TOPSIS(逼近理想解)算法原理详解与代码实现
写在前面:
个人理解:针对存在多项指标,多个方案的方案评价分析方法,也就是根据已存在的一份数据,判断数据中各个方案的优劣。中心思想是首先确定各项指标的最优理想值(正理想值)和最劣理想值(负理想解),所谓正理想值是一设想的最好值(方案),它的的各个属性值都达到各候选方案中最好的值,而负理想解是另一设想的最坏的值(方案),然后求出各个方案与正理想值和负理想值之间的加权欧氏距离,由此得出各方案与最优方案的接近程度,作为评价方案的优劣标准,最后得到各个方案的优劣值。
目录
一、TOPSIS算法
1.1 TOPSIS算法的原理
1.2 TOPSIS算法的实现
二、数据预处理
2.1 数据正向化处理
2.1.1对于极小型指标的正向化处理
2.1.2 对于中间型指标的正向化处理
2.1.3对于区间型指标的正向化处理
2.2数据标准化处理
三、TOPSIS算法实现
3.1最优解与最劣解计算
3.2 TOPSIS评分计算
四、TOPSIS算法总结
4.1 TOPSIS算法实现步骤
五、TOPSIS算法示例与扩展
5.1 TOPSIS算法示例
5.2 TOPSIS算法扩展
六、程序源码
由于本文发在知乎上,目前CSDN没办法直接导入文档,所以本文可读性很差。强烈建议点击下面链接阅读原文:
TOPSIS(逼近理想解)算法原理详解与代码实现 - 子木的文章 - 知乎 https://zhuanlan.zhihu.com/p/266689519
TOPSIS(逼近理想解)算法原理详解与代码实现 - 子木的文章 - 知乎
如有专业问题或者需要仿真可以点下面付费咨询链接。
知乎用户www.zhihu.com
一、TOPSIS算法
1.1 TOPSIS算法的原理
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution)可翻译为逼近理想解排序法,国内常简称为优劣解距离法TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
为了对众多方案给出一个排序,在给出所有方案之后,可以根据这些数据,构造出一个所有方案组成的系统中的理想最优解和最劣解。而TOPSIS的想法就是,通过一定的计算,评估方案系统中任何一个方案距离理想最优解和最劣解的综合距离。如果一个方案距离理想最优解越近,距离最劣解越远,我们就有理由认为这个方案更好。那理想最优解和最劣解又是什么呢?很简单,理想最优解就是该理想最优方案的各指标值都取到系统中评价指标的最优值,最劣解就是该理想最劣方案的各指标值都取到系统中评价指标的最劣值。
理想最优解中的数据都是各方案中的数据,而不要选择方案中没有的数据,理想最劣解同理。
如何衡量某一个方案与理想最优解和最劣解的综合距离呢?
TOPSIS基本思想是用下面这个表达式进行衡量:
可以发现,如果方案取到了理想最优解,其表达式取值为1;如果方案取到了理想最劣解,其表达式取值为0。我们便可以用这个表达式来衡量系统中某一个方案距离理想最优解和最劣解的综合距离,也直接用它给方案进行打分。
当然这个公式只是一个基本的思路,实际上,为了更准确与合理,会对该公式进行优化。
1.2 TOPSIS算法的实现
在了解TOPSIS算法的基本思想后就是对相应参数的计算了,从上面的描述可以知道,除了要对该公式进行改进之外,因为涉及到数据之间的比较,还需要对方案数据进行处理,消除量纲以及范围太大带来的一系列问题。
二、数据预处理
2.1 数据正向化处理
在处理数据时,有些指标的数据越大越好,有些则是越小越好,有些又是中间某个值或者某段区间最好。我们可以对其进行“正向化处理”,使指标都可以像考试分数那样,越大越好。
将指标分为四类,如下表所示。
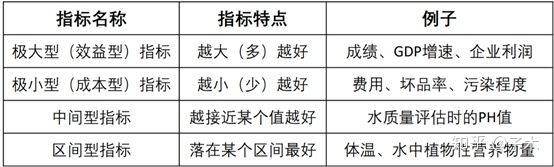
四类指标类型
正向化处理,就是将上述的四种指标数据进行处理,将其全部转化为极大型指标数据,这样我们计算时问题就少一点,码代码时也更加统一。
2.1.1 对于极小型指标的正向化处理
例如费用,我们可以用
![]()
将其转化为极大型,如果所有元素都为正数,也可以使用
![]()
2.1.2 对于中间型指标的正向化处理
如果其最佳数值是
,我们可以取
,之后按照
![]()
转化。

PH值正向化处理
2.1.3 对于区间型指标的正向化处理
对于区间型指标,如果其最佳区间是[a,b],我们取
,之后按照

转化,示例如下。

区间型指标正向化处理
至此,已将所有的数据都转化为极大型数据了。
2.2 数据标准化处理
为了消除不同的数据指标量纲的影响,我们还有必要对已经正向化的矩阵进行标准化。在概率统计中,标准化的方法一般是
,不过这里我们不采用。记标准化后的矩阵为Z,其中
,也就是
。
对数据进行了相应的处理后,可以用向量
来表达第i个方案。假设有n个待评价的方案,m个指标,此时
。由这n个向量构成的矩阵也就是我们的标准化矩阵Z了。

经过了正向化处理和标准化处理的评分矩阵Z,里面的数据全部是极大型数据。
三、TOPSIS算法实现
3.1 最优解与最劣解计算
经过了正向化处理和标准化处理的评分矩阵Z,里面的数据全部是极大型数据。我们就可以从中取出理想最优解和最劣解。因此我们取出每个指标,即每一列中最大的数,构成理想最优解向量,即
![]()
同理,取每一列中最小的数计算理想最劣解向量:
![]()
就是
,
就是
。
在得到理想最优解和理想最劣解的基础上就能计算每个方案的评分了。根据上面的距离评分公式:
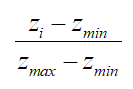
对其进行变型,也就是:
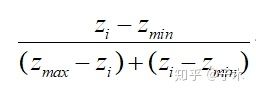
变型的目的是为了使用欧几里得距离来衡量两个方案的距离,变形前后分母的计算结果其实是不同的(因为这里zi是一个向量)。这样更能体现出是综合距离。否则所有方案计算得分时分母都是相同的,相当于只衡量了分子,也就是距离最劣解的距离。
3.2 TOPSIS评分计算
于是计算距离评分:
对于第i个方案zi,我们计算它与最优解的距离:

与最劣解的距离:
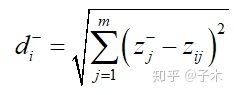
定义第i个方案的评分为Si:

也就是前面提到的综合距离。
,且
越小,也就是该方案与最优解的距离越小时,
越大;相应的,
越小,也就是该方案与最劣解的距离越小时,
越小。 为同时兼顾了该方案与最优解与最劣解的距离的评分。
这个时候我们就有了每个方案的分数了,按分数排排序,就知道哪个方案比较好哪个方案比较差。
四、TOPSIS算法总结
4.1 TOPSIS算法实现步骤
1.将原始数据矩阵正向化。也就是将那些极小性指标,中间型指标,区间型指标对应的数据全部化成极大型指标,方便统一计算和处理。
2.将正向化后的矩阵标准化。也就是通过标准化消除量纲的影响。
3.计算每个方案各自与最优解和最劣解的距离:
与最优解的距离:
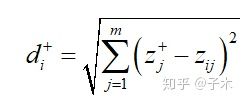
与最劣解的距离:
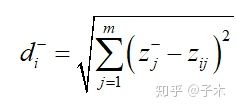
4.根据最优解与最劣解计算得分并排序
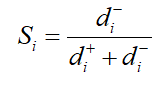
五、TOPSIS算法示例
5.1 TOPSIS算法示例
对一个需要根据学生智商和情商进行排名的数据:原始数据矩阵如下
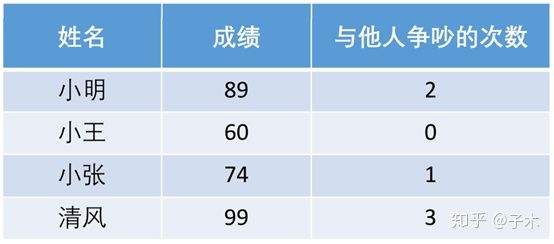
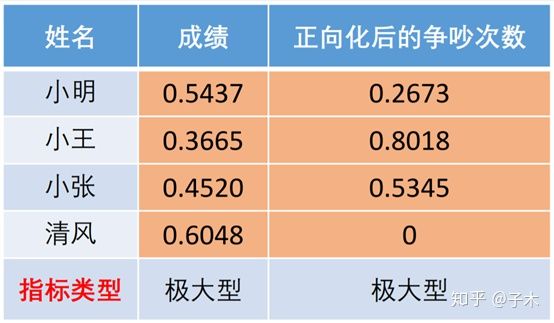
对其进行正向化:

对其进行标准化:
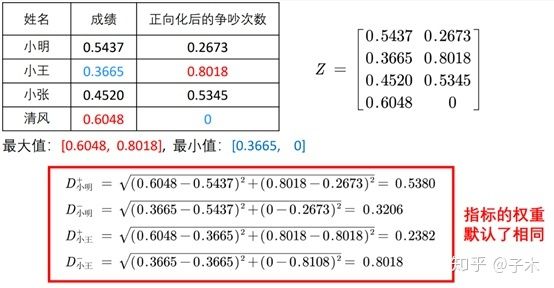
计算与最优解和最劣解的距离:
最后计算得分给出排名:
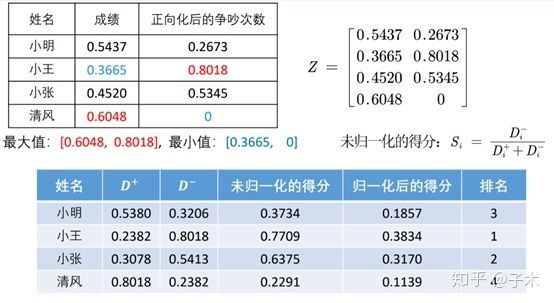
这个例子告诉我们,成绩很重要,但是情商更重要。小王虽然只考了60分,但也及格了,而且他从不与人争吵,所以我们可以给他一个最好的评价。
5.2 TOPSIS算法扩展
从上面计算各自与最优解和最劣解的距离时,我们看到,每一项指标的权重是一样的。
在实际问题中,不同的指标重要程度可能是不一样的。例如评奖学金的时候,成绩往往是最重要的,之后还有参与活动分,志愿服务分等等,他们的权重又低一点。因此,在实际的应用中,我们也可以给指标进行赋权,将权重放到计算距离的公式中。

考虑权重后,不同指标对最后的影响不一样,考虑权重的评价往往是实际生活中很常见的一种评价方式。
关于权重的选取也有不同的方法,比如层次分析法(主观给出)、熵权法等等。
六、程序源码
TOPSIS.m程序
-
clear all -
clc -
%% 导入数据 -
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X -
% (2)双击进入X,输入或拷贝数据到X -
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件 -
% (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。 -
load data_water_quality.mat -
%% 数据预处理_正向化 -
[n,m] = size(X); -
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标']) -
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']); -
if Judge == 1 -
Position = input('请输入需要正向化处理的指标所在的列,例如[2,3,6]: '); %[2,3,4] -
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ') -
Type = input('例如[1,3,2]: '); %[2,1,3] -
% 注意,Position和Type是两个同维度的行向量 -
for i = 1 : size(Position,2)%对每一列进行正向化处理 -
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i)); -
% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) -
% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型) -
% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列 -
% 返回值返回正向化之后的指标 -
end -
disp('正向化后的矩阵 X = ') -
disp(X) -
end -
%% 数据预处理_标准化 -
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1); -
disp('标准化矩阵 Z = ') -
disp(Z) -
%% 指标权重赋值 -
disp("请输入是否需要增加权重向量,需要输入1,不需要输入0") -
Judge = input('请输入是否需要增加权重: '); -
if Judge == 1 -
disp(['有多少个指标就输入多少个权重数(权重和为1),如[0.25,0.25,0.5]']); -
weigh = input(['请输入输入' num2str(m) '个权重: ']); -
if abs(sum(weigh) - 1)<0.000001 && size(weigh,1) == 1 && size(weigh,2) == m % 这里要注意浮点数的运算是不精准的。 -
else -
weigh = input('你输入的有误,请重新输入权重行向量: '); -
end -
else -
weigh = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m -
end -
%% 计算与最大值的距离和最小值的距离,并算出得分 -
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5; % D+ 与最大值的距离向量 -
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5; % D- 与最小值的距离向量 -
S = D_N ./ (D_P+D_N); % 未归一化的得分 -
disp('最后的得分为:') -
stand_S = S / sum(S)% 归一化的得分 -
[sorted_S,index] = sort(stand_S ,'descend')%对得分进行排序并返回原来的位置 -
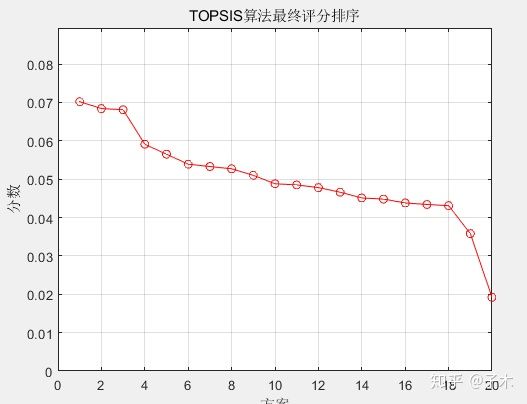
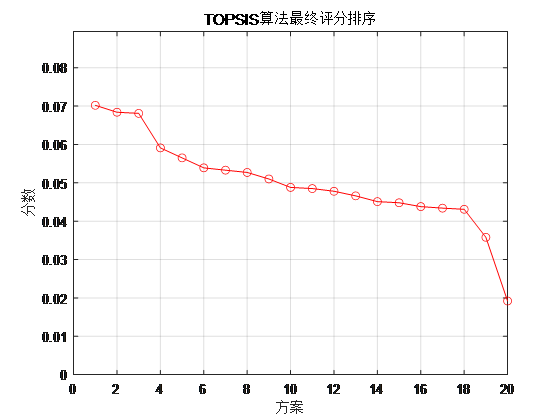
plot(sorted_S,'r-o') -
xmin=1;xmax = size(sorted_S,1); -
ymin = 0;ymax = max(sorted_S)+min(sorted_S); -
axis([xmin xmax ymin ymax]); % 设置坐标轴在指定的区间 -
grid on -
xlabel('方案');ylabel('分数');%坐标轴表示对bai象标签 -
title('TOPSIS算法最终评分排序')
正向化处理函数Positivization.m程序
-
function [posit_x] = Positivization(x,type,i) -
% 输入变量有三个: -
% x:需要正向化处理的指标对应的原始列向量 -
% type: 指标的类型(1:极小型, 2:中间型, 3:区间型) -
% i: 正在处理的是原始矩阵中的哪一列 -
% 输出变量posit_x表示:正向化后的列向量 -
if type == 1 %极小型 -
disp(['第' num2str(i) '列是极小型,正在正向化'] ) -
posit_x = Min2Max(x); %调用Min2Max函数来正向化 -
disp(['第' num2str(i) '列极小型正向化处理完成'] ) -
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~') -
elseif type == 2 %中间型 -
disp(['第' num2str(i) '列是中间型'] ) -
best = input('请输入最佳的那一个值(中间的那个值): '); -
posit_x = Mid2Max(x,best); -
disp(['第' num2str(i) '列中间型正向化处理完成'] ) -
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~') -
elseif type == 3 %区间型 -
disp(['第' num2str(i) '列是区间型'] ) -
a = input('请输入区间的下界: '); -
b = input('请输入区间的上界: '); -
posit_x = Inter2Max(x,a,b); -
disp(['第' num2str(i) '列区间型正向化处理完成'] ) -
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~') -
else -
disp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值') -
end -
end
以下面这个例子为例:
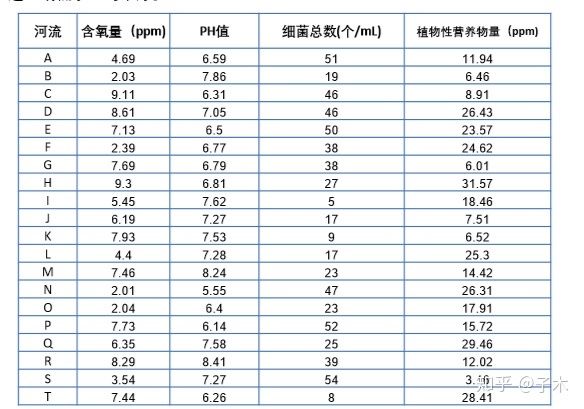
首先导入数据,然后运行程序,结果如下: