matlab中 概率密度估计ksdensity,k-s检验kstest和kstest2(单/双样本检验数据是否符合某种分布)
一、matlab概率密度估计
函数:ksdensity
功能:根据给定的数据,估计概率密度分布
示例:
1. 正态分布
x = randn(1,100000);
[y,xi] = ksdensity(x);
plot(xi,y, 'bo')
% 验证
hold on
yn=normpdf(xi,0,1); % 标准正态分布的概率密度函数
plot(xi,yn,'b')
其他请参考:http://blog.chinaunix.net/uid-20692368-id-5680963.html,感谢作者分享。
补充:matlab 中 ,
cdfplot 功能是绘制经验累计分布函数图;
pdf 函数计算概率密度函数值;
通用函数cdf用来计算随机变量的概率之和(累积概率值)
频率分布直方图 N = hist(Y),指定分10个bins,或者N = hist(Y,M)where M is a scalar, uses M bins.(M是一个标量,表明使用M个箱子) ;
或者使用 y = histogram(x);
目前,推荐使用histogram。关于hist和histogram的区别,hist是旧版,具体区别参考:
https://blog.csdn.net/fadbgfnbxb/article/details/93199679
一些其他的专用分布函数请参考:https://www.cnblogs.com/djcsch2001/archive/2012/01/31/2333960.html
常见的统计特征:均值、方差、相关系数等
https://www.cnblogs.com/djcsch2001/archive/2012/02/05/2339189.html
统计作图:经验累积分布函数图形等
https://www.cnblogs.com/djcsch2001/archive/2012/02/05/2339189.html
二、matlab实例:
给出一个比较典型的matlab实例:画出数据 频数分布直方图 核密度估计 正态分布,根据标准正态分布概率密度函数pdf来检验数据分布
%调用ecdf函数计算xc处的经验分布函数值f_ecdf
score = randn(1,100000);%给出一个随机生成的标准正态分布数据,需要替换成自己的数据
[f_ecdf,xc]=ecdf(score);
%新建图形窗口,然后绘制评论直方图,直方图对应7个小区间
figure;
ecdfhist(f_ecdf,xc,7);
hold on;
xlabel('考试成绩');
ylabel('f(x)');
%调用ksdensity函数进行核密度估计
[f_ks1,xi1,u1]=ksdensity(score);
%绘制核密度估计图,并设置线条为黑色实线,宽度为3
plot(xi1,f_ks1,'k','linewidth',3);
%计算正态分布的密度函数图
ms=mean(score); %均值
ss=std(score); %方差
%计算xi1处的正态分布密度函数值,正态分布的均值是ms,方差是ss
f_norm=normpdf(xi1,ms,ss);
%绘制正态分布密度函数图,并设置线条颜色为红色点画线,宽3
plot(xi1,f_norm,'r-.','linewidth',3);
%给图形加入标注框
legend('频率直方图','核密度估计图','正态分布密度图');https://blog.csdn.net/matlab_matlab/article/details/56286868
三、KS-检验(Kolmogorov-Smirnov test) -- 检验数据是否符合某种分布
Kolmogorov-Smirnov是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法。其原假设H0:两个数据分布一致或者数据符合理论分布。D=max| f(x)- g(x)|,当实际观测值D>D(n,α)则拒绝H0,否则则接受H0假设。
KS检验与t-检验之类的其他方法不同是KS检验不需要知道数据的分布情况,可以算是一种非参数检验方法。当然这样方便的代价就是当检验的数据分布符合特定的分布事,KS检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS检验最为非参数检验在分析两组数据之间是否不同时相当常用。
PS:t-检验的假设是检验的数据满足正态分布,否则对于小样本不满足正态分布的数据用t-检验就会造成较大的偏差,虽然对于大样本不满足正态分布的数据而言t-检验还是相当精确有效的手段。
普通的讲述 K-S 检验的文章略有不同,分为两部分:
(1). 针对大部分分布的 Kolmogorov–Smirnov 检验(真正的K-S检验)
(2). 仅适用于高斯分布的基于分布曲线形状的 kurtosis-skewness检验准则(不是真正的K-S检验)
matlab中kstest函数的使用:
H = kstest(X) %测试向量X是否服从标准正态分布,测试水平为5%。H=0接受原假设,H=1拒绝原假设。
H = kstest(X,cdf) %指定累积分布函数为cdf的测试(cdf=[ ]时表示标准正态分布),测试水平为5%
H = kstest(X,cdf,alpha) % alpha为指定测试水平H=kstest(X,cdf,alpha,tail) % tail=0为双侧检验, tail=1单侧(<)检验, tail=-1单侧(>) 检验
[H,P,KSSTAT,CV] = kstest(X,cdf,alpha) %P为原假设成立的概率,KSSTAT为测试统计量的值,CV为是否接受假设的临界值。
注意:kstest适用于小样本,当数据过大时,检验拒绝的临界值非常小,结果往往是拒绝原假设。
各种检验方法适用范围如下:
chi2gof适合大样本,一般要求50个以上
kstest适于小样本,
lillietest用于正态分布,与kstest类似,适用于小样本
jbtest,是通过峰度、偏度检测正态分布的,适用用大样本。
原文链接:https://blog.csdn.net/WUDIPIPIXIA/article/details/101939085
其实,
k-s检验分为单样本kstest和双样本kstest2检验:
Single sample Kolmogorov-Smirnov goodness-of-fit hypothesis test.
H = KSTEST(X,CDF,ALPHA,TAIL) % X为待检测样本,CDF可选:如果空缺,则默认为检测标准正态分布;ALPHA是显著性水平(默认0.05)。TAIL是表示检验的类型(默认unequal,不平衡)。还有larger,smaller可以选择。
如果,H=1 则否定无效假设; H=0,不否定无效假设(在alpha水平上)
例如,
x = -2:1:4
x =
-2 -1 0 1 2 3 4
[h,p,k,c] = kstest(x,[],0.05,0)
h =
0
p =
0.13632
k =
0.41277
c =
0.48342
The test fails to reject the null hypothesis that the values come from a standard normal distribution.
Two-sample Kolmogorov-Smirnov test
检验两个数据向量之间的分布的。
>>[h,p,ks2stat] = kstest2(x1,x2,alpha,tail)
% x1,x2都为向量,ALPHA是显著性水平(默认0.05)。TAIL是表示检验的类型(默认unequal,不平衡)。
例如,x = -1:1:5
y = randn(20,1);
[h,p,k] = kstest2(x,y)
h =
0
p =
0.0774
k =
0.5214
KS检验是如何工作的?
-
首先观察下分析数据
对于以下两组数据:
controlB={1.26, 0.34, 0.70, 1.75, 50.57, 1.55, 0.08, 0.42, 0.50, 3.20, 0.15, 0.49, 0.95, 0.24, 1.37, 0.17, 6.98, 0.10, 0.94, 0.38}
treatmentB= {2.37, 2.16, 14.82, 1.73, 41.04, 0.23, 1.32, 2.91, 39.41, 0.11, 27.44, 4.51, 0.51, 4.50, 0.18, 14.68, 4.66, 1.30, 2.06, 1.19}
对于controlB,这些数据的统计描述如下:
Mean = 3.61
Median = 0.60
High = 50.6 Low = 0.08
Standard Deviation = 11.2
可以发现这组数据并不符合正态分布, 否则大约有15%的数据会小于均值-标准差(3.61-11.2),而数据中显然没有小于0的数。 -
观察数据的累计分段函数(Cumulative Fraction Function)
对controlB数据从小到大进行排序:
sorted controlB={0.08, 0.10, 0.15, 0.17, 0.24, 0.34, 0.38, 0.42, 0.49, 0.50, 0.70, 0.94, 0.95, 1.26, 1.37, 1.55, 1.75, 3.20, 6.98, 50.57}。10%的数据(2/20)小于0.15,85%(17/20)的数据小于3。所以,对任何数x来说,其累计分段就是所有比x小的数在数据集中所占的比例。下图就是controlB数据集的累计分段图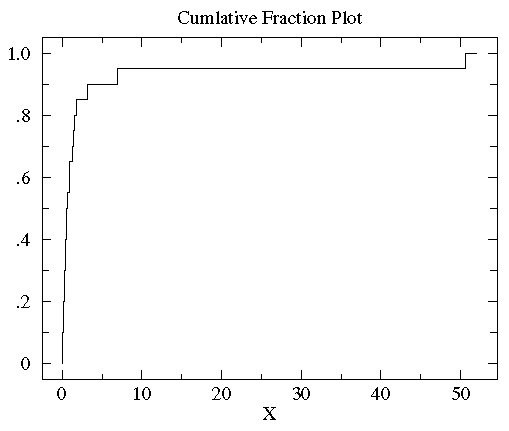
可以看到大多数数据都几种在图片左侧(数据值比较小),这就是非正态分布的标志。为了更好的观测数据在x轴上的分布,可以对x轴的坐标进行非等分的划分。在数据都为正的时候有一个很好的方法就是对x轴进行log转换。下图就是上图做log转换以后的图:
将treatmentB的数据也做相同的图(如下),可以发现treatmentB和controlB的数据分布范围大致相同(0.1 - 50)。但是对于大部分x值,在controlB数据集中比x小的数据所占的比例比在treatmentB中要高,也就是说达到相同累计比例的值在treatment组中比control中要高。KS检验使用的是两条累计分布曲线之间的最大垂直差作为D值(statistic D)作为描述两组数据之间的差异。在此图中这个D值出现在x=1附近,而D值为0.45(0.65-0.25)。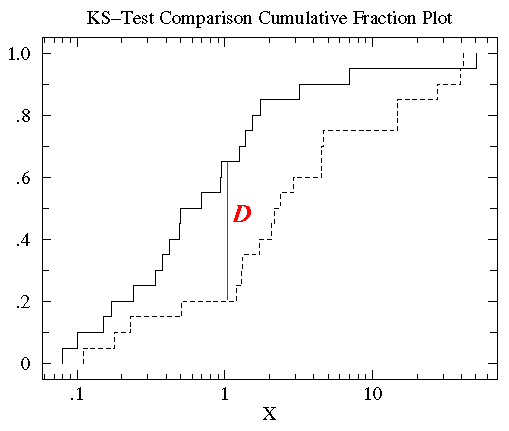
值得注意的是虽然累计分布曲线的性状会随着对数据做转换处理而改变(如log转换),但是D值的大小是不会变的。 -
百分比图(percentile plot)
估算分布函数肩形图(Estimated Distribution Function Ogive)是一种累计分段图的替代方式。其优势在于可以让你使用概率图纸作图(坐标轴经过特殊分段处理,y轴上的数值间隔符合正态分布),从而根据概率在y轴上的分布可以直观的判断数据到底有多符合正态分布,因为正态分布的数据在这种坐标上是呈一条直线。
那么这种图是如何画的呢?
假设我们有这5个数{-0.45, 1.11, 0.48, -0.82, -1.26},从小到大对它们进行排序,{ -1.26, -0.82, -0.45, 0.48, 1.11 }。0.45是中位数,百分比为0.5,而0.45的累计分布函数中占了0.4到0.6的区间。根据数据x在数据集(N)中排位r可以计算x的百分数(percentile)为r/(N+1)。将上述数据与他们的百分数配对,得到{ (-1.26,.167), (-0.82,.333), (-0.45,.5), (0.48,.667), (1.11,.833) }。然后将各点之间用直线连接就是百分比图了。如下图中红线所示(另一条线为累计分段曲线)。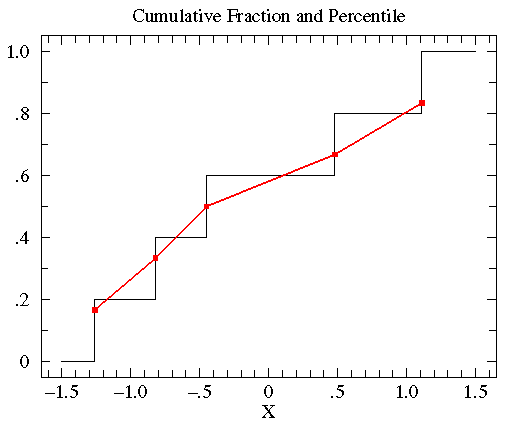
treatmentB的数据近似对数正态分布,其几何均值为2.563,标准差为6.795。该数据的百分图(红)与其近似的对数正态分布曲线(蓝)如下。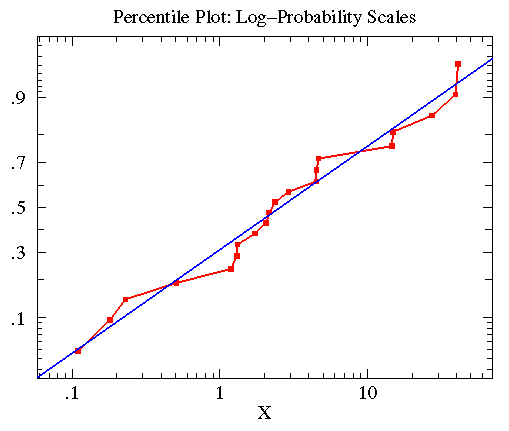
由于数据近似正态分布,所以对其采用t-检验是最佳的检验方法。
如何使用KS检验
在R中可以使用ks.test()函数。
在matlab中是kstest()函数,见上方。
与类似的分布检验方式比较
- 经常使用的拟合优度检验和Kolmogorov-Smirnov检验的检验功效较低,在许多计算机软件的Kolmogorov-Smirnov检验无论是大小样本都用大样本近似的公式,很不精准,一般使用Shapiro-Wilk检验和Lilliefor检验。
- Kolmogorov-Smirnov检验只能检验是否一个样本来自于一个已知样本,而Lilliefor检验可以检验是否来自未知总体。
- Shapiro-Wilk检验和Lilliefor检验都是进行大小排序后得到的,所以易受异常值的影响。
- Shapiro-Wilk检验只适用于小样本场合(3≤n≤50),其他方法的检验功效一般随样本容量的增大而增大。
- 拟合优度检验和Kolmogorov-Smirnov检验都采用实际频数和期望频数进行检验,前者既可用于连续总体,又可用于离散总体,而Kolmogorov-Smirnov检验只适用于连续和定量数据。
- 拟合优度检验的检验结果依赖于分组,而其他方法的检验结果与区间划分无关。
参考链接:
https://www.cnblogs.com/arkenstone/p/5496761.html
http://www.physics.csbsju.edu/stats/KS-test.html
http://blog.sina.com.cn/s/blog_403aa80a01019ly5.html