【计算机视觉】OpenCV与FCN图像分割
1 实验要求
任务1:利用OpenCV实现图像分割
- 选择K-means, mean shift, grab cut 中的两种进行图像分割
- 对比两种图像分割方法的好坏
示例:

分割结果对比
参考资料:
https://www.cse.msu.edu/~stockman/CV/F08Lectures/meanShiftSeg.pdf
meanshift segmentation(原理+源码)_hello-elena的博客-CSDN博客
OpenCV GrabCut: Foreground Segmentation and Extraction - PyImageSearch
要求:
- 环境:使用Python(>=3.8)+OpenCV(>=3.4.10)编程实现
- 代码:本次作业用一个py文件,不同的过程分别对应于不同的函数
- 文档:包括算法原理、实验结果、分析和结论、源代码等
- 规范性:注意数学符号、语言陈述、图表公式、排版等的规范性
- 文档命名:学号-姓名-图像分割.pdf
思考题(选):
- 训练一个FCN 模型,并基于FCN完成图像语义分割。
2 实验原理
meanshift是一种特征空间的分析方法,要想利用此方法来解决特定问题,需要将问题映射到特征空间。对于图像分割,可以映射到颜色特征空间,比如将RGB图片映射到Luv颜色特征空间。图像分割问题可以看成对每个像素点求其类中心的问题,其主要步骤可以分为模点搜索和模点聚类两步:模点搜索就是寻找每个数据点的类中心,以中心的颜色代替自己的颜色,从而平滑图像,但模点搜索得到的模点太多,并且很多模点挨得很近,若将每个模点都作为一类的话,类别太多,容易产生过分割,即分割太细,所以要合并掉一些模点;模点聚类顾名思义,聚类后所得到的分割区域中有些区域所包含的像素点太少,这些小区域也不是我们想要的,需要再次合并。
K-Means聚类是一种常用的聚类算法,最初起源于信号处理,其目标是将数据点划分为K个类簇,找到每个簇的中心并使其度量最小化。该算法的最大优点是简单、便于理解,运算速度较快,缺点是只能应用于连续型数据,并且要在聚类前指定聚集的类簇数。其步骤如下:第一步,确定K值,即将数据集聚集成K个类簇;第二步,从数据集中随机选择K个数据点作为质心或数据中心点;第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组;第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心;第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止;第六步,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。在图像处理中,通过K-Means聚类算法可以实现图像分割、图像聚类、图像识别等操作。假设存在一张100×100像素的灰度图像,它由10000个RGB灰度级组成,我们通过K-Means可以将这些像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有的像素点,这样就能实现在不改变分辨率的情况下量化压缩图像颜色,实现图像颜色层级分割。
Grabcut是基于图割(graph cut)实现的图像分割算法,它需要用户输入一个bounding box作为分割目标位置,实现对目标与背景的分离/分割,与K-Means与MeanShift等图像分割方法不同。Grabcut主要优点在于分割速度快,效果好,并支持交互操作。GrabCut算法的实现步骤如下:一,在图片中定义(一个或者多个)包含物体的矩形,矩形外的区域被自动认为是背景,对于用户定义的矩形区域,可用背景中的数据来区分它里面的前景和背景区域;二,用高斯混合模型(GMM)来对背景和前景建模,并将未定义的像素标记为可能的前景或者背景;三,图像中的每一个像素都被看做通过虚拟边与周围像素相连接,而每条边都有一个属于前景或者背景的概率,这是基于它与周边像素颜色上的相似性;四,每一个像素(即算法中的节点)会与一个前景或背景节点连接;五,在节点完成连接后(可能与背景或前景连接),若节点之间的边属于不同终端(即一个节点属于前景,另一个节点属于背景),则会切断他们之间的边,这就能将图像各部分分割出来。
基于卷积神经网络的全卷积分割网络FCN是像素级别的图像语义分割网络,相比以前传统的图像分割方法,基于卷积神经网络的分割更加的精准,适应性更强。FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
3 实验过程
首先采用K-means方法对彩色图像进行颜色分割处理,并且将彩色图像聚集成2类、4类和64类,观察结果。使用经典的lenna图进行测试。
Kmeans.py
# coding: utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像
img = cv2.imread('C:\\Users\\26909\Desktop\lenna.png')
print(img.shape)
#图像二维像素转换为一维
data = img.reshape((-1,3))
data = np.float32(data)
#定义中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#设置标签
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means聚类 聚集成2类
compactness, labels2, centers2 = cv2.kmeans(data, 2, None, criteria, 10, flags)
#K-Means聚类 聚集成4类
compactness, labels4, centers4 = cv2.kmeans(data, 4, None, criteria, 10, flags)
#K-Means聚类 聚集成8类
compactness, labels8, centers8 = cv2.kmeans(data, 8, None, criteria, 10, flags)
#K-Means聚类 聚集成16类
compactness, labels16, centers16 = cv2.kmeans(data, 16, None, criteria, 10, flags)
#K-Means聚类 聚集成64类
compactness, labels64, centers64 = cv2.kmeans(data, 64, None, criteria, 10, flags)
#图像转换回uint8二维类型
centers2 = np.uint8(centers2)
res = centers2[labels2.flatten()]
dst2 = res.reshape((img.shape))
centers4 = np.uint8(centers4)
res = centers4[labels4.flatten()]
dst4 = res.reshape((img.shape))
centers8 = np.uint8(centers8)
res = centers8[labels8.flatten()]
dst8 = res.reshape((img.shape))
centers16 = np.uint8(centers16)
res = centers16[labels16.flatten()]
dst16 = res.reshape((img.shape))
centers64 = np.uint8(centers64)
res = centers64[labels64.flatten()]
dst64 = res.reshape((img.shape))
#图像转换为RGB显示
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dst2 = cv2.cvtColor(dst2, cv2.COLOR_BGR2RGB)
dst4 = cv2.cvtColor(dst4, cv2.COLOR_BGR2RGB)
dst8 = cv2.cvtColor(dst8, cv2.COLOR_BGR2RGB)
dst16 = cv2.cvtColor(dst16, cv2.COLOR_BGR2RGB)
dst64 = cv2.cvtColor(dst64, cv2.COLOR_BGR2RGB)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图像
titles = [u'原始图像', u'聚类图像 K=2', u'聚类图像 K=4',
u'聚类图像 K=8', u'聚类图像 K=16', u'聚类图像 K=64']
images = [img, dst2, dst4, dst8, dst16, dst64]
for i in range(6):
plt.subplot(2,3,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

可以看出当分成两类时K-means算法较为清晰地勾勒出了图像的轮廓,效果较好;随着分类数量的增加,处理后的图像与原始图像也越来越接近。
之后使用meanshift算法进行图像分割:
Meanshift.py
#encoding=gbk
import cv2
img=cv2.imread('C:\\Users\\26909\Desktop\lenna.png')
img=cv2.resize(src=img,dsize=(450,450))
#图像分割
dst=cv2.pyrMeanShiftFiltering(src=img,sp=20,sr=30)
#图像分割(边缘的处理)
canny=cv2.Canny(image=dst,threshold1=30,threshold2=100)
#查找轮廓
conturs,hierarchy=cv2.findContours(image=canny,mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_SIMPLE)
#画出轮廓
cv2.drawContours(image=img,contours=conturs,contourIdx=-1,color=(0,255,0),thickness=3)
cv2.imshow('img',img)
cv2.imshow('dst',dst)
cv2.imshow('canny',canny)
cv2.waitKey(0)
cv2.destroyAllWindows()

可以看出meanshift算法的分割效果也较为明显。
之后使用Tensorflow训练全卷积神经网络FCN,并进行图像语义分割。glob库可以用于读取本地的图片并用来制作每一个batch的数据,数据集放在了D:\Computer_Vision-master\Semantic segmentation\FCN\文件夹中,其中images文件夹里是训练集的图片,annotations文件夹里是人为标注边界的数据集。
链接:https://pan.baidu.com/s/190kOerhN-VLTOT8qv3Rdew?pwd=0294
提取码:0294
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import os
os.listdir(r"D:\Computer_Vision-master\Semantic segmentation\FCN\annotations\trimaps")[-5:]
#第80张人为标注边界的图像
img=tf.io.read_file(r"D:\Computer_Vision-master\Semantic segmentation\FCN\annotations\trimaps\yorkshire_terrier_80.png")
img=tf.image.decode_png(img)
print(img.shape)
plt.imshow(img)
plt.show()

它的原始图片是这样的:

然后制作dataset与batch数据,读取图片文件的函数,包括png和jpg,分别解析为三维矩阵:
import glob
images=glob.glob(r"D:\Computer_Vision-master\Semantic segmentation\FCN\images\*.jpg")
print(len(images))
#7390
#然后读取目标图像
anno=glob.glob(r"D:\Computer_Vision-master\Semantic segmentation\FCN\annotations\trimaps\*.png")
#对读取进来的数据进行制作batch
np.random.seed(2019)
index=np.random.permutation(len(images))
images = np.array(images)[index]
anno = np.array(anno)[index]
# 创建dataset
dataset = tf.data.Dataset.from_tensor_slices((images, anno))
test_count = int(len(images) * 0.2)
train_count = len(images) - test_count
data_train = dataset.skip(test_count)
data_test = dataset.take(test_count)
def read_jpg(path):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
return img
def read_png(path):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, channels=1)
return img
# 现在编写归一化的函数
def normal_img(input_images, input_anno):
input_images = tf.cast(input_images, tf.float32)
input_images = input_images / 127.5 - 1
input_anno -= 1
return input_images, input_anno
# 加载函数
def load_images(input_images_path, input_anno_path):
input_image = read_jpg(input_images_path)
input_anno = read_png(input_anno_path)
input_image = tf.image.resize(input_image, (224, 224))
input_anno = tf.image.resize(input_anno, (224, 224))
return normal_img(input_image, input_anno)
data_train = data_train.map(load_images, num_parallel_calls=tf.data.experimental.AUTOTUNE)
data_test = data_test.map(load_images, num_parallel_calls=tf.data.experimental.AUTOTUNE)
# 现在开始batch的制作
BATCH_SIZE = 3 # 根据显存进行调整
data_train = data_train.repeat().shuffle(100).batch(BATCH_SIZE)
data_test = data_test.batch(BATCH_SIZE)
for img, anno in data_train.take(1):
# take出来的是一个batch的图像
plt.subplot(1, 2, 1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[0]))
plt.subplot(1, 2, 2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(anno[0]))
plt.show()
之后使用VGG16进行卷积,同时使用imagenet的预训练模型进行迁移学习,搭建神经网络和跳级连接。
conv_base = tf.keras.applications.VGG16(weights='imagenet',
input_shape=(224, 224, 3),
include_top=False)
# 现在创建子model用于继承conv_base的权重,用于获取模型的中间输出
# 使用这个方法居然能够继承,而没有显式的指定到底继承哪一个模型,确实神奇
# 确实是可以使用这个的,这个方法就是在模型建立完之后再进行的调用
# 这样就会继续自动继承之前的网络结构
# 而如果定义
sub_model = tf.keras.models.Model(inputs=conv_base.input,
outputs=conv_base.get_layer('block5_conv3').output)
# 现在创建多输出模型,三个output
layer_names = [
'block5_conv3',
'block4_conv3',
'block3_conv3',
'block5_pool'
]
layers_output = [conv_base.get_layer(layer_name).output for layer_name in layer_names]
# 创建一个多输出模型,这样一张图片经过这个网络之后,就会有多个输出值了
# 不过输出值虽然有了,怎么能够进行跳级连接呢?
multiout_model = tf.keras.models.Model(inputs=conv_base.input,
outputs=layers_output)
multiout_model.trainable = False
inputs = tf.keras.layers.Input(shape=(224, 224, 3))
# 这个多输出模型会输出多个值,因此前面用多个参数来接受即可。
out_block5_conv3, out_block4_conv3, out_block3_conv3, out = multiout_model(inputs)
# 现在将最后一层输出的结果进行上采样,然后分别和中间层多输出的结果进行相加,实现跳级连接
# 这里表示有512个卷积核,filter的大小是3*3
x1 = tf.keras.layers.Conv2DTranspose(512, 3,
strides=2,
padding='same',
activation='relu')(out)
# 上采样之后再加上一层卷积来提取特征
x1 = tf.keras.layers.Conv2D(512, 3, padding='same',
activation='relu')(x1)
# 与多输出结果的倒数第二层进行相加,shape不变
x2 = tf.add(x1, out_block5_conv3)
# x2进行上采样
x2 = tf.keras.layers.Conv2DTranspose(512, 3,
strides=2,
padding='same',
activation='relu')(x2)
# 直接拿到x3,不使用
x3 = tf.add(x2, out_block4_conv3)
# x3进行上采样
x3 = tf.keras.layers.Conv2DTranspose(256, 3,
strides=2,
padding='same',
activation='relu')(x3)
# 增加卷积提取特征
x3 = tf.keras.layers.Conv2D(256, 3, padding='same', activation='relu')(x3)
x4 = tf.add(x3, out_block3_conv3)
# x4还需要再次进行上采样,得到和原图一样大小的图片,再进行分类
x5 = tf.keras.layers.Conv2DTranspose(128, 3,
strides=2,
padding='same',
activation='relu')(x4)
# 继续进行卷积提取特征
x5 = tf.keras.layers.Conv2D(128, 3, padding='same', activation='relu')(x5)
# 最后一步,图像还原
preditcion = tf.keras.layers.Conv2DTranspose(3, 3,
strides=2,
padding='same',
activation='softmax')(x5)
model = tf.keras.models.Model(
inputs=inputs,
outputs=preditcion
)
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'] # 此参数用来打印正确率
)
model.fit(data_train,
epochs=1,
steps_per_epoch=train_count // BATCH_SIZE,
validation_data=data_test,
validation_steps=train_count // BATCH_SIZE)

可以看出,当只用了一个epoch时,像素精确度就已经高达88.92%。下面展示该模型的预测结果:
num=3
for image,mask in data_test.take(1):
pred_mask=new_model.predict(image)
pred_mask=tf.argmax(pred_mask,axis=-1)
pred_mask=pred_mask[...,tf.newaxis]
plt.figure(figsize=(10,10))
for i in range(num):
plt.subplot(num,3,i*num+1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(image[i]))
plt.subplot(num,3,i*num+2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(mask[i]))
plt.subplot(num,3,i*num+3)
plt.imshow(tf.keras.preprocessing.image.array_to_img(pred_mask[i]))
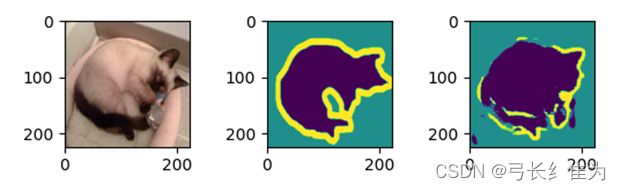

4 分析与结论
在本次实验中,我分别使用了K-means算法和meanshift算法对图像进行分割。K-means算法的思想较为朴素,在理解和实现上都十分简单,但缺点却也十分明显:它十分依赖于初始给定的聚类数目,并且随机初始化可能会生成不同的聚类效果,缺乏重复性和连续性。meanshift算法对此做出了修正,与K-means算法相比最大的优点是我们无需指定指定聚类数目,聚类中心处于最高密度处也是符合直觉认知的结果。但meanshift需要考虑的问题在于如何选取滑窗大小r,这对于结果有着很大的影响。但就本次实验结果来看,两种算法都能较好地识别出图像边界。FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题,相对于传统的图像分割算法,其性能更为优异。
5 参考来源
FCN网络:https://github.com/Geeksongs/Computer_Vision