<Learning Spatio-Temporal Transformer for Visual Tracking>--阅读理解-cvpr2021
摘要
在本文中,我们提出了一种新的跟踪架构,其中的编码器-解码器transformer为关键组件。 编码器对目标对象和搜索区域之间的全局时空特征相关性进行建模,而解码器学习嵌入的查询以预测目标对象的空间位置。 我们的方法将目标跟踪转换为直接边界框预测问题,而无需使用任何建议或预定义锚。 使用编解码器变压器,对象的预测仅使用简单的全卷积网络,该网络可以直接估计对象的拐角。 整个方法是端到端的,不需要任何余弦窗口和边界框平滑之类的后处理步骤,从而大大简化了现有的跟踪管道。 拟议的跟踪器在五个具有挑战性的短期和长期基准测试中实现了最先进的性能,同时以实时速度运行,比Siam R-CNN快6倍[47]。
代码和模型在这里是开源的。
1. Introduction
视觉目标跟踪是计算机视觉中一个基本但具有挑战性的研究主题。 在过去的几年中,基于卷积神经网络,目标跟踪取得了显着进展[25,9,47]。 但是,卷积核并不擅长对图像内容和特征的长期依赖性进行建模,因为它们仅处理空间或时间上的局部邻域。 当前流行的跟踪器,包括离线Siamese跟踪器和在线学习模型,几乎都基于卷积运算[2,37,3,47]。 结果,这些方法仅在对图像内容的局部关系建模时表现良好,但仅限于很难收集到全局信息。 这种缺陷可能会降低处理全局情境信息对于定位目标对象(例如经历大规模变化或频繁进出视图的对象)很重要的场景时模型的能力。
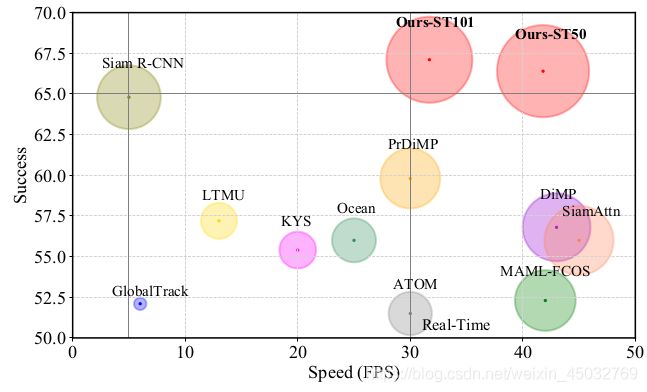
图1:与LaSOT上的最新技术比较[13]。我们以每秒帧数(fps)跟踪速度可视化了成功性能。Ours-ST101和Ours-ST50分别以ResNet-101和ResNet-50为骨干,表明了建议的跟踪器。 彩色效果更好。
通过使用Transformer,在序列建模中解决了远程相互作用的问题[46]。
Transformer在诸如自然语言建模[11,39]和语音识别[34]等任务中获得了巨大的成功。 最近,在判别式计算机视觉模型中使用了变压器,并引起了极大的关注[12、5、35]。 受最近的DEtection TRans-former (DETR)的启发[5],我们提出了一种新的具有编码器-解码器transformer的端到端跟踪架构,以提高传统卷积模型的性能。
空间和时间信息对于目标跟踪都很重要。 前者包含用于目标定位的对象外观信息,而后者包含跨帧的对象的状态变化。 先前的Siamese跟踪器[25、51、14、6]仅利用空间信息进行跟踪,而在线方法[54、57、9、3]使用历史预测进行模型更新。 尽管成功,但这些方法并未显式地建模时空之间的关系。 在这项工作中,考虑到建模全局依赖项的出色能力,我们求助于转换器将空间和时间信息进行集成,以进行跟踪,生成可区分的时空特征以进行目标定位。
更具体地说,**我们提出了一种基于编码器-解码器Transformer的新型时空架构,**用于视觉跟踪。 新架构包含三个关键组件:编码器en,de解码器和预测pre-head头。
编码器接受初始目标对象,当前图像和动态更新的模板的输入。 编码器中的自注意模块通过它们的功能依赖性来学习输入之间的关系。
由于模板图像在整个视频序列中都会更新,因此编码器可以捕获目标的空间和时间信息。 解码器学习嵌入查询以预测目标对象的空间位置的查询。 基于角点的预测头用于估计当前帧中目标对象的边界框。
同时,学习得分的head去控制动态模板img的更新。
大量实验表明,我们的方法在短期[18,36]和长期跟踪基准[13,22]上都建立了新的最新性能。
例如,我们的时空transformer跟踪器在GOT-10K [18]和LaSOT [13]上分别比Siam R-CNN [47]高3.9%(AO得分)和2.3%(成功)。
还值得注意的是,与以前的长期跟踪器相比[8,47,53],我们方法的框架要简单得多。 具体而言,先前的方法通常由多个组件组成,例如基本跟踪器[9、50],目标验证模块[21]和全局检测器[40、19]。 相反,我们的方法只有一个以端到端的方式学习的网络。 此外,我们的跟踪器可以在Tesla V100 GPU上以实时速度运行,比Siam R-CNN(30幅5 fps)快6倍,如图1所示。总而言之,这项工作有三点贡献。
总而言之,这项工作有三点贡献:
•我们提出了专门用于视觉跟踪的新型Transformer架构。 它能够捕获视频序列中空间和时间信息的全局特征依赖性。
•整个方法是端到端的,不需要任何后处理步骤,例如余弦窗口和边界框平滑处理,从而大大简化了现有的跟踪管道。
•拟议的跟踪器以实时运行的速度,通过五个具有挑战性的短期和长期基准,实现了最先进的性能。
2. Related Work
Transformer in Language and Vision.
Spatio-Temporal Information Exploitation.
时空信息的利用是目标跟踪领域的核心问题。
现有的跟踪器可以分为两类:仅空间跟踪器和时空跟踪器。
大多数离线Siames跟踪器[2、26、25、60、29]属于仅空间跟踪器,它们将对象跟踪视为初始模板和当前搜索区域之间的模板匹配。 为了提取沿空间维度的模板与搜索区域之间的关系,大多数跟踪器采用了相关性的变体,包括the naive correlation[2,26],深度相关性[25,60]和点状相关性 [29,52]。 尽管近年来取得了显着进展,但这些方法仅捕获了局部相似性,而忽略了全局信息。 相比之下,Transformer中的自注意力机制可以捕获远程关系,因此适合成对匹配任务。 与仅空间跟踪器相比,时空跟踪器还利用时间信息来提高跟踪器的鲁棒性 这些方法也可以分为两类:基于梯度的方法和无梯度的方法。 基于梯度的方法需要在推理过程中进行梯度计算。 MDNet [37]是经典著作之一,它利用梯度下降更新了特定领域的图层。 为了提高优化效率,以后的工作[9,3,27,48,55]采用了更高级的优化方法,例如高斯-牛顿法或基于元学习的更新策略。 但是,许多用于部署深度学习的实际设备不支持反向传播,这限制了基于梯度的方法的应用。 相反,无梯度方法在实际应用中具有更大的潜力。 一类无梯度方法[54,57]利用额外的网络来更新暹罗跟踪器的模板[2,61]。 另一个有代表性的工作LTMU [8]学习了一个元更新器,以预测当前状态是否足够可靠,可以用于长期跟踪中的更新。 尽管有效,但这些方法导致时空分离。 相比之下,我们的方法将空间和时间信息整体整合在一起,并通过转换器同时学习它们。
Tracking Pipeline and Post-processing.
先前跟踪器[25、51、60、47]的跟踪管道很复杂。 具体来说,他们首先生成具有置信度得分的大量框提议,然后使用各种后处理来选择最佳边界框作为跟踪结果。 常用的后处理包括余弦窗口,比例或宽高比罚分,边界框平滑,基于轨迹的动态编程等。尽管它带来更好的结果,但后处理会使性能对超参数敏感。 有一些跟踪器[16,19]试图简化跟踪管道,但是它们的性能仍然远远落后于最新的跟踪器。 这项工作试图弥补这一差距,并通过预测每一帧中的单个边界框来获得最佳性能。
3. Method
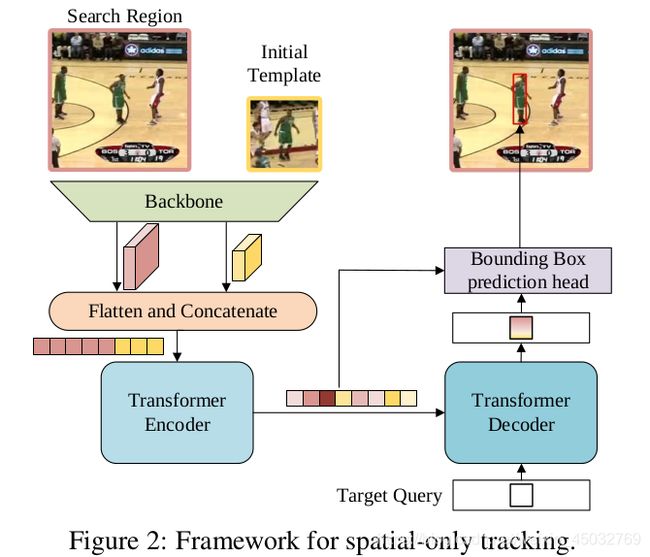
在本节中,我们提出了用于视觉跟踪的时空Transformer网络,称为STARK。 为了清楚起见,我们首先介绍一种简单的baseline方法,该方法直接将原始的编码器/解码器Transformer应用于跟踪。 基准线方法仅考虑空间信息并获得令人印象深刻的性能。 之后,我们扩展baseline以学习用于目标定位的空间和时间表示。 我们引入了动态模板和更新控制器来捕获目标对象的外观变化。
3.1. A Simple Baseline Based on Transformer
我们提出了一个基于视觉tfer的简单基线框架,用于对象跟踪。 该网络架构如图2所示。它主要由三个组件组成:卷积骨干,编码器-解码器tfer和边界框预测头。
- backbone
我们的方法可以使用任意卷积网络作为特征提取的主干。 在不失一般性的前提下,我们采用修改过的ResNet [15]作为backbone。 更具体地说,除了删除最后一级和完全连接的层之外,原始ResNet [15]没有其他更改。 骨干的输入是一对图像:初始目标对象z∈R 3×H z×W z的模板图像和当前帧x∈R 3×H x×W x的搜索区域。 经过主干后,模板z和搜索图像x被映射到两个特征图f z∈R C×Hz/s×Hz/s和f x∈R C×Hx/s×Hx/s。- 编码器encoder
从主干输出的特征图需要先进行预处理,然后再输入编码器。 具体而言,首先使用瓶颈层将通道数从C减少到d。 然后,将特征图展平并沿着空间维度进行级联,以生成长度为H s z W s z + H s x W s x且维度为d的特征序列,将其作为变压器编码器的输入。 该编码器由N个编码器层组成,每个编码器层均由具有前馈网络的多头自注意模块组成。 由于原始变换器的排列不变性[46],我们在输入序列中添加了正弦位置嵌入。
编码器捕获序列中所有元素之间的特征依存关系,并使用全局上下文信息增强原始特征,从而使模型可以学习区分特征以进行对象定位。 - 解码器decoder
解码器将目标查询和来自编码器的增强功能序列作为输入。
与采用100个对象查询的DETR [5]不同,我们仅向解码器输入一个查询即可预测目标对象的一个边界框。 此外,由于只有一个预测,因此我们删除了DETR中用于预测关联的匈牙利算法[24]。 与编码器类似,解码器堆叠M个解码器层,每个解码器层由一个自我注意,一个编码器-解码器注意和一个前馈网络组成。 在编码器-解码器注意模块中,目标查询可以关注模板和搜索区域特征上的所有位置,从而为最终的边界框预测学习可靠的表示形式。 - Head
DETR [5]采用三层感知器来预测对象框坐标。 但是,正如GFLoss [28]指出的那样,直接回归坐标等效于拟合Dirac delta分布,该分布无法考虑数据集中的歧义和不确定性。 这种表示方式不灵活,并且对诸如目标跟踪中的遮挡和背景混乱等挑战并不稳健。 为了提高框估计的质量,我们通过估计框角的概率分布来设计一个新的预测头。 如图3所示,我们首先从编码器的输出序列中获取搜索区域特征,然后计算搜索区域特征与解码器的输出嵌入之间的相似度。
接下来,将相似性得分与搜索区域特征逐元素相乘,以增强重要区域并削弱较不具有区别性的区域。 新的特征Ws Hs序列被重塑为特征图f∈R d×s×s,然后馈入简单的全卷积网络(FCN)。
FCN由L个堆叠的Conv-BN-ReLU层组成,并分别为对象边界框的左上角和右下角输出两个概率图P tl(x,y)和P br(x,y)。 最后,通过计算等式中角的概率分布的期望值,获得预测的框坐标(c x tl,y c c tl)和(x br,y c br)。 (1)。 与DETR相比,我们的方法显式地对坐标估计中的不确定性进行建模,从而生成更准确,更可靠的对象跟踪预测。
- 编码器encoder
- Training and Inference.
我们的基线跟踪器是像DETR一样,以“ L1”和广义IoU损失[41]的组合进行端到端train的。 损失函数可以写成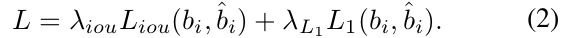

其中b i和b̂ i分别代表地面真实性和预测框,而λiou,λL 1∈R是超参数。
但是与DETR不同,我们不使用分类损失和匈牙利算法,从而进一步简化了训练过程。 在推理期间,模板图像及其来自主干的特征由第一个帧初始化,并固定在随后的帧中。 在跟踪过程中,在每个帧中,网络均以当前帧中的搜索区域作为输入,并返回预测框作为最终结果,而无需使用任何余弦窗口或边界框平滑处理。
3.2. Spatio-Temporal Transformer Tracking
由于目标物体的外观可能会随着时间的流逝而发生显着变化,因此捕获目标的最新状态以进行跟踪非常重要。 在本节中,我们演示如何基于先前介绍的基准同时利用空间和时间信息。 做出了三个关键的区别,包括网络输入,额外的得分头score-head以及训练和推理策略。 我们对它们进行如下详细介绍。 时空架构如图4所示。

- 输入
与仅使用第一帧和当前帧的基线方法不同,时空方法引入了从中间帧采样的动态更新模板作为附加输入,如图4所示。 动态模板可以捕获目标外观随时间的变化,从而提供其他时间信息。 与Sec中的基准架构相似。 如图3.1所示,将三元组的特征图展平并连接起来,然后发送到编码器。 编码器通过在空间和时间维度上对所有元素之间的全局关系进行建模来提取可区分的时空特征。 - Head
在跟踪期间,在某些情况下不应更新动态模板。 例如,当目标已完全被遮挡或已移出视线时,或者当跟踪器漂移时,裁剪后的模板是不可靠的。 为简单起见,我们认为只要搜索区域包含目标,就可以更新动态模板。 为了自动确定当前状态是否可靠,我们添加了一个简单的得分预测头,该头是三层感知器,然后是Sigmoid型激活。 如果分数高于阈值τ,则认为当前状态可靠。 - Training and Inference.
正如最近的工作所指出的[7,43],联合学习定位和分类可能会导致两个任务的解决方案都不理想,这有助于解耦本地化和分类。 因此,我们将训练过程分为两个阶段,将本地化作为主要任务并将分类作为次要任务。 具体来说,在第一步中,除了得分头外,整个网络仅通过等式中与本地化相关的损失进行端到端的训练。 在此阶段,我们确保所有搜索图像都包含目标对象,并让模型学习定位能力。 在第二阶段,只有得分头被优化,二进制交叉熵损失定义为

其中yi是gt,Pi是预测的置信度,所有其他参数都被冻结以避免影响定位能力。 通过这种方式,最终模型在经过两阶段训练后将学习定位和分类功能。
在预测期间,在第一帧中初始化两个模板和相应的特征。 然后,将搜索区域裁剪并馈入网络,生成一个边界框和一个置信度分数。 仅当达到更新间隔并且置信度得分高于阈值τ时,才更新动态模板。 为了提高效率,我们将更新间隔设置为Tu帧。 从原始图像中裁剪出新模板,然后将其输入到主干以进行特征提取。
4.实验
首先介绍实施细节和我们在多个基准上的STARK跟踪器的结果,并与最新方法进行比较。 然后,进行了消融研究,以分析所提议网络中关键组件的影响。 我们还报告了其他候选框架的结果,并将其与我们的方法进行比较以证明其优越性。 最后,提供了编码器和解码器注意图上的可视化视图,以了解Tramsformer的工作原理。
4.1. Implementation Details
用在ImageNet上预训练的参数初始化主干。 BatchNorm [20]层在训练过程中被冻结。 骨干功能从第四阶段开始以16的步幅pool池化。 该transformer的架构类似于DETR [5]中的架构,具有6个编码器层和6个解码器层,其中包括多头注意层(MHA)和前馈 网络(FFN)。 MHA具有8个磁头,宽度256,而FFN具有2048的隐藏单元。使用dropout为0.1。 边界框预测头是轻型FCN,由5个堆叠的Conv-BN-ReLU层组成。 分类头是一个三层感知器,每层中有256个隐藏单元。
- Training
训练数据由LaSOT [13],GOT-10K [18],COCO2017 [30]和TrackingNet [36]组成。根据VOT2019挑战赛的要求,我们从GOT-10K训练集中删除了1k禁止序列。
搜索图像和模板的大小分别为320×320像素和128×128像素,分别相当于目标框区域的5 2和2 2倍。 使用了包括水平翻转和亮度抖动在内的数据增强。 STARK-ST的最小训练数据单位是一个三元组,由两个模板和一个搜索图像组成。 STARK-ST的整个训练过程包含两个阶段,分别需要500个定位时间和50个分类时间。 每个纪元使用6×10 4三胞胎。 使用AdamW优化器[31]和权重衰减10 -4对网络进行优化。 损耗权重λL1和λiou分别设置为5和2。 每个GPU托管16个三胞胎,因此每次迭代的最小批处理大小为128个三胞胎。 骨干和其余部分的初始学习率分别为10 -5和10 -4。 在第一阶段学习400次后,第二阶段学习40次后,学习率下降了10倍。 STARK-S的训练设置与STARK-ST几乎相同,除了(1)STARK-S的最小训练数据单元是模板搜索对; (2)train过程只有第一阶段。
推理
默认情况下,动态模板更新间隔Tu和置信度阈值τ分别设置为200帧和0.5。 推理数据流pipeline仅包含前向遍历和从搜索区域到原始图像的坐标转换,而无需任何额外的后处理。 — end to end