Attention综述
整理了近来看过的几篇用于计算机视觉方向的Attention论文
1.Residual Attention Network
首次成功将极深卷积神经网络与人类视觉注意力机制进行了有效的结合
本文提出了一种可堆叠的网络结构。与ResNet中的Residual Block结构相似,本文所提出的网络结构也是通过一个ResidualAttention Module的结构进行堆叠,可使网络模型能够很容易的达到很深的层次。(只是结构相似)

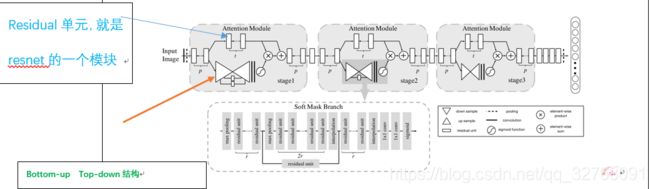
每个阶段都有自己对应的Attention分支去学权重。是Spatial Attention和Channel Attention的结合
一系列的下采样和上采样最后sigmoid.
2.Squeeze and Exciation Network
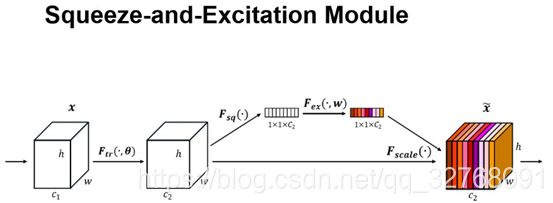
上图是SEnet的核心思想结构,通过一系列卷积后产生的X,首先是经过 Squeeze 操作,我们顺着空间维度来进行特征压缩(原文是全局最大池化),将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。 然后再经过 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。 最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
这是一种Channel Attention。
3.Self Attention GAN
关于这GAN的东西就不解释了,主要介绍Self Attention
本文是寻求一种能够利用全局信息的方法


γ \gamma γ这里是想表达Attention一开始学的不好,通过学习逐渐增大其权重(有人实测没发现有用,我自己未实验 不过分类我用上没效果)
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
4.SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
这篇论文是讲述image caption的,但是其中关于Attention的思想还是挺不错的
lower-layer filters detect low-level visual cues like edges and corners while higher-level ones detect high-level semantic patterns like parts and object
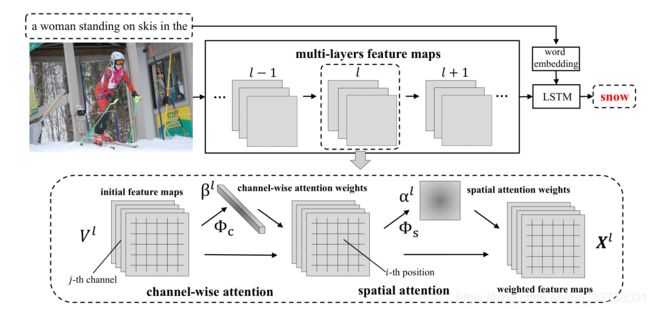
做Spatial Attention 时候是reshape V = [v 1 ,v 2 ,…,v m ] by flattening the width and height of the original V,V是经过一系列卷积产生的特征。
做Channel Attention时候reshape we first reshape V to U, and U = [u 1 ,u 2 ,…,u C ]然后对 每个通道做mean pooling ,v = [v 1 ,v 2 ,…,v C ]
作者在这里还提到Attention层不能过量,具体看实验。