Yolov1模型——pytorch实现
论文传送门:You Only Look Once: Unified, Real-Time Object Detection
Yolov1的任务:
目标检测
Yolov1的结构:
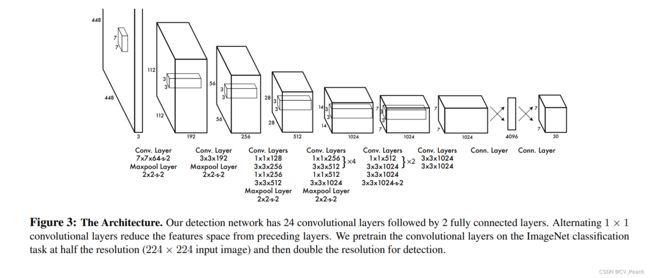
输入3通道448x448的图片,经过一系列的卷积和最大池化,得到1024x7x7的特征层,通过2个全连接层,得到30x7x7的预测结果。其中,卷积层的激活函数选用LeakyRelu(0.1)。
作者先使用3通道224x224的图片输入在ImageNet分类任务上预训练卷积层,然后将分辨率提升一倍用于检测。
Yolov1的主干网络是作者自己设计的,没有特定的名字。
(论文结构图的对应关系有点混乱,代码实现时按每一列的layers进行搭建)
网络输出(30,7,7)的含义:
Yolo相当于把原图划分为7x7共49个cell,每个cell负责预测中心点位于其中的obj(此时还没有anchor这一概念)。 30 = ( ( 4 + 1 ) ∗ 2 + 20 ) 30=((4+1)*2+20) 30=((4+1)∗2+20),每个cell预测2个bbox,每个bbox预测5个参数,分别为中心点坐标x、y,box的宽高w、h和置信度C(confidence),对应 ( 4 + 1 ) ∗ 2 (4+1)*2 (4+1)∗2;而后20个参数对应20个类别的概率,每个cell共计30个参数,所以输出为(30,7,7)。
Yolov1的损失:
由于每个cell包含2个bbox,设定若cell中存在obj,则与真实bbox的IOU最大的那个bbox为responsible bbox,也就是公式中的 1 i j o b j = 1 1^{obj}_{ij}=1 1ijobj=1;设定若cell中存在obj,而与真实bbox的IOU非最大的那个bbox为irresponsible bbox, 1 i j o b j = 0 1^{obj}_{ij}=0 1ijobj=0;设定若cell中不存在obj,则 1 i j o b j = 0 1^{obj}_{ij}=0 1ijobj=0。
损失共5行,由3部分组成:
①回归损失coordinate loss:第1、2行,仅对responsible bbox计算,loss系数为 λ c o o r d λ_{coord} λcoord,论文中取5;为增加小目标宽高损失(减少大目标宽高损失),宽高计算时取根号;
②置信度损失confidence loss:第3、4行,对所有的bbox均进行计算;对responsible bbox,loss系数为1, C i C_i Ci为最大IOU;对irresponsible bbox和不含obj的bbox,loss系数为 λ n o o b j λ_{noobj} λnoobj,论文中取0.5, C i C_i Ci为0;
③分类损失classification loss:第5行,对包含obj的cell进行计算。
以上所有损失均为MSE损失。

(代码仅实现模型结构和损失计算部分)
import torch
import torch.nn as nn
import torch.nn.functional as F
class Yolov1(nn.Module): # Yolov1模型
def __init__(self, in_channel=3): # 默认输入图像shape为(3,448,488)
super(Yolov1, self).__init__()
# 每一个block对应论文结构图中每一列
self.block1 = nn.Sequential(
nn.Conv2d(in_channel, 64, 7, 2, 3),
nn.LeakyReLU(0.1),
nn.MaxPool2d(2, 2)
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 192, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.MaxPool2d(2, 2),
)
self.block3 = nn.Sequential(
nn.Conv2d(192, 128, 1, 1, 0),
nn.LeakyReLU(0.1),
nn.Conv2d(128, 256, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(256, 256, 1, 1, 0),
nn.LeakyReLU(0.1),
nn.Conv2d(256, 512, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.MaxPool2d(2, 2)
)
self.block4 = nn.Sequential(
*[nn.Conv2d(512, 256, 1, 1, 0),
nn.LeakyReLU(0.1),
nn.Conv2d(256, 512, 3, 1, 1),
nn.LeakyReLU(0.1)] * 4,
nn.Conv2d(512, 512, 1, 1, 0),
nn.LeakyReLU(0.1),
nn.Conv2d(512, 1024, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.MaxPool2d(2, 2),
)
self.block5 = nn.Sequential(
*[nn.Conv2d(1024, 512, 1, 1, 0),
nn.LeakyReLU(0.1),
nn.Conv2d(512, 1024, 3, 1, 1),
nn.LeakyReLU(0.1)] * 2,
nn.Conv2d(1024, 1024, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(1024, 1024, 3, 2, 1),
nn.LeakyReLU(0.1)
)
self.block6 = nn.Sequential(
nn.Conv2d(1024, 1024, 3, 1, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(1024, 1024, 3, 1, 1),
nn.LeakyReLU(0.1)
)
self.block7 = nn.Sequential(
nn.Linear(7 * 7 * 1024, 4096),
nn.Linear(4096, 7 * 7 * 30)
)
def forward(self, x):
x = self.block1(x) # (B,3,448,488)-->(B,64,112,112)
x = self.block2(x) # (B,64,112,112)-->(B,192,56,56)
x = self.block3(x) # (B,192,56,56)-->(B,512,28,28)
x = self.block4(x) # (B,512,28,28)-->(B,1024,14,14)
x = self.block5(x) # (B,1024,14,14)-->(B,1024,7,7)
x = self.block6(x) # (B,1024,7,7)-->(B,1024,7,7)
x = torch.flatten(x, 1) # (B,1024,7,7)-->(B,1024*7*7)
x = self.block7(x) # (B,1024*7*7)-->(B,30*7*7)
x = x.view(-1, 30, 7, 7) # (B,30*7*7)-->(B,30,7,7)
return x
def cal_iou(box1, box2):
"""
计算两组box之间的iou
:param box1: tensor (N1, 4) (xmin, ymin, xmax, ymax)
:param box2: tensor (N2, 4) (xmin, ymin, xmax, ymax)
:return: iou (N1, N2) ∈ [0, 1]
"""
box1_area = torch.prod(box1[:, 2:] - box1[:, :2], dim=-1).unsqueeze(dim=1)
box2_area = torch.prod(box2[:, 2:] - box2[:, :2], dim=-1)
box1 = box1.unsqueeze(dim=1)
xymin = torch.maximum(box1[:, :, :2], box2[:, :2])
xymax = torch.minimum(box1[:, :, 2:], box2[:, 2:])
wh = torch.clamp(xymax - xymin, min=0)
intersection_area = torch.prod(wh, dim=-1)
return intersection_area / (box1_area + box2_area - intersection_area)
# [x1,y1,w1,h1,c1, x2,y2,w2,h2,c2, p1,...,p20]
def lossfun(predict, target, lamda_coord=5., lamda_noobj=.5):
"""
损失函数
:param predict: 预测值,(B,30,7,7),
其中30指[x1,y1,w1,h1,c1, x2,y2,w2,h2,c2, p1,...,p20],前10个元素为2个bbox的xywhc参数,后20个元素为20个类别得分
:param target: 真实值,(B,30,7,7)
:param lamda_coord: coordinate损失权重,论文中设为5
:param lamda_noobj: noobj损失权重,论文中设为0.5
:return: 整体损失,对应公式(3)
"""
predict = predict.permute(0, 2, 3, 1) # (B,30,7,7) --> (B,7,7,30)
target = target.permute(0, 2, 3, 1) # (B,30,7,7) --> (B,7,7,30)
batch_size = predict.shape[0] # batch size
obj_index = target[:, :, :, 4] > 0 # 存在obj的坐标(B,7,7)
noobj_index = target[:, :, :, 4] == 0 # 不存在obj的坐标(B,7,7)
pred_obj = predict[obj_index] # 存在obj对应的预测值(L1,30),L1为整个batch中存在obj的cell个数
pred_bbox = pred_obj[:, :10].contiguous().view(-1, 5) # 存在obj对应的预测值的前10个元素,并按5个一行进行排列(L1*2,5)
pred_cls = pred_obj[:, 10:] # 存在obj对应的预测值的后20个元素(L1,20)
target_obj = target[obj_index] # 存在obj对应的真实值(L1,30),L1为整个batch中存在obj的cell个数
target_bbox = target_obj[:, :10].contiguous().view(-1, 5) # 存在obj对应的真实值的前10个元素,并按5个一行进行排列(L1*2,5)
target_cls = target_obj[:, 10:] # 存在obj对应的真实值的后20个元素(L1,20)
pred_noobj = predict[noobj_index] # 不存在obj对应的预测值(L2,30),L2为整个batch中不存在obj的cell个数
target_noobj = target[noobj_index] # 不存在obj对应的真实值(L2,30),L2为整个batch中不存在obj的cell个数
pred_noobj_conf = torch.stack([pred_noobj[:, 4], pred_noobj[:, 9]], dim=1) # 不存在obj对应的预测值的C,(L2,2)
target_noobj_conf = torch.stack([target_noobj[:, 4], target_noobj[:, 9]], dim=1) # 不存在obj对应的真实值的Ci,(L2,2),值为0
noobj_loss = F.mse_loss(pred_noobj_conf, target_noobj_conf, reduction="sum") # 不存在obj的confidence loss
iou_list = [] # 存放iou最大值的列表
respon_index_list = [] # 存放iou最大值的坐标的列表(responsible bbox)
irrespon_index_list = [] # 存放iou非最大值的坐标的列表(irresponsible bbox)
for i in range(0, target_bbox.shape[0], 2): # 循环L1长度,步长为2,因为每个cell有2个bbox
pred_b = pred_bbox[i:i + 2] # 预测值的2个bbox,(2,5)
# 将中心宽高坐标xywh转化为四角坐标xyxy,其中中心点坐标xy是相对于cell做归一化处理,而其他坐标是相对于原图做归一化处理
pred_b_x1y1 = pred_b[:, :2] / 7. - 0.5 * pred_b[:, 2:4] # 左上角坐标
pred_b_x2y2 = pred_b[:, :2] / 7. + 0.5 * pred_b[:, 2:4] # 右下角坐标
pred_b_xyxy = torch.cat([pred_b_x1y1, pred_b_x2y2], dim=-1) # xyxy形式的坐标
target_b = target_bbox[i].unsqueeze(0) # 真实值的1个bbox,(1,5),这里取i和i+1都一样
# 坐标转换
target_b_x1y1 = target_b[:, :2] / 7. - 0.5 * target_b[:, 2:4] # 左上角坐标
target_b_x2y2 = target_b[:, :2] / 7. + 0.5 * target_b[:, 2:4] # 右下角坐标
target_b_xyxy = torch.cat([target_b_x1y1, target_b_x2y2], dim=-1) # xyxy形式的坐标
iou = cal_iou(pred_b_xyxy[:, :4], target_b_xyxy[:, :4]) # 计算iou,(2,1)
value, index = torch.max(iou, dim=0) # 获得最大iou值和对应的index
iou_list.append(value) # 最大iou值添加至列表
respon_index_list.append(i + index) # responsible bbox坐标列表
irrespon_index_list.append(i + 1 - index) # irresponsible bbox坐标列表
respon_c = torch.cat(iou_list, dim=0) # 最大值iou的tensor,对应公式中的Ci,值为IOUmax
index_tensor = torch.cat(respon_index_list, dim=0) # responsible bbox坐标
irrespon_tensor = torch.cat(irrespon_index_list, dim=0) # irresponsible bbox坐标
pred_respon_bbox = pred_bbox[index_tensor] # responsible bbox的预测值
target_respon_bbox = target_bbox[index_tensor] # responsible bbox的真实值
pred_irrespon_bbox = pred_bbox[irrespon_tensor] # irresponsible bbox的预测值
irrespon_c = torch.zeros_like(irrespon_tensor) # irresponsible bbox的真实值的C,对应公式中的Ci,值为0
respon_loss = F.mse_loss(pred_respon_bbox[:, 4], respon_c, reduction="sum") # 存在obj且responsible的confidence loss
irrespon_loss = F.mse_loss(pred_irrespon_bbox[:, 4], irrespon_c,
reduction="sum") # 存在obj但irresponsible的confidence loss
coord_loss = F.mse_loss(pred_respon_bbox[:, :2], target_respon_bbox[:, :2], reduction="sum") + F.mse_loss(
torch.sqrt(pred_respon_bbox[:, 2:4]), torch.sqrt(target_respon_bbox[:, 2:4]),
reduction="sum") # coordinate loss
cls_loss = F.mse_loss(pred_cls, target_cls, reduction="sum") # class loss
return (lamda_coord * coord_loss + # 对应论文公式(3)第1、2行
respon_loss + # 对应论文公式(3)第3行
lamda_noobj * (noobj_loss + irrespon_loss) + # 对应论文公式(3)第4行
cls_loss) / batch_size # 对应论文公式(3)第5行