yolo系列学习笔记----yolov5
1,概述
YOLOv5的大小仅有 27 MB,而使用 darknet 架构的 YOLOv4 有 244 MB,对比之下小了近 90%,同时在准确度方面又与 YOLOv4 基准相当。
Github地址:https://github.com/ultralytics/yolov5
yolov5权重文件:https://pan.baidu.com/s/1Zk2Ksfl_v-apbRBQ_mqc6w
密码:00mp

Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种(Yolov5m、Yolov5l、Yolov5x)都是在此基础上不断加深,不断加宽。

1,网络结构
1.1,Backbone
1.1.1 Focus结构
1) Focus的原理:
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
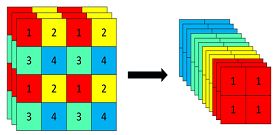
以Yolov5s的结构为例,原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图。
具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
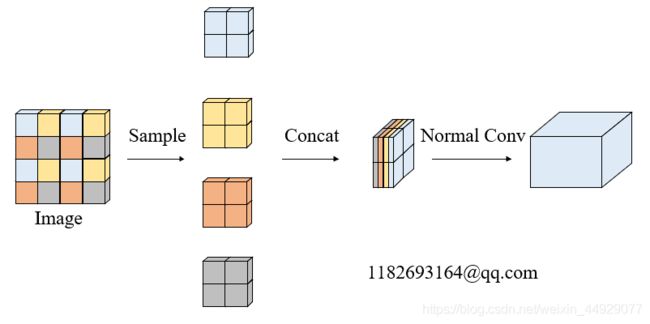
代码为:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
2)Focus的优势
*普通参数量计算
参数数量(params):关系到模型大小,单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍。
计算量(FLOPs):即浮点运算数,可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。
params计算公式:
Kh × Kw × Cin × Cout
FLOPs计算公式:
Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map)= params × H × W
众所周知,图片在经过Focus模块后,最直观的是起到了下采样的作用,但是和常用的卷积下采样有些不一样,可以对Focus的计算量和普通卷积的下采样计算量进行做个对比:
在yolov5s的网络结构中,可以看到,Focus模块的卷积核是3 × 3,输出通道是32:
*普通下采样和Focus的对比:
普通下采样:即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样理论的计算量为:
FLOPs(conv) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600(不考虑bias情况下)
params参数量(conv) = 3 × 3 × 3 × 32 +32 +32 = 928 (后面两个32分别为bias和BN层参数)
Focus:将640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过3 × 3的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,那么Focus理论的计算量为:
FLOPs(Focus) = 3 × 3 × 12 × 32 × 320 × 320 = 353894400(不考虑bias情况下)
params参数量(Focus)= 3 × 3 × 12 × 32 +32 +32 =3520 (为了呼应上图输出的参数量,将后面两个32分别为bias和BN层的参数考虑进去,通常这两个占比比较小可以忽略)
可以明显的看到,Focus的计算量和参数量要比普通卷积要多一些,是普通卷积的4倍,但是下采样时没有信息的丢失。
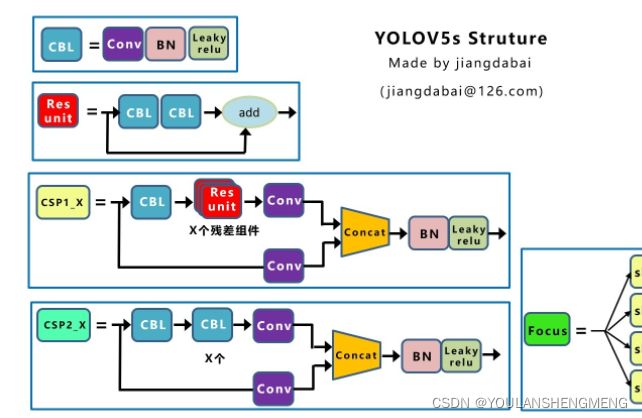
1.1.2 CSP结构
Yolov5与Yolov4都有CSP结构,不同点在于,Yolov4中只有主干网络使用了CSP结构,如下图所示,是YOLOV4的CSP结构。

Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
1.2 Neck
改进的FPN+PAN结构
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构。
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。

2,数据增强
(1)Mosaic数据增强:
同Yolov4,是这个作者提出来的。Mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。

(2)自适应图片缩放:
在训练阶段,比如网络输入的尺寸608×608,但我数据的尺寸是大小不一的,一般方法是直接同一缩放到标准尺寸,然后填充黑边,如下图所示:

但如果填充的比较多,则存在信息冗余,影响推理速度。
Yolov5在推理阶段,采用缩减黑边的方式,来提高推理的速度。在代码datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
eg:“比如我1000×800的图片不是直接缩放到608×608的大小,而是计算608/1000=0.608 然后缩放至608×486的大小,然后计算608-486=122 然后np.mod(122,32)取余数得到26,再平均成13填充到图片高度两端,最后是608×512。”
3,锚框的处理
自适应锚框计算
在以前的yolo中,我们要自己用k-means聚类算出初始anchors的大小,但Yolov5中将此功能整进了train代码里,每次训练时自适应的计算不同训练集中的最佳锚框值。
Yolov5原本在模型配置文件(如yolov5l.py)中有默认的anchors,这些anchors是基于COCO数据集在640×640图像大小下锚定框的尺寸。Yolov5会自动按照新的数据集的labels自动学习anchors的尺寸。采用 k 均值和遗传学习算法对自定义数据集进行分析,获得适合自定义数据集中对象边界框预测的预设锚定框。
一开始会先计算Best Possible Recall (BPR)
再在kmean_anchors函数中进行k 均值和遗传学习算法更新anchors。
4,Prediction
4.1 Bounding box损失函数
Yolov4中采用的CIOU_Loss做Bounding box的损失函数,Yolov5中采用其中的GIOU_Loss。
ps:回归损失函数近些年的发展过程是:
Smooth L1 Loss → IoU Loss(2016)→ GIoU Loss(2019)→ DIoU Loss(2020)→ CIoU Loss(2020)
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
4.2 nms非极大值抑制
后处理阶段一般会对很多个框进行NMS算法,因为CIOU_Loss中包含影响因子,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。
所以Yolov4推理时是在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中是GIOU_Loss的基础上采用加权nms的方式。
知识回顾:
NMS非极大值抑制算法
我们先看一下NMS的直观理解,左图为两个ground truth的bbox,右图为模拟网络输出的预测框。

而下图则是使用Pytorch官方提供的NMS实现的非极大值抑制,可以看到经过NMS后预测框保留了效果最好的,去除了冗余的预测框。

下面来讲讲NMS算法的流程,其实也是十分简单的
一.从所有候选框中选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IOU超过预定阈值的其他边界框移除。
二.从所有候选框中选取置信度第二高的边界框B2作为一个基准,将所有与B2的IOU超过预定阈值的其他边界框移除。
三.重复上述操作,直到所有预测框都被当做基准——这时候没有一对边界框过于相似
下面的代码,简洁的集成了对与GIOU,DIOU,CIOU的计算。
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-9):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / ((1 + eps) - iou + v)
return iou - (rho2 / c2 + v * alpha) # CIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
部分转自:目标检测——YOLOv5(八)_散修炼丹师手记-CSDN博客_yolov5目标检测