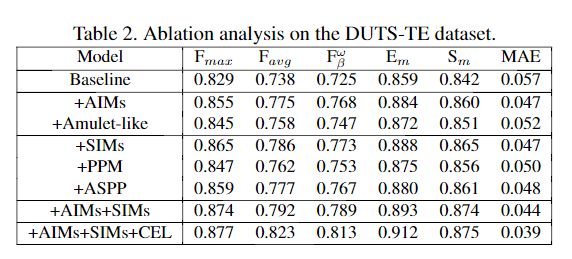

更多细节可参考论文原文。
![]()

