动手学数据分析Task5第三章 模型搭建和评估--建模
第三章 模型搭建和评估--建模
经过前面的两章的知识点的学习,我可以对数数据的本身进行处理,比如数据本身的增删查补,还可以做必要的清洗工作。那么下面我们就要开始使用我们前面处理好的数据了。这一章我们要做的就是使用数据,我们做数据分析的目的也就是,运用我们的数据以及结合我的业务来得到某些我们需要知道的结果。那么分析的第一步就是建模,搭建一个预测模型或者其他模型;我们从这个模型的到结果之后,我们要分析我的模型是不是足够的可靠,那我就需要评估这个模型。今天我们学习建模,下一节我们学习评估。
我们拥有的泰坦尼克号的数据集,那么我们这次的目的就是,完成泰坦尼克号存活预测这个任务。载入这些库,如果缺少某些库,请安装他们:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小【思考】这些库的作用是什么呢?你需要查一查
- Pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
- NumPy(Numerical Python)是Python的一种开源的数值计算扩展,提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库,专为进行严格的数字处理而产生。
- Matplotlib是python中的一个包,主要用于绘制2D图形(当然也可以绘制3D,但是需要额外安装支持的工具包)。在数据分析领域它有很大的地位,而且具有丰富的扩展,能实现更强大的功能。
3.1 载入我们提供清洗之后的数据(clear_data.csv),大家也将原始数据载入(train.csv),说说他们有什么不同
clear_data = pd.read_csv('./clear_data.csv')
train = pd.read_csv('./train.csv')
clear_data.head()
train.head()输出:
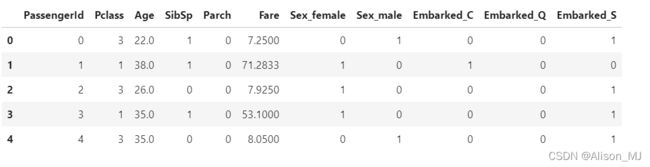
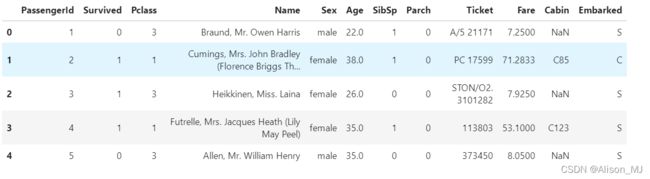
clear_data:
- 已删除无关的特征值Name、Ticket
- 删除了缺失值占大多数的特征值Cabin
- 将离散数值已归一化
- 已将结果Survived分离出用以之后建模
train:
- 原始数据,未进行数据清理
3.2 模型搭建
- 处理完前面的数据我们就得到建模数据,下一步是选择合适模型
- 在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习
- 模型的选择一方面是通过我们的任务来决定的。
- 除了根据我们任务来选择模型外,还可以根据数据样本量以及特征的稀疏性来决定
- 刚开始我们总是先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型
【思考】数据集哪些差异会导致模型在拟合数据是发生变化
1. 样本数多少,有限的训练数据可能会导致训练出的模型出现过度拟合的现象,模型的泛化能力较差。
2. 特征值的多少。
3. 异常值、噪音干扰过大,让模型过分记住了噪音的特征,忽略了正常值输入输出的关系。
4. 训练集和测试集的特征分布是否一致。
3.2.1 任务一:切割训练集和测试集
这里使用留出法划分数据集
- 将数据集分为自变量和因变量
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
【思考】
- 划分数据集的方法有哪些?
- 为什么使用分层抽样,这样的好处有什么?
1. 划分数据集的方法:
- 方法一:使用函数train_test_split用以随机取样,适用于数据集较大的情况
X_train,X_test, y_train, y_test =sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.4, random_state=0,stratify=y_train)train_test_split详解 :sklearn的train_test_split()各函数参数含义解释(非常全) - The-Chosen-One - 博客园
https://blog.csdn.net/qq_38233659/article/details/101553277
- 方法二:使用函数StratifiedShuffleSplit进行分层取样,适用于存在严重的数据不平衡的数据集,使训练集/验证集的划分要尽可能保持数据分布的一致性,尽量减少因数据划分过程引入额外的偏差而对最终结果产生的影响。
2. 分割训练集与测试集步骤:(回顾之前数据处理的过程,重新对train进行数据清洗后用于建模)
(1) 首先,处理缺失值:
train['Age']=train['Age'].fillna(train['Age'].median())
train = train.drop(['Cabin'],axis=1)
train = train.dropna(subset=['Embarked'],axis=0)(2)去除无关特征值:
train_clean = train.drop(['Name','Ticket','PassengerId'],axis=1)(3)归一化处理:
Pclass=pd.get_dummies(train_clean['Pclass'],prefix='Pclass')
Sex=pd.get_dummies(train_clean['Sex'],prefix='Sex')
SibSp=pd.get_dummies(train_clean['SibSp'],prefix='SibSp')
Parch=pd.get_dummies(train_clean['Parch'],prefix='Parch')
Embarked=pd.get_dummies(train_clean['Embarked'],prefix='Embarked')
train_clean=pd.concat([train_clean.drop(['Pclass','Sex','SibSp','Parch','Embarked'],axis=1),Pclass,Sex,SibSp,Parch,Embarked],axis=1)
train_clean.head()输出:

(4)数据标准化处理:
number = ['Age','Fare']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_clean[number] = scaler.fit_transform(train_clean[number])(5)分割训练集与测试集:
#方法一:用train_test_split()
from sklearn.model_selection import train_test_split
X = train_clean.drop(['Survived'],axis=1)
Y = train_clean['Survived']
train_x, test_x, train_y, test_y = train_test_split(X,Y,test_size=0.2,random_state=42)
#方法二:使用StratifiedShuffleSplit()
from sklearn.model_selection import StratifiedShuffleSplit
s = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) #把数据集随机分,最后得到的训练集/测试集对是1组
for train_index, test_index in s.split(train_clean, train_clean["Survived"]):#需要分层抽样元原数据 和 需在此分层基础上的数据
strat_train_set = train_clean.loc[train_index]
strat_test_set = train_clean.loc[test_index]
for set in (strat_train_set, strat_test_set):
set.drop(["Survived"], axis=1, inplace=True)【思考】什么情况下切割数据集的时候不用进行随机选取
数据集较大,样本分布较为均匀。
3.2.2 任务二:模型创建
- 创建基于线性模型的分类模型(逻辑回归)
- 创建基于树的分类模型(决策树、随机森林)
- 分别使用这些模型进行训练,分别的到训练集和测试集的得分
- 查看模型的参数,并更改参数值,观察模型变化
提示
- 逻辑回归不是回归模型而是分类模型,不要与
LinearRegression混淆 - 随机森林其实是决策树集成为了降低决策树过拟合的情况
- 线性模型所在的模块为
sklearn.linear_model - 树模型所在的模块为
sklearn.ensemble
1. 随机森林:
#建模
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
forest_clf.fit(train_x,train_y)
#输出:
RandomForestClassifier(random_state=42)#查看训练集和测试集score:
print("Training set score: {:.2f}".format(forest_clf.score(train_x, train_y)))
print("Testing set score: {:.2f}".format(forest_clf.score(test_x, test_y)))
#输出:
Training set score: 0.98
Testing set score: 0.75可以看出random forest在训练集上的分数高达0.98,而测试集仅有0.75,现更改参数n_estimators,max_depth:
forest_clf2 = RandomForestClassifier(n_estimators=100, max_depth=5)
forest_clf2.fit(train_x, train_y)
#输出:
RandomForestClassifier(max_depth=5)#查看训练集和测试集的score:
print("Training set score: {:.2f}".format(forest_clf2.score(train_x, train_y)))
print("Testing set score: {:.2f}".format(forest_clf2.score(test_x, test_y)))
#输出:
Training set score: 0.85
Testing set score: 0.80可以看出虽然在train上的score降低了,但在test上的score升高了。
2. 逻辑回归:
#公式:
LogisticRegression(
penalty='l2',
*,
dual=False,
tol=0.0001,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver='lbfgs',
max_iter=100,
multi_class='auto',
verbose=0,
warm_start=False,
n_jobs=None,
l1_ratio=None,
)#建模
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=42)
lr_clf.fit(train_x,train_y)
#输出:
LogisticRegression(random_state=42)# 查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr_clf.score(train_x, train_y)))
print("Testing set score: {:.2f}".format(lr_clf.score(test_x, test_y)))
#输出:
Training set score: 0.81
Testing set score: 0.81可以看逻辑回归模型的score在train和test中都达到了0.81,现在更改参数c=100:
#调整参数
lr_clf = LogisticRegression(C=100,random_state=42)
lr_clf.fit(train_x,train_y)
#输出:
LogisticRegression(C=100, random_state=42)# 查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr_clf2.score(train_x, train_y)))
print("Testing set score: {:.2f}".format(lr_clf2.score(test_x, test_y)))
#输出:
Training set score: 0.81
Testing set score: 0.82可以看逻辑回归模型的score在test中上升到了0.82。
3.2.3 任务三:输出模型预测结果
- 输出模型预测分类标签
- 输出不同分类标签的预测概率
1. 随机森林
#predict()
forest_predict = forest_clf.predict(train_x)
forest_predict[:10]
#输出:
array([1, 0, 0, 0, 0, 0, 0, 0, 0, 1], dtype=int64)
#predict_proba()
forest_pred_pr = forest_clf.predict_proba(train_x)
forest_pred_pr[:10]
#输出:
array([[0. , 1. ],
[0.9 , 0.1 ],
[0.96, 0.04],
[0.99, 0.01],
[1. , 0. ],
[0.8 , 0.2 ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0.38, 0.62]])2. 逻辑回归
#predict()
lr_predict = lr_clf.predict(train_x)
lr_predict[:10]
#输出:
array([1, 1, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int64)
#predict_proba()
lr_pred_pr = lr_clf.predict_proba(train_x)
lr_pred_pr[:10]
#输出:
array([[0.05543158, 0.94456842],
[0.29285178, 0.70714822],
[0.9245138 , 0.0754862 ],
[0.79121241, 0.20878759],
[0.95074891, 0.04925109],
[0.58191983, 0.41808017],
[0.89122519, 0.10877481],
[0.91249951, 0.08750049],
[0.91249951, 0.08750049],
[0.54714094, 0.45285906]])【思考】预测标签的概率对我们有什么帮助
predict_proba返回的是一个n行k列的数组,第i行第j列上的数值是模型预测第i个预测样本的标签为j的概率,所以每一行的和应该等于1。