Deep Learning Networks: CNN-, RNN-
* 没有详细展开,只是做一个整理
* 持续整理中
年份表:
| year | Bases | CNN- | RNN- | 其他 |
| 1974 | BP | |||
| 1986 | JordanNet | |||
| 1989 | UAT | |||
| 1990 | ElmanNet | |||
| 1993 | SN | |||
| 1997 | BRNN LSTM |
|||
| 1998 | LeNet5 | |||
| 2010 | ReLU | |||
| 2012 | Dropout DA |
AlexNet | ||
| 2014 | R-CNN SPPNet NIN |
GRU | GAN Attention |
|
| 2015 | BN |
VGG Fast R-CNN ResNet FCN |
||
| 2016 | Faster R-CNN | |||
| 2017 | FPN | Self-Attention | ||
| 2018 | Mask R-CNN |
一、Bases
基本思想:BP、UAT、ReLU、Dropout、DA、BN
一些比较经典的思路。
BP
(error) Back Propagation (误差)反向传播算法
1974
先正向传播算出误差,再将误差反向由输出层向输入层传播,利用梯度下降法(or else)调整权重。
UAT
Universal Approximation Theorem 万能逼近定理/通用近似定理
1989
如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以足够高精度来逼近任意一个在 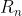 的紧子集 (Compact subset) 上的连续函数。
的紧子集 (Compact subset) 上的连续函数。
ReLU
Rectified Linear Units 线性整流函数
2010 ReLU
常用作激活函数,特点:
- 没有梯度消失的问题(导数的取值只有0/1)
- 单侧抑制(导数在负半区为0),增加稀疏程度,防止过拟合
- 公式简单,计算快
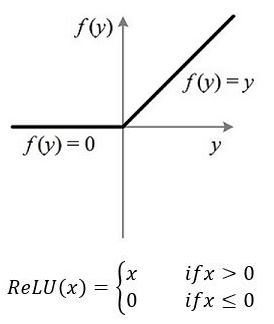
Dropout
Dropout —— 避免模型过拟合,增加泛化能力的trick
2012
在网络训练的过程中,按照一定的概率,暂时丢弃部分神经元。一般用于全连接层。可消除/减弱神经元间的联合适应性。后来出现很多变种,可丢弃神经元、断开连接、去掉部分特征等。
DA
Data Augmentation
数据增强 —— 用于防止过拟合
2012 被用于深度学习(AlexNet)?(不确定)
当训练集较小的时候,可以通过对原始数据集进行修改,生成新的数据。
常见方法有(针对图像):
- 修改原始数据:随机旋转、随机裁剪/缩放、翻转(水平/竖直)、色彩抖动(改变亮度、饱和度、对比度)
- 修改数据质量:添加噪声
- 调整数据分布:当数据不平衡时,对原始数据做新的采样
BN
Batch Normalization 批标准化
2015
添加在激活函数之前,避免大批数据提前进入饱和阶段,过早发生梯度消失。

二、CNN-
LeNet5、AlexNet、R-CNN、SPPNet、NIN、VGG、Fast R-CNN、ResNet、FCN、Faster R-CNN、FPN、Mask R-CNN
| 网络 | 基本结构 | 简化版 | 用途 | |
| CNN基本框架系列 | LeNet5 | c5 - p - c5 - p - c5 - {FC}*2 | 3*conv + 2*FC | 识别 |
| AlexNet | c11 - p - c5 - p - {c3}*3 - p - {FC}*3 | 5*conv + 3*FC | 识别 | |
| NIN | {mlpconv - p}*N - GAP | mlpconv + p + GAP | 识别 | |
| VGG16 | {{c3}*2 - p }*2 - {{c3}*3 - p}*3 - {FC}*3 | 16*conv + 3*FC | 识别 | |
| ResNet | {[c3(+ReLU) - c3] + input} - ReLU | conv block + shortcut | 识别 | |
| FCN | all conv(+p) + deconv + softmax | conv block + deconv | 语义分割 | |
| R-CNN系列 | R-CNN | SS + AlexNet + SVM + BB | 检测 | |
| SPPNet | AlexNet + SS + SPP + SVM + BB | 检测 | ||
| Fast R-CNN | VGG16 + SS + RoI + SVM&BB | 检测 | ||
| Faster R-CNN | VGG16 + RPN + RoI + SVM&BB | 检测 | ||
| Mask R-CNN | VGG16 + RPN + RoIAlign + SVM&BB&(deconv + softmax) | Faster R-CNN + FCN | 实例分割 |
* 备注:
p: pooling
c5:卷积层,卷积核大小5*5(默认省略激活层,除特殊情况,如ResNet)
FC:全连接层
{}*N:表示同样的结构块,出现N次
CNN
Convolutional Neural Network 卷积神经网络
图像识别-特征提取
2012年ImageNet,使用CNN的AlexNet取得冠军,之后CNN被广泛应用于图像识别-特征提取。
(第一次完整出现卷积层、激活层、池化层,是1998年的 LeNet5,用于识别手写数字0-9)
基本结构:卷积层 + 激活层 + 池化层
- 卷积层:在输入图像上(矩阵),移动卷积核,图像上对应位置的矩阵和卷积核作卷积计算(实质上是一个二维滤波过程,图像可以是三维的,但滤波操作是二维的,因为卷积核只能在x,y方向上移动);
- 激活层:映射卷积操作后的特征矩阵,多为非线性映射(卷积层为线性计算,无法处理非线性问题,因此需要激活层引入非线性因素);
- 池化层:降采样,压缩特征,可以:简化计算、防止过拟合、扩大感受野。
不同的卷积核会提取出不同的特征,并直接影响效果,可修改的参数:
- 卷积核的大小,(现)一般采用3X3;
- 卷积核的形状,即各个位置上的数字(卷积操作实际上一个加权平均的过程,体现周边数据对中心数据的影响)。
卷积操作的结果:强调边缘特征,弱化非边缘特征。

LeNet5和AlexNet
LeNet5: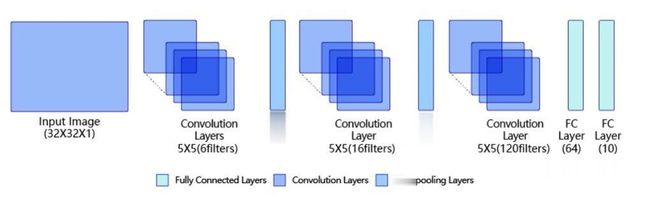
AlexNet:

LeNet5和AlexNet的基本框架都是由卷积层、激活层、池化层组成的。
与LeNet5相比,AlexNet有这些特点:
- 层数更深,LeNet5有3层卷积层,AlexNet有5层——习得更深度的特征
- ReLU,使用ReLU代替Sigmod作为激活函数——解决梯度消失问题
- Dropout,在全连接层采用Dropout技术——避免过拟合
- 最大池化,代替平均池化——避免模糊化
- 数据增强,使用随机裁剪+翻转——避免大网络出现过拟合
- 多GPU训练,将网络分布在两个GPU上并行计算——提高网络规模的上限
- LRN(Local Response Normalization),与Dropout效果类似,加在激活函数之后避免过拟合,现在用的很少,详细的就不写了——避免过拟合
* 可以看到,有很多避免过拟合的操作。普遍来说,增大网络,会容易引入降低模型泛化能力的风险。
R-CNN
Regions with CNN features R-CNN
目标检测
2014,用CNN做目标检测 —— Localization + Recognition
基本结构:SS + AlexNet + SVM + BB
详细地:Selective Search选择候选区域 + AlexNet提取特征 + SVM分类器 + Bounding Box回归产生检测框
步骤:
- 提取候选区:给定一张图片,用SS在图上选取2000个候选区域。
- 提取特征:对于每个区域,用CNN(AlexNet)提取特征。利用在其他数据集上训练好的CNN,在当前数据集上微调,得到所需的模型。
- 判断类别:用分类器(SVM)判断区域类别,需要针对每一个类别训练一个分类器。
- 确定检测框:按照识别结果将候选区域分组,对相同类别的候选框进行回归。
* 将分类和检测分为了两个步骤(实际上两者之间是有联系的,例如:提高检测框的精度,分类的置信度也会提高)。
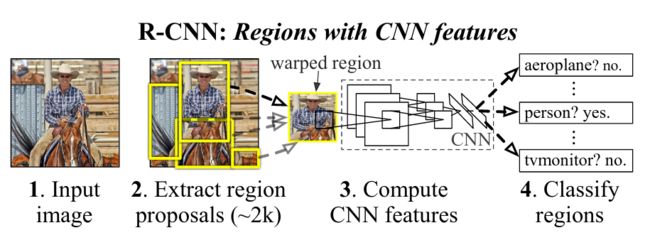
特点:
- 体现了CNN在目标检测领域的作用
- 迁移学习的思想,在ImageNet(大数据集,1200w+张图片,1000+类别)上训练CNN模型,在VOC(小数据集,2w+张图片,21个类别)上微调模型
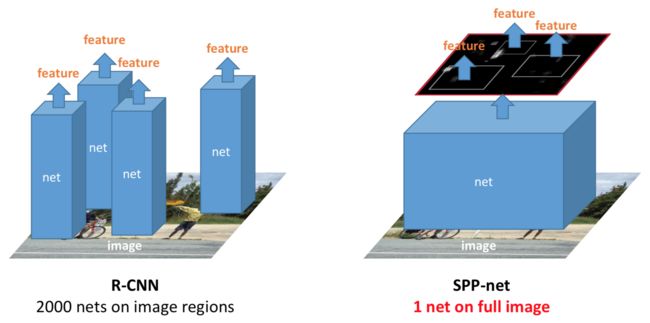
SPPNet
Spatial Pyramid Pooling 空间金字塔池化 SPPNet
目标检测
2014,基于R-CNN的改进,改进结果:降低耗时、解决不同尺寸候选框resize时的信息丢失和变形的问题。与R-CNN相比,准确度近似(在不同类别上各有优劣),训练速度快了3倍,测试速度快了10-100倍。
- R-CNN的耗时问题:每个候选区(2000个)都需要提取特征,实际上候选区之间会有很多重合的部分(Selective Search导致),会对同一个区域重复提取特征
- 解决不同尺寸候选框resize时的信息丢失和变形的问题:生成2000个候选区时它们的尺寸并不相同,在使用CNN提取特征之前会先resize成相同的尺寸(因为CNN必须固定输入尺寸),而resize(crop/wrap)的过程可能会扭曲原始信息。(CNN必须固定输入尺寸,因为:卷积操作可以接受任意尺寸的输入,但全连接层可学习的参数个数是固定的(与最后一个卷积层的输出尺寸有关)。全连接层的计算过程可以表示为
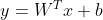 ,如果x的尺寸发生变化,
,如果x的尺寸发生变化,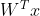 这一步将无法进行。)
这一步将无法进行。)
基本结构:AlexNet + SS + SPP + SVM + BB
步骤:
- 提取特征:整张图送入CNN(AlexNet),得到1个feature map(最后一个卷积层的输出)
- 截取候选区特征:
- SS(Selective Search)在原图上获得2000个候选区域,记录候选区域框的位置信息{x,y,w,h}
- 根据位置信息,在feature map(第1步得到的)中直接截取区域特征
- 利用SPP(Spatial Pyramid Pooling)统一候选区域的feature map尺寸
- 经过全连接层输出各区域的一维特征向量
- 判断类别(SVM)
- 确定检测框
* SPPNet的具体优化操作(2.2,2.3),主要体现在CNN的最后一个卷积块之后,全连接层之前。
SPP(Spatial Pyramid Pooling)
作用:可以接受不同尺寸的feature map作为输入,转换成固定尺寸的feature map输出
步骤:
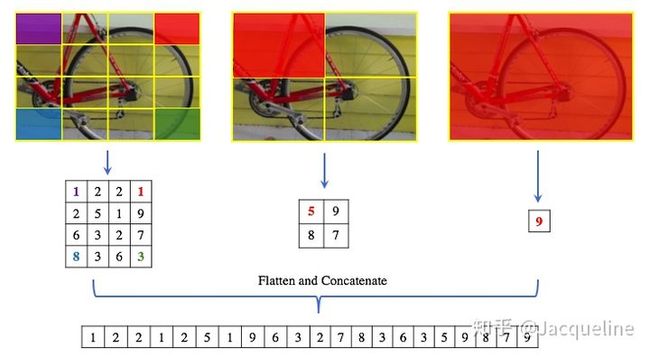
- 将同一个feature map按照不同的方式切割。如原文中提到的切割成1*1,2*2,3*3,6*6,即将feature map复制成相同的四份,每份分别切割为大小相同的1、4、6、36块(1代表直接保留原始feature map)。
- 针对每一个小块使用max pooling,所以会得到50个特征(1+4+6+36)
- 50个特征flatten之后得到固定尺寸(1*50)的输出。
下图是一个例子(按照4*4,2*2,1*1的方式切割,最后得到一个尺寸为1*21(16+4+1)的输出):
与R-CNN相比,SPPNet的改进为:
- 整图提取一个feature map,直接在整图的feature map中截取区域的feature map
- 在获得不同尺寸的区域feature map之后,全连接层之前,加入一个SPP统一尺寸
NIN
Network in Network
2014 NIN
目标识别
对AlexNet的改进,效果:增强了模型的非线性;减少参数,降低过拟合的风险,也提高了速度
AlexNet的问题:
- 卷积操作是线性变化:线性变化无法提取到非线性特征(所以传统卷积层后面都会加上一个激活函数来增加非线性)。卷积核可以认为是一种广义线性模型Generalized Linear Model(GLM),GLM对数据的抽象能力比较弱(为提取到更抽象的特征,需要堆叠多个卷积层)。
- 全连接层参数多,容易过拟合:假设全连接层(FC)的输入数据尺寸为x*x*N,输出尺寸为1*M,即需要有M个神经元,每个神经元的参数个数为x*x*N(用一个x*x*N的卷积核去滤波),参数总数为x*x*N*M。(往往会在全连接层使用dropout来避免过拟合)
改进内容:
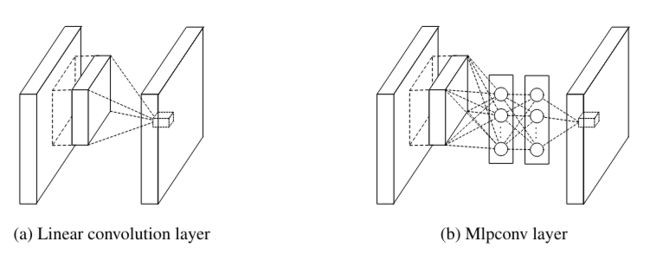
- 用一个非线性的micro network,如MLP(Multilayer Perceptron),来代替传统卷积操作,增加非线性
- 用GAP(Global Average Pooling)代替全连接层,减少参数
结构:
- 卷积层+激活:mlpconv
- 池化层:max pooling
全连接层GAP
具体地:
1. mlpconv
用mlp代替卷积核,在图像上滑动。
为什么用mlp:mlp可以通过BP来更新参数,使得整个网络参数更新的过程时连续的。
mlp的结构:输入 - 隐藏层(全连接)- 输出 (隐藏层可以是多层的)
- 每个全连接层都是在执行一次线性操作
- 每个全连接层后面接一个激活层(ReLU)
- 第一个全连接层等效于x*x的卷积层(输入为尺寸为x*x*N,输出尺寸为1*1*M),后面的全连接层都等效于1*1的卷积层(输入尺寸为1*1*P,输出尺寸为1*1*Q)
- 一个mlpconv等效于:一个x*x的卷积层,再级联多个1*1的卷积层
每个全连接层后都加了一个ReLU,所以mlpconv与conv+ReLU相比,具有更强的非线性。
2. GAP
用GAP代替全连接层。
GAP输入数据的通道数等于类别数。假设有N个目标类别,输入数据的尺寸就应该为x*x*N,即有N个大小为x*x的feature map。对每个feature map做average pooling,输出一个1*N的向量。
VGG
出自牛津大学计算视觉组Visual Geometry Group和谷歌DeepMind团队 VGG
目标识别
论文发表于2015,是2014ILSVRC的亚军(冠军是GoogLeNet,VGG可移植性更好,使用更广泛)
VGG有6种模型(为探究网络深度对分类精度的影响,作者使用6组模型进行试验),现在常说的VGG指的是VGG16——13个conv+3个FC,即下图中的D(E即VGG19——16个conv+3个Fc)
各种VGG的结构:
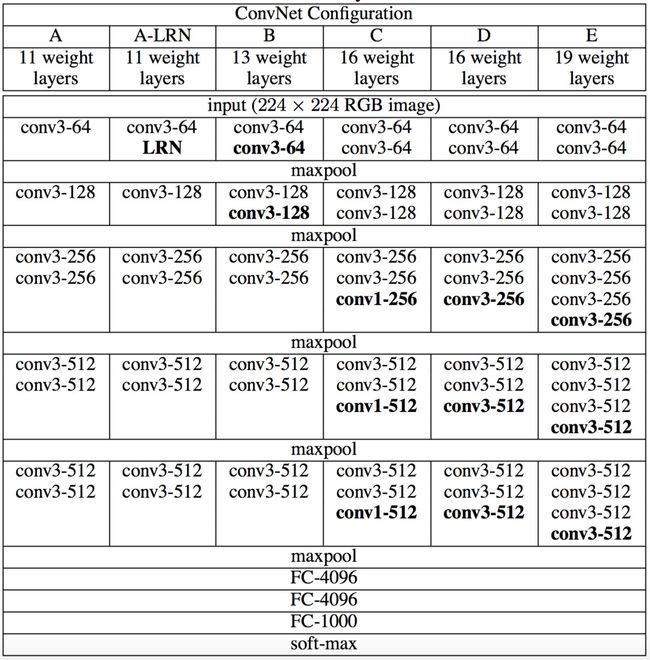
* conv3-512,代表该层有512个尺寸为3*3的卷积核
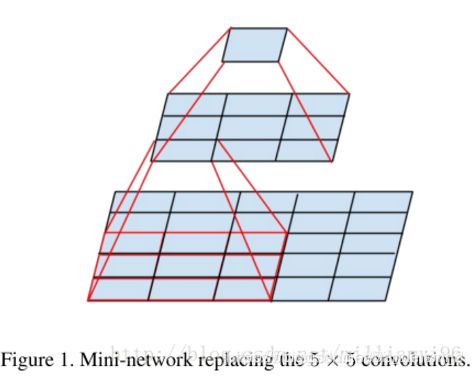
VGG使用卷积核都很小。用2个连续的3*3的卷积层代替一个5*5的卷积层,用3个连续的3*3的卷积层代替一个7*7的卷积层。相同感受野,参数更少:
- 2个连续的N通道的3*3的卷积层的参数个数:2*N*(3*3) = 18*N
- 1个N通道的5*5的卷积层的参数个数:N*(5*5) = 25*N
下图解释了为什么“可以用2个连续的3*3的卷积层代替一个5*5的卷积层”:
特点:
- 结构简洁,3*3的卷积层+最大池化
- (感受野相同时,)用多个小的卷积层实现更好的效果:参数更少、非线性更强(每个小卷积层后面都会加上一个非线性激活函数)
- 验证了增加网络深度可以提升效果(根据原文中的实验结果,VGG19效果最好)
- 计算成本很大,VGG16有1.3亿个参数
VGG相对于AlexNet的改进:
- 用多个小的卷积层代替一个大的卷积层(大小指卷积核的尺寸)——增加了网络深度
Fast R-CNN
目标检测
2015,用于解决R-CNN计算耗时长、内存开销大的问题 Fast R-CNN
基于R-CNN框架,参考SPPNet的优化思路:
- 与R-CNN相比,准确率更高,训练速度快了9倍,测试速度快了213倍;
- 与SPPnet相比,准确率更高,训练速度快了3倍,测试速度快了10倍。
R-CNN存在的问题(后面两个问题,SPPNet也存在):
- 耗时长(SPPNet中有解释)
- 内存开销大:训练分类器时,需要大量的特征作为输入,CNN提取的特征需要先保存下来,再提供给SVM作为训练数据
- 训练分多步:选择候选框、特征提取、分类、回归候选框,都是独立的步骤,没有利用它们之间的联系
基本结构:VGG16 + SS + RoI + SVM&BB
步骤:
- 提取特征:整张图送入VGG16,得到一个feature map
- 截取候选区域特征:
- SS生成候选区域,记录位置信息{x,y,w,h};
- 根据位置信息在原图的feature map上截出候选区域的feature map;
- 对不同尺寸的feature map进行RoI(Region of Interest)池化,生成相同尺寸的feature;
- 送入全连接层
- 同时输出分类结果和检测框的位置:分类结果为一个长度为1*(k+1)的向量(k+1:k个目标类别+背景),表示当前区域属于各个类别的概率
训练模型时的Loss:分类error+检测框的error,一起回传。
RoI(Region of Interest) Pooling
作用:可以接受不同尺寸的feature map作为输入,转换成固定尺寸的feature map输出(与SPP效果类似,可以看作是SPP的简化版)。
步骤(假设输出尺寸指定为n*n):
- 将输入的feature map切割为n*n份,每份的大小近似(不能整除的时候,每份的尺寸可以不同)
- 对每一小份作max pooling,得到n*n个特征
- flatten
eg:
左下角5*7的矩形框为候选区域,如果指定输出尺寸为2*2,可以作如下分割:纵向(5)分为2和3;横向(7)分为3和4
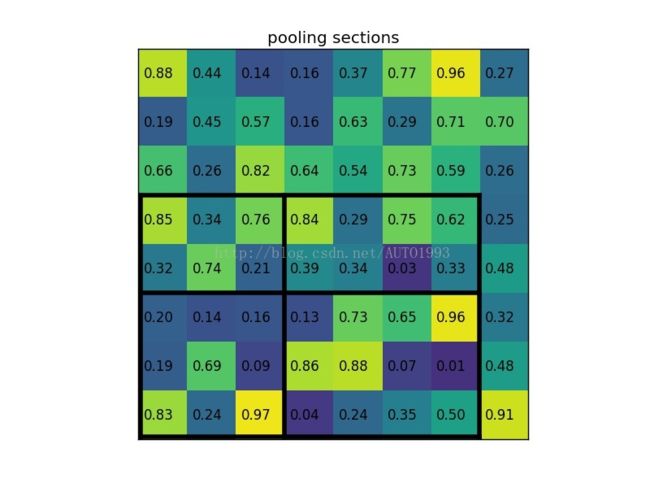
与SPPNet和R-CNN相比,Fast R-CNN具有更易于学习的特点。
SPPNet提取特征时,只能更新SPP层之后的参数,无法难以更新SPP层之前的卷积层参数。R-CNN也是如此,只能难以更新卷积层之后的参数(是更新参数的开销比较大,效率低,而不是无法更新!!)。原因:
- R-CNN:与挑选样本的方式有关。训练分类器时,一个batch内的样本包含多张不同图片的候选区域——会将来自不同图片的候选区域放在一起,打散后均匀采样。由于反向传播时需要用到正向传播的数据,因此想要更新卷积层的参数,需要先保存每张输入图片在各卷积层的数据,这个数据量太大了。(R-CNN是先划分候选区域,再将候选区域图片送入CNN,因此每个候选区域的各层卷积结果都需要保存)
- SPPNet:1.挑选样本的方式与R-CNN相同;2.(个人看法)与SPP的分割方式有关。尤其是1*1分割,即直接对整张图片作max pooling时,感受野太大,信息模糊程度很高——这也是为什么会将SPP替换为RoI Pooling
- Fast R-CNN:训练时,会先采样出N张图,在这N张图像中再平均采样出R个候选区域,一般N为2,R为128,卷积层需要保存的数据量大大减少(只需要保存N张原始图片的数据)。
总结Fast R-CNN的改进内容(与SPPNet相比):
- VGG16代替AlexNet
- 改变采样方式,使得卷积层参数也可学习
- 用RoI Pooling替换SPP
- 一个模型输出分类结果和检测框,使得分类器和检测的参数可以同时更新,也不再需要储存大量的中间特征
ResNet
(Deep) Residual Network (深度)残差网络
2015 ResNet
目标检测
作用:解决CNN在实际应用中出现的“网络越深效果越差”的问题,让模型自己学习到合适的网络深度。
为什么会“网络越深效果越差”:
理论上,加深神经网络,效果至少不会越差,应该优于或等于浅层网络的效果。
举个例子:
假设一个模型的最优层数为20,实际层数为x。
当x<20,x越大越能提取到深度信息,效果越好;当x>20,将多出来的那些层全都变成等输入输出的层,即输入和输出相等,就能得到与x=20相同的效果(这应该是网络能够学习到的)。
但实际上,当x<20时,x越大效果越好;当x>20时,x越大效果越差。

直观解释是网络很难学习到等输入输出的参数。因为这些参数更接近1,但初始化时,参数往往都是0。
根本原因是梯度消失。反向传播更新参数时,浅层的梯度由深层的梯度累乘得到,而梯度往往都小于1,当网络层数很多时,浅层的梯度很小(甚至很接近0),更新很慢(几乎不更新)。容易出现:深层的参数已经过拟合,而浅层还未习得合适的参数。
如何解决这个问题:
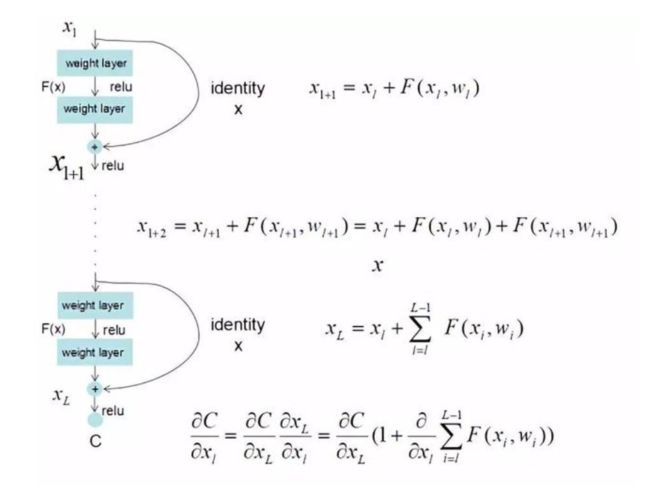
将浅层的输出直接加在深层的输入上。
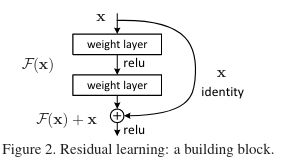
*  泛指当输入为
泛指当输入为 ,weight layer的输出
,weight layer的输出
图示结构为一个标准的残差块。
如果不考虑shortcut(右边的弧线连接),这个结构可以表示为:
- 输入(在整个网络中,为前面层的输出)
- 第一个卷积层,参数为
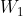
- 第一个激活层(ReLU)
- 第二个卷积层,参数为
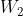
- 第二个激活层
- 输出
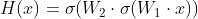 (
( 表示激活层)
表示激活层)
假设为第二个全连接层的输出,也就是第二个激活层的输入![]() ,那么输出可以表示为
,那么输出可以表示为![]()
考虑shortcuts,即将加在上,再一起传入第二个激活层,输出变为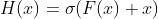
为什么有用:
- 不会出现梯度消失:当在一个网络中加入多个shortcuts,反向传播求梯度时,会将累乘变成累加(推导过程如下图所示),而且将公式变成了1+d,无论d有多小,都始终会有梯度(梯度不会为0)。
- 多余层的参数更容易习得:根据,当我们想要输入等于输出时,需要
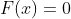 ,即中间层的参数为0(如果没有残差网络,需要参数为1),初始化时参数往往就是0,初始化值与目标值更接近。
,即中间层的参数为0(如果没有残差网络,需要参数为1),初始化时参数往往就是0,初始化值与目标值更接近。
总结:
一个深度CNN中,可以有多个残差块。如作者用一个34层的残差网络(34层conv+16个shortcuts),达到了比VGG19更高的准确率。一定程度上解决了网络退化(越深越差)的问题。
* 误差与残差:
假设已知一个映射, ,想要找到一个
,想要找到一个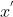 ,使得
,使得![]() ,当前找到的值是
,当前找到的值是
误差:![]()
残差:![]()
FCN
Fully Convolutional Networks 全卷积网络
图像语义分割
2015,end-to-end,像素级的分类,同时保留类别信息和位置信息 FCN
基于CNN(VGG16)框架,将末端的全连接层也换成卷积层、反卷积层。
为什么要换:CNN是对一张图/一个区域的预测。全连接层会损失位置信息,如果想要处理分割任务,需要在CNN之后再叠加一个后处理,用于逐像素点的预测(可以认为是还原位置信息的过程)。但其实CNN的中间过程是一直有保留位置信息的,可直接利用。
* 反卷积层:将卷积层输出的feature map映射回原图的尺寸(upsampling)
与CNN的区别:
- CNN:卷积层 + 全连接层,输出类别/属于各个类别的概率
- FCN:卷积层 + 反卷积层,输出heatmap(对原图的每个像素判断类别)
步骤:
- VGG16得到feature map
- 反卷积层得到与原图尺寸相同的feature map
- 逐像素判断类别(k个目标类别+背景)
- 按照类别填充颜色,即heatmap
Faster R-CNN
目标检测
2016 Faster R-CNN
对Fast R-CNN的加速,优化生成候选框的过程。因为生成了更加精确的候选框,候选框的数量也从2000降到了300。
Fast R-CNN存在的问题:
- 需要单独的模型(SS)生成候选框
基本结构:VGG16 + RPN + RoI + SVM&BB
步骤:
- 提取特征:整张图传入VGG16生成feature map
- 截取候选区域特征:
- 基于原图的feature map,用RPN(Region Proposal Network)生成候选区域框
- 根据框的位置信息在原图的feature map上截取候选区域特征
- RoI Pooling
- 同时输出分类结果和检测框的位置
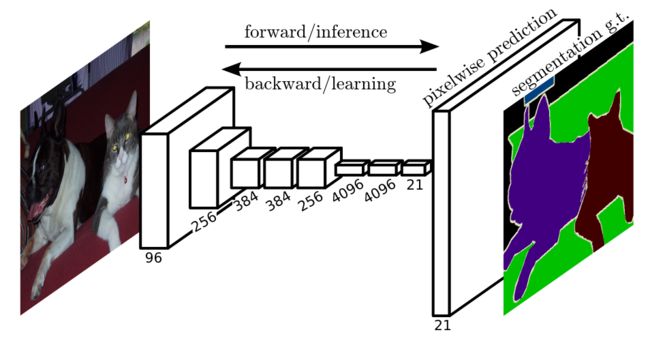
RPN(Region Proposal Network)
作用:与SS相同,生成候选区域框。
步骤:
- 生成feature map(这一步在Faster R-CNN中可以省去,直接使用VGG16生成的feature map)
- 将feature map中的点作为anchor,针对每一个anchor生成9个anchor box。如果feature map的尺寸为M*N,那么anchor box的个数为M*N*9(anchor是feature map中的点,但anchor box所包含的内容是原图中的点。feature map和原图的尺寸是不同的,通常会比原图小)
- 对每一个anchor进行分类,分为两个类别:positive物品,nagetive背景。假设feature map的通道数为256,那么可以认为有M*N个维度为1*256的向量,分类即对每一个维度为1*256的向量进行分类。
- 针对被分为positive的anchor,迭代更新anchor box的位置
- 输出positive的anchor和anchor box
针对每一个anchor生成9个anchor box:

与SS相比,RPN可以省去生成feature map的步骤,更好的融合到整个检测网络中去。
改进内容(与Fast R-CNN相比):
- 用RPN代替SS,通过一个网络实现所有流程:生成特征、选择候选框、分类、检测
FPN
Feature Pyramid Network 特征金字塔网络
目标检测
2017 FPN
用于提升小物体的检测性能。
可在基本不增加计算量的情况下,大幅提升小物体检测性能。
小物体检测性能的问题(以Faster R-CNN为例):
Faster R-CNN中,对最后一个卷积块输出的feature map(高层特征)上的每一个点进行分类。feature map往往比原图尺寸小,如小N倍,即feature map上的一个点对应原图上一个N*N的区域。如果物体的尺寸远小于N*N,可能会被忽略掉。
CNN网络中,低层特征包含的位置信息多(包含明确的轮廓信息),语义信息少(因为只有局部信息);高层特征包含的位置信息少,语义信息多。(越靠近input,层数越低)
解决方式:
将自底向上(bottom-up)卷积操作生成的feature map和自顶向下(top-down)下采样生成的feature map融合,操作融合后的feature map。
步骤:
- bottom-up生成多个feature map,即CNN的正向传播过程。feature map尺寸相同时,只保存最深层的。
- 从最高层开始,对feature map做upsampling,将upsampling得到的feature map与卷积层生成的feature map融合,并基于融合的feature map做预测(分类)
- 将融合的feature map传入下一层(top-down传递,从高层传向底层),并重复上一步的操作
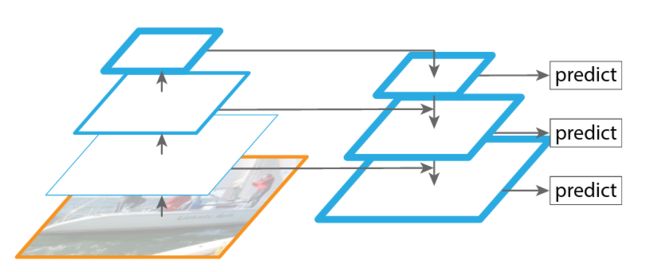
FPN可以认为是给优化检测效果提供了一种思路,它可被用于多种检测框架。如应用于Faster R-CNN,即将每一个融合后的feature map送入RPN,即可得到多个尺度的候选区域。
Mask R-CNN
实例分割
2018 Mask R-CNN
可用于实例分割、目标检测、关键点检测
计算速度与Faster R-CNN相当,也保留了FCN分割的准确率
基本结构:Faster R-CNN + FCN
详细地:VGG16 + RPN + RoIAlign + SVM&BB&[deconv + softmax]
步骤:
- 整图送入CNN,生成feature map
- 用RPN生成候选区域的feature map(尺寸不一)
- 对不同尺寸的feature map进行RoIAlign操作,统一尺寸
- 分为三路:
- SVM整图预测类型
- BB预测检测框
- FCN像素级预测类型
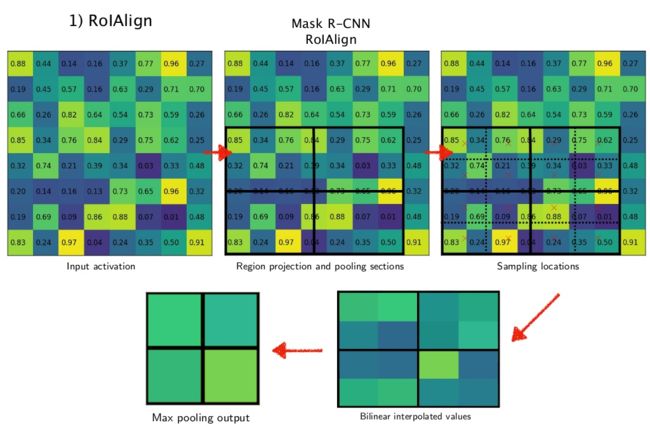
RoIAlign
对RoI Pooling的优化。
RoI Pooling存在的问题:
- 根据原图生成的候选框,映射到feature map上时,如果角点坐标不是整数,即角点坐标不在feature map上单个像素框的顶点上时,会直接将坐标值取整。
- 对候选框划分区域时直接取整(如5*7的候选区域,目标尺寸为2*2时,会被分为大小不等的四份:2*3,2*4,3*3,3*4),使得划分不够精细,各区域大小不一。(详情可参考上述RoI Pooling过程)
步骤(以输入5*7,输出2*2为例):
- 将区域划分成4(因为2*2=4)个大小相同的子区域,得到图2
- 每个子区域再划分成大小相同的4分,得到图3
- 如果每个最小的区域包含不止一个像素点,找到区域的中心点(图3中的x),用双线性插值法计算出中心点的值,得到图4
- 每个子区域max pooling,得到图5
三、RNN-
JordanNet、ElmanNet、BRNN、LSTM、GRU
RNN
Recurrent Neural Network 循环神经网络
处理序列数据
对全连接网络的改良,增加同层节点之间的连接,用于处理序列信息。即当前的值不仅取决于当前状态,也与过去的状态有关。
最原始的RNN有两种,Jordan Network和Elman Network,现在用的比较多的是Elman Network
ElmanNet
处理短序列数据
1990 ElmanNet
又称为SRN(Simple Recurrent Network)
基本结构:输入、隐藏层(Hidden Layer)、输出
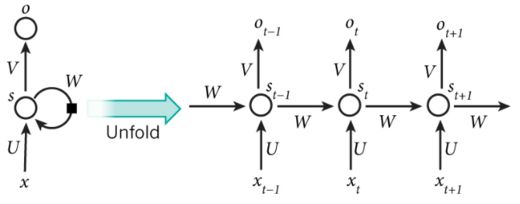
如图,输入序列x展开后为:![]() ,对应的输出序列为
,对应的输出序列为![]() (输入、输出序列长度可以不相等)。
(输入、输出序列长度可以不相等)。
- 如果不考虑前一时刻的影响,t时刻隐藏层的输出为
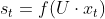 ,
, - 考虑t-1时刻的影响,
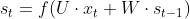 。
。
特点:
- 考虑时序信息
- 可能会出现梯度消失/爆炸,可以解决梯度消失问题的ElmanNet的变种:LSTM、GRU
- 训练慢(必须按序列顺序,一个一个的算)
JordanNet与ElmanNet
1986 JordanNet
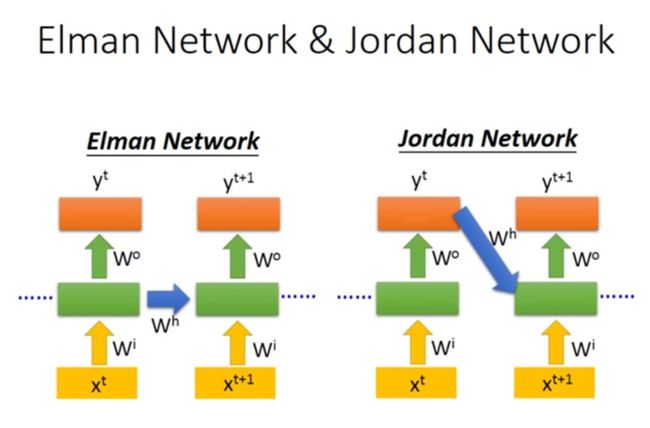
区别:
- ElmanNet传递隐藏层的输出
- JordanNet传递输出层的值
为什么ElmanNet应用更广泛:
更易于拓展。同一层比较好控制输入和输出维度一致(ElmanNet)。如果输出层数据维度和隐藏层数据维度不一致(经常发生),还需要增加额外的操作(JordanNet)。
BRNN
Bidirectional RNN 双向循环神经网络
处理序列数据
1997 BRNN
将常规RNN(单向RNN)拓展至双向。能够连接上下文信息。
单向RNN的问题:
只能按照序列顺序依次处理信息。计算t=T时刻的输出时,只能获取到t
例如:
- He said, "Teddy bears are on sale!"
- He said, "Teddy Roosevelt was a great President!"
在判断Teddy是玩偶还是人名时,单向RNN只能获取到单词Teddy之前的信息,可能会出错。BRNN可以根据Teddy之后的信息,即bears/President作出判断。
解决方式:
在正向传播的基础上,再增加一次反向传播(这里的反向传播不是指BP,而是指逆时序传播)
基本结构:
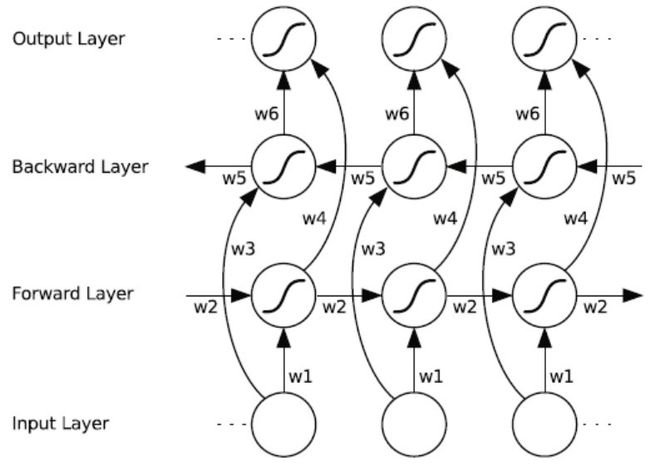
可以分为三步:正时序传播、逆时序传播、BP更新参数
- 正时序传播:from t=1 to t=T,依次计算输出,涉及参数W1, W2, W4
- 逆时序传播:from t=T to t=1,依次计算输出,涉及参数W3, W5, W6
- BP更新参数:用BP算法分别更新正时序传播的参数和逆时序传播的参数
特点:
- 优点:处理当前信息时,能同时考虑过去和将来的信息
- 缺点:必须输入完整的序列才能开始处理(例如,语音识别时,必须等人说完完整的句子,才能开始识别)
LSTM
Long-Shot Term Memory 长短时记忆网络
处理序列数据
1997 LSTM
对ElmanNet的改良,解决ElmanNet难以处理长期依赖的问题。
ElmanNet的问题:
梯度消失导致无法获取长序列的信息。BP更新参数时,计算较远的层对当前层的影响时,会乘上中间各层的W,W往往小于1,累乘的结果会很小。导致远距离数据的参数难以更新,而参数往往会被初始化为0。即信息的传递会由于距离的原因而逐渐衰减。
例如:
两个句子,根据前文预测句子的最后一个词:
(1) I live in China, I speak Chinese.
(2) I live in China. I'm 26 years old. I speak Chinese.
需要预测的词都是Chinese,用于预测Chinese的关键词都是China。
第一个句子中的China距离更近,对预测结果的影响更大,更容易得到正确的结果。
解决方式:
- 保存长期信息:(按某种程度)遗忘过去信息,(按某种程度)加入当前信息。
- 隐藏层的输出取决于:隐藏层的输入、上一时刻隐藏层的输出、长期信息。(短期记忆+长期记忆)
具体做法:增加三个门控单元
- 遗忘门(forget gate layer):控制遗忘过去信息的程度(用权重矩阵体现程度)
- 输入门(input gate layer):控制记录当前信息的程度
- 输出门(output gate layer):控制根据长期信息调整输出的程度
详细地:
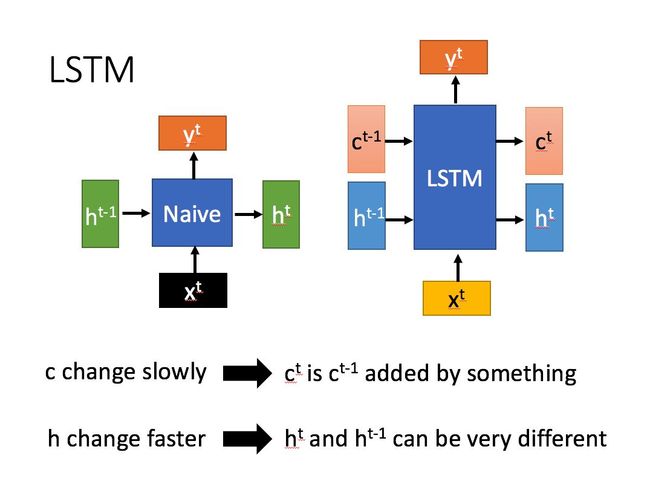
图解:
- 上左图:Naive表示原始RNN(ElmanNet)。x、y分别为输入、输出,h为隐藏层的输出
- 上右图:比左图多了一个c,表示单元状态(cell state) —— 长期信息
- 原始RNN(ElmanNet)只传递h,LSTM传递c和h。
LSTM展开:
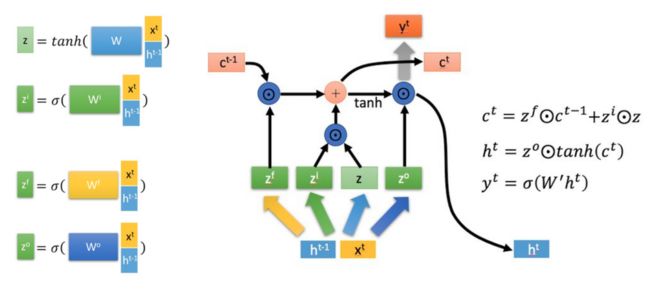
图解:
- 左图:
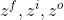 分别表示遗忘门、输入门、输出门的输出结果。
分别表示遗忘门、输入门、输出门的输出结果。 代表当前状态。
代表当前状态。- 代表sigmoid函数,所以 的取值范围为(0, 1),即不会出现抑制作用
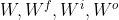 是可学习的参数矩阵(与权重相乘的矩阵由
是可学习的参数矩阵(与权重相乘的矩阵由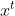 和
和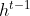 拼接得到,权重也是由两个矩阵拼接得到的。如
拼接得到,权重也是由两个矩阵拼接得到的。如 由
由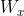 和
和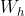 拼接得到,并且两个权重矩阵是分开训练的。)
拼接得到,并且两个权重矩阵是分开训练的。)
- 右图:
- 长期信息
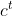 = 忘记部分过去信息
= 忘记部分过去信息 + 加入当前时刻的信息
+ 加入当前时刻的信息
- 隐藏层的输出
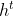 由输出门控单元
由输出门控单元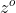 和长期信息共同决定
和长期信息共同决定 - 当前时刻的输出
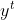 由隐藏层的输出决定(与ElmanNet相同)
由隐藏层的输出决定(与ElmanNet相同)
- 长期信息
LSTM也可以用下图表示:
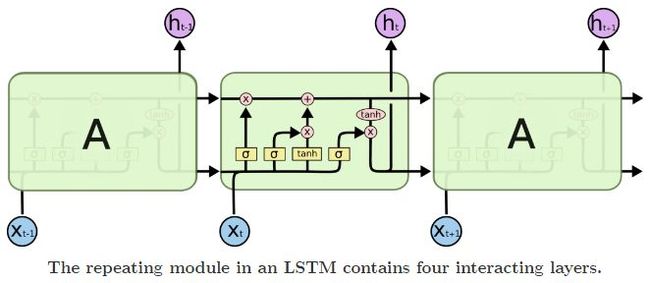
图解:
- 最右侧横向的两个箭头,从上至下分别表示
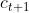 和
和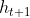
- 三个包含了的黄色矩形框,从左至右,分别表示遗忘门控单元、输入门控单元、输出门控单元
为什么可以解决梯度消失的问题:
- 长期信息的导数并不会收敛到0或无穷。(ElmanNet中,隐藏层的输出会收敛到0或无穷)具体推导过程
总结:
- 优点:可以解决长期依赖问题。
- 缺点:引入了大量参数,使训练变得困难。—— GRU对此作出了改进
GRU
Gate Recurrent Unit Network 门控循环网络
处理序列数据
2014 GRU
结构与LSTM十分相似,只有2个门控单元。参数比LSTM少,计算更快,但可以达到与LSTM相同的效果。
LSTM的问题:参数过多,导致学习困难,计算慢
基本结构:
两个门:重置门(reset gate)、更新门(update gate)
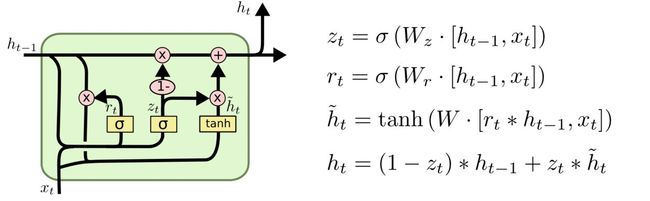
图解:
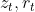 分别为更新门和重置门的输出
分别为更新门和重置门的输出- 表示sigmoid函数
![[h_{t-1}, x_{t}]](http://img.e-com-net.com/image/info8/1de3414bcabc43b49cb835c62f139a73.gif) 表示由
表示由 和
和 拼接得到的矩阵(与LSTM里面的拼接思路相同,权重矩阵也是由和拼接得到的)
拼接得到的矩阵(与LSTM里面的拼接思路相同,权重矩阵也是由和拼接得到的)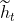 为当前需要记忆的内容,
为当前需要记忆的内容,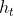 为隐藏层的输出
为隐藏层的输出- 第3个式子:当前需要记忆的内容,不仅取决于当前输入,还有前一时刻隐藏层的输出。的影响程度由重置门
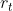 控制。
控制。 - 第4个式子:当前隐藏层的输出,由前一时刻隐藏层的输出和需要记忆的内容共同决定。的影响程度由更新门
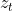 决定。
决定。
与LSTM相比:
- 更新门与LSTM中输入门
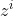 的作用类似
的作用类似 - 用
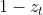 代替了LSTM中的遗忘门
代替了LSTM中的遗忘门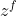
- 去掉了输出门
- 增加了重置门
效果:
- 也与LSTM十分类似,解决了梯度消失的问题,可以解决长期依赖问题。
该论文除了提出GRU,还提出了RNN Encoder-Decoder框架:
RNN Encoder-Decoder
结构:
- 先通过一个RNN将输入序列转换成固定长度的特征向量(Encoder)。
- 再通过一个RNN将特征向量转换为目标输出的格式(Decoder)。
* 两个RNN可以不同。
为什么要这么做:
传统的机器翻译方法(统计机器翻译SMT),主要是基于短语翻译,准确率不高。作者想要模拟人脑的翻译过程:先将整个句子读入(Encoder),在脑海里翻译成自己可以理解的语言,再翻译成目标语言(Decoder)。
(详细的计算过程就不写了。)
有很多基于Encoder-Decoder框架的模型,两端的RNN可以是任意模型,中间的转换过程也可以替换成其他模型。
四、其他
SN、GAN、Attention、Self-Attention
SN
Siamese Network 孪生网络
度量学习
1993 SN
用于判断2个签名是否源于同一个人。
基本框架:
由2个完全相同的网络组成(相当于只有1个网络)。计算2个网络输出之间的距离,判断是否为同一类。—— 不是优化具体的特征,而是优化特征之间的距离。
步骤:
- 输入2组数据(2张签名)
- 分别提取2个特征向量
- 比较特征向量之间的距离(计算相似度)
- 输出相似度(用于判断是否为同一人)
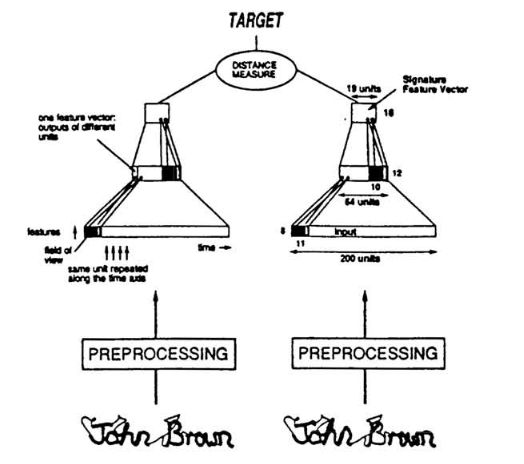
特点:
- 需要成对输入
- 其实只有1个网络。图中的2个网络结构完全相同,且全值共享。整个流程也可以写为:用1个网络对2个输入分别提取特征,输出特征之间的距离。
- 适用于类别较多,但每类的数据比较少的情况。每类数据比较少时,难以训练出一个好的模型来提取特征,但可以训练用于判断类别的模型(“A是什么” 与 “A是不是B”,是两个不同的任务)
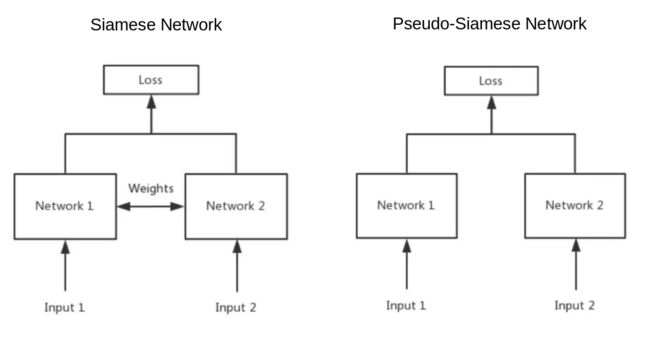
SN与PSN
Siamese Network & Pseudo-Siamese Network 孪生网络&伪孪生网络
结构:
- Siamese Network:2个网络结构完全相同,权值共享(1个网络)
- Pseudo-Siamese Network:2个网络结构不同,权值不共享(2个网络)(可以是2个结构完全不同的网络,如CNN和LSTM)
适用场景:
- Siamese Network:2个输入数据比较类似,如判断两个词汇的相似度(输入2个词语)
- Pseudo-Siamese Network:2个输入差异很大,如判断文字是否描述了图片(输入1句话和1张图)
GAN
Generative Adversarial Network 对抗网络
2014 GAN
用于生成样本 —— 目的是得到一个好的生成器。
生成器:
根据(某种格式的)输入,分析/理解输入数据,生成与输入数据类似的(可以是另一种格式的)输出(听起来像句废话 - -)。如:
- 输入/输出格式相同:修复受损的图片;改变姿势/面部表情
- 输入/输出格式不同:根据文字描述/语音生成图片
GAN网络由一个生成器和一个鉴别器组成:
- 生成器Generator:生成虚拟数据。
- 鉴别器Discriminator:鉴别数据的真实性。
步骤:
- 输入
- 生成器根据具体任务生成虚拟数据
- 输出
步骤里面没有鉴别器,因为鉴别器是用来训练生成器的。(实际使用时只需要生成器,训练时需要生成器+鉴别器)
训练过程中会出现两种训练模式:
- 固定鉴别器,训练生成器,目的是提高鉴别器的错误率(鉴别器错误率越高,说明生成器生成的数据越逼真)
- 固定生成器,训练鉴别器,目的是降低鉴别器的错误率(再用错误率更低的鉴别器去训练生成器)
在整个训练过程中,两种训练模式交替进行。
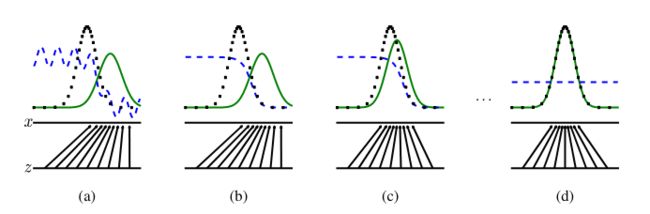
图解:
- 不同颜色线段的含义:
- 黑色:真实数据的分布
- 绿色:虚拟数据的分布
- 蓝色:鉴别器的效果分布
- (a)初始训练阶段:直接使用一个效果还不错的鉴别器来做判断,训练生成器
- (b)使用(a)中训练好的生成器生成虚拟数据,训练鉴别器
- (c)使用(b)中训练好的鉴别器来做判断,训练生成器
- (d)训练结束。虚拟数据能很好的拟合真实数据,鉴别器无法区分真假数据,即错误率始终为0.5(达到纳什均衡)
GAN网络也是一个很灵活的结构,可以使用各种模型作为生成器和鉴别器。
Attention
注意力机制
2014 Attention + RNN
用于计算信息的相关程度,可从众多信息中选出对目标任务更关键的信息。信息的相关程度更依赖于信息本身,而不是序列顺序(RNN中信息的相关程度更依赖于顺序)。
步骤:
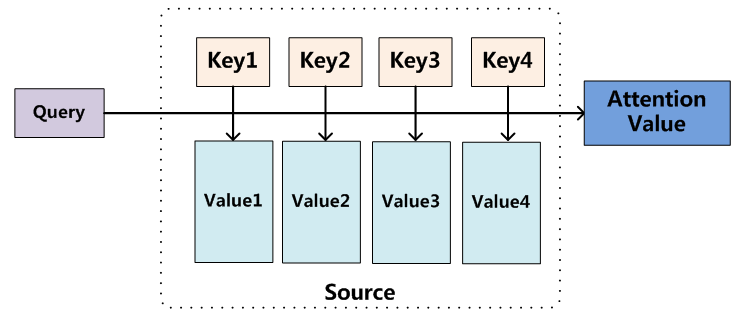
如上图,输入信息为Query,知识库中有Keys,输出信息为Attention Value。
- 计算Query与Keys中各元素的相似度,得到相关程度Values
- 根据Keys和Values计算输出值Attention Value
- 计算输出值,可以简单的理解为加权平均的过程,即
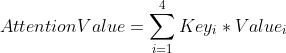
Attention多与Encoder-Decoder联合使用,Encoder/Decoder可以是各种网络。如下图(2016Google机器翻译系统模型):
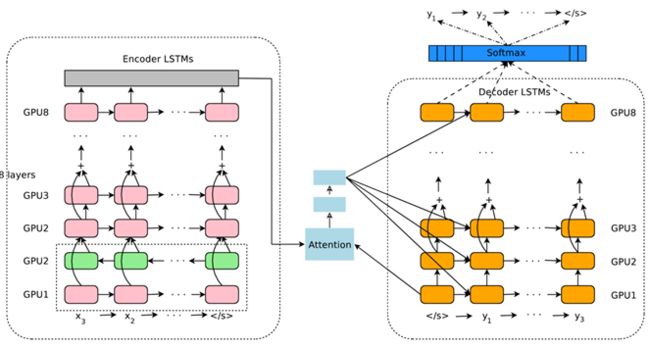
整体框架为:
- 输入
- Encoder(8层LSTM)
- Attention
- Decoder(8层LSTM)
- 输出
Self-Attention
2017 self-attention
与Attention结构类似,但适用对象不同。
机器翻译领域中,
- Attention用在encoder之后、decoder之前,是输入语言与输出语言的映射,建立输入语言单词和目标语言单词之间的映射关系。(多用于不同语言之间,如 like - 喜欢)
- Self-Attention用在输入数据内部,和输出数据内部,建立输入/输出数据内部的联系。(多用于同种语言之间,如抽取文本关键词)
Self-Attention往往能比Attention取得更好的效果,因为他先考虑了输入数据内部的联系,再做映射(对长难句很有用)。