【RL 第3章】Sarsa
这一章算法,恐怕是最简单的一章算法了,因为用一句话来说,Sarsa就是Q-Learning的孪生兄弟一样!这句话怎么理解呢?各位别急,听Willing细细道来
在上一章Q-Learning算法中,我们知道,Q表的更新迭代过程是下面这样的:

在这个式子中,加号的后面是贪婪因子γ,和下一个状态中最大的Q值的乘积
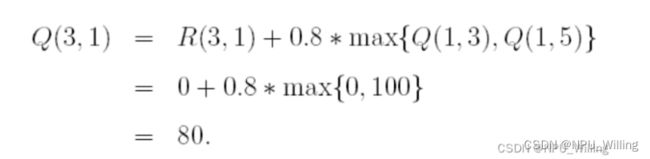
比如,在昨天这个例子中,因为Q(1,5)是大于Q(1,3)的,所以我们用贪婪因子γ乘以Q(1,5)的值,也就是100
而Sarsa是怎么一回事呢?一句话: 在Sarsa算法中,我们加号后面的部分变成用贪婪因子乘以下一个状态的随机一个动作的Q值!
也就是说,我们不再追求下一个动作的Q值最大,而是也是采取随机的方式,随机选一个动作!!!!!
还是用一个具体的例子说明(和昨天的例子一样):
假定贪婪因子γ=0.8
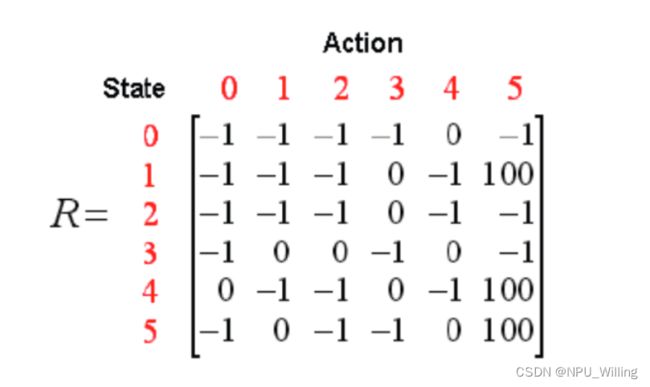
Reward矩阵:
初始化Q表:
 接下来,我们随机选择一个状态,例如State 4,我们发现并未达到目标状态,于是我们在Reward矩阵中查看4所能到达的房间(即可以进行的Action) ,发现是0,3或5,随机的,我们选择3作为next_state,再随机的,我们选择一个3可以进行的动作,比如1。
接下来,我们随机选择一个状态,例如State 4,我们发现并未达到目标状态,于是我们在Reward矩阵中查看4所能到达的房间(即可以进行的Action) ,发现是0,3或5,随机的,我们选择3作为next_state,再随机的,我们选择一个3可以进行的动作,比如1。
于是得到Q(4,3)=R(4,3)+γ*Q(3,1)
对比一下,如果是Q-Learning的话,则:
Q(4,3)=R(4,3)+γ*Q(3).max
也就是说,Sarsa与Q-Learning不同的是,他的第二次选择不是选一个最大值,而是再来一次随机选择!!
ok,这下大家应该很清楚了,下面Willig也把Sarsa的代码给大家放上,所使用的是Python语言,需要用到numpy库函数,其他语言的代码也欢迎各位大佬私信补充ヾ(≧∇≦*)ゝ
A.建立Reward矩阵,并初始化Q表
import numpy as np
import random
# 建立 Q 表
q = np.zeros((6, 6))
q = np.matrix(q)
# 建立 R 表
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
r = np.matrix(r)
# 贪婪指数
gamma = 0.8B.训练Q表,唯一不同的是两次随机选择动作
# 训练
for i in range(100000):
# 对每一个训练,随机选择一种状态
state = random.randint(0, 5)
while state != 5:
# 选择r表中非负的值的动作
actions = []
for a in range(6):
if r[state, a] >= 0:
actions.append(a)
action = actions[random.randint(0, len(actions) - 1)]
R = r[state, action]
next_state = action
actions = []
for a in range(6):
if r[next_state, a] >= 0:
actions.append(a)
#与上一步采取相同的动作(Sarsa核心)
next_action = actions[random.randint(0, len(actions) - 1)]
q[state, action] = R + gamma * q[next_state, next_action]
state = next_state
action = next_action
print(q)C.测试验证(与Q-Learning部分相同)
# 验证
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 2)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
# 选择最大的q_max
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1模型效果如下:


因为Sarsa在训练过程中并不像Q-Learning那样永远选一条离成功最近的路,而是像一个勇士一样去探索更多未知的可能,所以在实际应用中我们还是更偏向于Q-Learning一些 。
ok,那么以上便是Sarsa的全部内容,因为与Q-Learning特别相似,所以我们学起来也非常简单,感谢大家的阅读!!!o(〃'▽'〃)o