吴恩达机器学习13-聚类
吴恩达机器学习13-聚类
1.无监督学习
样本不带标记
在监督学习中,数据有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,数据没有附带任何标签。
例如聚类:
2.K-均值算法
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其算法为:
- 首先选择个聚类中心
- 对于数据集中的每一个数据,按照距离个中心点的距离,将其与距离最近的中心点关
联起来,与同一个中心点关联的所有点聚成一类。 - 计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置
重复2、3直到中心点不再发生变化。
代码解释:
用 μ 1 , μ 2 , … , μ k \mu^{1}, \mu^{2}, \ldots, \mu^{k} μ1,μ2,…,μk 来表示聚类中心, 用 c ( 1 ) , c ( 2 ) , … , c ( m ) c^{(1)}, c^{(2)}, \ldots, c^{(m)} c(1),c(2),…,c(m) 来存储与第i个实例数据最近的聚类中心的索引, K-均值算法的伪代码如下:
Repeat {
#对于每一个样例,计算其应该属于的类,选择距离最近的聚类中心
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
#聚类中心的移动,移动到当前簇的平均值下
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
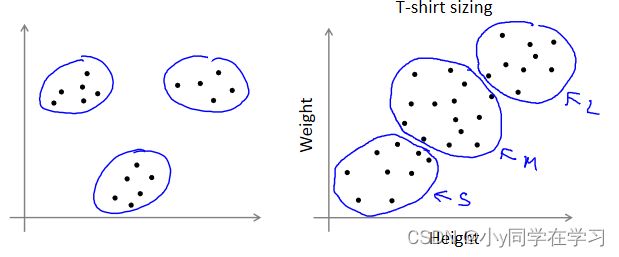
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下也可以。下图所示的数据集包含身高和体重两项特征构成的,利用 K-均值算法将数据分为三类,用于帮助确定将要生产的 T-恤衫的三种尺寸。
3.优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
J ( c ( 1 ) , … , c ( m ) , μ 1 , … , μ K ) = 1 m ∑ i = 1 m ∥ X ( i ) − μ c ( i ) ∥ 2 {\tiny } J\left(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{K}\right)=\frac{1}{m} \sum_{i=1}^{m}\left\|X^{(i)}-\mu_{c^{(i)}}\right\|^{2} J(c(1),…,c(m),μ1,…,μK)=m1∑i=1m∥ ∥X(i)−μc(i)∥ ∥2
其中 μ c ( i ) \mu_{c^{(i)}} μc(i) 代表与 x ( i ) x^{(i)} x(i) 最近的聚类中心点。我们的的优化目标便是找出使得代价函数最小的 c ( 1 ) , c ( 2 ) , … , c ( m ) 和 μ 1 , μ 2 , … , μ k c^{(1)}, c^{(2)}, \ldots, c^{(m)} 和 \mu^{1}, \mu^{2}, \ldots, \mu^{k} c(1),c(2),…,c(m)和μ1,μ2,…,μk :
min c ( 1 ) , … , c ( m ) μ 1 , … , μ K J ( c ( 1 ) , … , c ( m ) , μ 1 , … , μ K ) \min _{\substack{c^{(1)}, \ldots, c^{(m)} \\ \mu_{1}, \ldots, \mu_{K}}} J\left(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{K}\right) minc(1),…,c(m)μ1,…,μKJ(c(1),…,c(m),μ1,…,μK)
回顾K-均值迭代算法可得,第一个循环是用于减小()引起的代价,而第二个循环则是用于减小引起的代价。迭代的过程一定会是每一次迭代都在减小代价函数。
4.随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
- 聚类中心应该选择 < ,即聚类中心点的个数要小于所有训练集实例的数量
- 随机选择个训练实例,令个聚类中心与这个训练实例相等开始训练
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
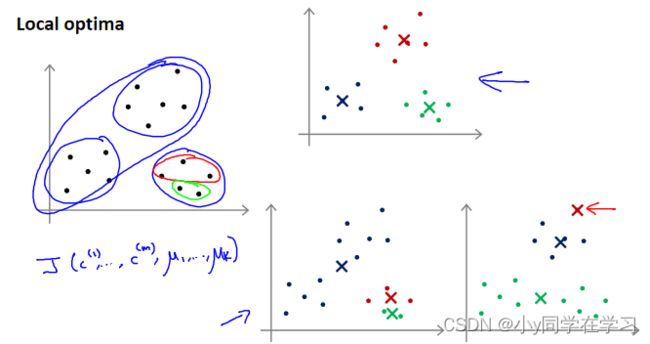
右上方为全局最优,而右下方两个聚类结果则不尽人意。
为了解决这个问题,通常需要多次运行 K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行 K-均值的结果,选择代价函数最小的结果。
TIPS:这种方法在较小的时候(2-10)还是可行的,但是如果较大,这么做也可能不会有明显地改善。
5.选择聚类数
-
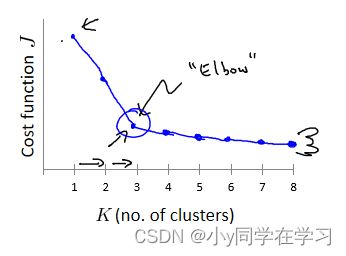
肘部法则:
改变值,也就是聚类类别数目的总数。我们用一个聚类来运行 K 均值聚类方法。
例如下图可选聚类中心K=3:
-
根据实际需要:
T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成 3 个尺寸:, , ,也可以分成 5 个尺寸, , , ,,这样的选择是建立在回答“聚类后我们制造的 T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。