机器学习读书笔记:强化学习
文章目录
- 强化学习基本模型
- K-摇臂赌博机模型
-
- ϵ \epsilon ϵ-贪心
- Softmax
- 有模型学习
-
- 策略评估
- 策略改进
- 免模型学习
-
- 蒙特卡洛强化学习
-
- 采样
- 策略改进
- 时态差分学习
- 值函数近似
- 模仿学习
-
- 直接模仿学习
- 逆强化学习
强化学习基本模型
强化学习的过程如下图所示:

相当于系统会与外界环境有不停的互动,先执行不同的动作,再根据外界环境的响应来判断这个动作的好坏。最终学会在什么环境下执行什么动作。这个和我们人在日常的学习过程中非常类似,有点胡萝卜加大棒的意思。
在这个简单的模型中,有几个概念:
- 环境 E E E
- 机器有一个状态空间 X X X,状态空间包括了多个状态,机器可以在状态之间进行切换。
- 机器同时还有一个动作空间 A A A,动作空间包括了多个动作,在不同的状态可以执行不同的动作。
- 机器执行动作之后,环境会根据状态变化、动作等因素给出一个奖赏 R R R,奖赏可能是正,可能是负。我理解是要进行了状态的转换才会有奖赏,当然这里的转换可以是自身到自身的转换。也就是 x i − > x j , i = j x_i->x_j, i=j xi−>xj,i=j
- 还有一个就是执行某个动作之后,机器从状态 x i x_i xi转换到 x j x_j xj的概率 P P P。
- 上面的四元组 < X , A , R , P >
- 状态间切换是一个马尔科夫决策过程,简单的说就是状态的变换只依赖于当前的状态,不依赖历史状态。
书中给出了一个西瓜浇水的马尔科夫决策过程图:

-
强化学习的目标就是根据这个四元组模型确定一个策略: π ( x , a ) \pi(x,a) π(x,a),也就是在哪个环境下就执行哪个动作的策略。或者用概率论的说法是,在 x x x状态下,选择动作 a a a的概率。
-
强化学习获得策略是要获得累积奖赏,就是整个过程中的最大奖赏,这个就是个贪心或者动态规划的问题了。有可能当前状态的某个动作 a i a_i ai奖赏稍高,下一步就没有奖赏了;而动作 a j a_j aj奖赏稍低,下一步就是高奖赏。针对这个奖赏的计算,书中提到了两种方式:
- T步累积奖赏:由公式 E [ 1 T ∑ t = 1 T r t ] E[\frac{1}{T}\sum_{t=1}^Tr_t] E[T1∑t=1Trt]来计算。就是计算T步总的奖赏值,优化目标是让这个奖赏值最大。
- γ \gamma γ折扣累积奖赏:由公式 E [ ∑ t = 0 ∞ γ t r t + 1 ] E[\sum_{t=0}^{\infty}{\gamma^tr_{t+1}}] E[∑t=0∞γtrt+1]。以一个小于1的折扣 γ \gamma γ是的之前的策略权重进行打折。
-
强化学习可以看做是一个引入了外界环境给出标签的一个监督学习的过程。
K-摇臂赌博机模型
如果每个动作都可以是一个确定的奖赏,那么最大化奖赏就比较简单了,因为默认这是一个马尔科夫决策过程,每个步骤选最大就行了。但是,实际情况往往不是这样,比如上图中,在缺水状态下浇水不一定就能获得奖赏,里面有一个概率在里面。
而K-摇臂赌博机模型如图:
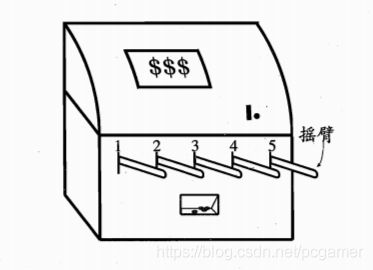
我的理解如下:
- 动作空间是确定的,有5个选择。
- 每个动作对应的状态切换是不一定的,也就是这个 P P P不确定。
- 我理解奖赏是确定的,每个摇臂会出多少钱应该是写了的。
- 状态空间应该就是一个,在这个模型中不太重要。
这里矛盾的地方就在于,总感觉下一次摇臂就会出奖了,而手里的币是有限的,下一个币到底是投哪一个。这里存在有两种策略:
- 仅探索:也就是将所有的机会平均分配给每个摇臂,有100个币,每个摇臂投20。最优以每个摇臂各自的平均吐币概率作为其奖赏期望的估计。
- 仅利用:按下目前最优的,比如已经投了10个币,而当前吐币概率最高的是3,那么第11个就摇3号摇臂。如果这次没出,3号的概率就降低了,此时2号最高,那么第12个就摇2号摇臂,直到投入所有的硬币。最后计算所有的奖赏。
实际上,仅利用一个策略是不够的,必须利用某种方式综合利用这两种策略。
ϵ \epsilon ϵ-贪心
简单的说,每次有 ϵ \epsilon ϵ的概率进行探索;以 1 − ϵ 1-\epsilon 1−ϵ的概率进行利用。
令 Q ( k ) Q(k) Q(k)表示摇臂 k k k的平均奖赏。若摇臂 k k k被尝试了 n n n次,那么
Q ( k ) = 1 n ∑ i = 1 n v i Q(k)=\frac{1}{n}\sum_{i=1}^n{v_i} Q(k)=n1i=1∑nvi
这里需要记录所有的奖赏值。可以改进为:
Q n ( k ) = Q n − 1 ( k ) + 1 n ( v n − Q n − 1 ( k ) ) Q_n(k)=Q_{n-1}(k)+\frac{1}{n}(v_n-Q_{n-1}(k)) Qn(k)=Qn−1(k)+n1(vn−Qn−1(k))
这样,对每个摇臂只需要记录两个值,累积的平均值和当前的值就足够了。
贪心算法的流程:

在这个过程中,每次机会都分成了 ϵ \epsilon ϵ和 1 − ϵ 1-\epsilon 1−ϵ去利用不同策略进行摇臂。
其实,我觉得最简单的理解就是100个币,而 ϵ = 0.2 \epsilon=0.2 ϵ=0.2,那么就是20个币用做探索,每个摇臂分4个。而剩下的80个按照仅利用的策略去摇。
Softmax
Softmax算法基于当前一直的摇臂平均奖赏来对探索和利用两种策略进行折中。在这个算法中,每次投币的摇臂号使用下面的概率公式来计算:
P ( k ) = e Q ( k ) τ ∑ i = 1 K e Q ( k ) τ P(k) = \frac{e^{\frac{Q(k)}{\tau}}}{\sum_{i=1}^K{e^{\frac{Q(k)}{\tau}}}} P(k)=∑i=1KeτQ(k)eτQ(k)
这个公式是对每个摇臂根据以往的奖赏计算概率,哪个摇臂算出来的值大,就选哪个。也就是 P ( 3 ) P(3) P(3)最大,这次的币就给3号摇臂。
- 如果 τ \tau τ接近于0,Softmax将近似于仅利用的策略。我理解是因为分子项基本就是由 Q ( k ) Q(k) Q(k)来确定,哪个 Q ( k ) Q(k) Q(k)大,就会选哪个。
- 如果 τ \tau τ接近于无限大,Softmax将近似于仅探索的策略。分子接近于1,下面是各个摇臂的求和,如果 K = 5 K=5 K=5,分母项就是5,就是平均概率了。
算法过程如下:

有模型学习
在上面的K-摇臂模型中,强化学习模型四元组中的 P P P是不确定的。如果考虑四元组全部已知,将这样的情况称之为有模型学习。有了模型后,当然就是确定策略了,在确定策略的过程中,一般有两个场景。
策略评估
假设基于已知的模型 < X , A , P , R >
对于奖赏值函数 V T π x V_T^{\pi}{x} VTπx,表示策略 π \pi π从状态 x x x出发所带来的累积奖赏,可以根据递归公式(公式1,后续会用到):
V T π x = ∑ a ∈ A π ( x , a ) ∑ x ′ ∈ X P x − > x ′ a ( 1 T R x − > x ′ a + T − 1 T V T − 1 π ( x ′ ) ) V_T^{\pi}{x}=\sum_{a\in A}{\pi(x,a)}\sum_{x^{\prime}\in X}{P_{x->x^{\prime}}^a(\frac{1}{T}R_{x->x^{\prime}}^a+\frac{T-1}{T}V_{T-1}^{\pi}(x^{\prime}))} VTπx=a∈A∑π(x,a)x′∈X∑Px−>x′a(T1Rx−>x′a+TT−1VT−1π(x′))
将 V T − 1 π ( x ′ ) V_{T-1}^{\pi}(x^{\prime}) VT−1π(x′)继续可以展开,因为所有的值都是已知,因此可以计算出每一步的奖赏,从而来评估这个策略。
γ \gamma γ累积奖赏同样可以通过递归公式进行计算:
V γ π x = ∑ a ∈ A π ( x , a ) ∑ x ′ ∈ X P x − > x ′ a ( R x − > x ′ a + γ V T − 1 π ( x ′ ) ) V_{\gamma}^{\pi}{x}=\sum_{a\in A}{\pi(x,a)}\sum_{x^{\prime}\in X}{P_{x->x^{\prime}}^a(R_{x->x^{\prime}}^a+\gamma V_{T-1}^{\pi}(x^{\prime}))} Vγπx=a∈A∑π(x,a)x′∈X∑Px−>x′a(Rx−>x′a+γVT−1π(x′))
通过递归公式最终递归到最初的状态 x 0 x_0 x0,只要确定好这个最初的状态就行了。

如果是使用 γ \gamma γ折扣累积奖赏,把第3行的代码替换掉就可以了。还有就是停止条件一般会改成 max x ∈ X ∣ V ( x ) − V ′ ( x ) ∣ < θ \max_{x\in X}|V(x)-V^{\prime}(x)| < \theta maxx∈X∣V(x)−V′(x)∣<θ,也就是两次迭代的差值小于某个阈值就停止。
评估多个策略,就可以根据每个策略的累积奖赏值来进行评估了。
策略改进
如果评估后,想改进这个策略,那就是另外一种应用场景了。实际上就是想找到一个策略,让这个确定了四元组的模型在这个策略上达到最大的奖赏,也就是 V π ( x ) V^{\pi}(x) Vπ(x)最大:
π ∗ = arg π m a x ∑ x ∈ X V π ( x ) \pi^*=\arg_{\pi}max\sum_{x\in X}V^{\pi}(x) π∗=argπmaxx∈X∑Vπ(x)
也就是可以获得最大值函数的那个策略就是最优策略。在上面的公式1中, V ( x ) V(x) V(x)是计算从 x x x出发的所有动作进行求和,这里改一下就成了求最大值:
V T π x = m a x a ∈ A ∑ x ′ ∈ X P x − > x ′ a ( 1 T R x − > x ′ a + T − 1 T V T − 1 π ( x ′ ) ) V_T^{\pi}{x}=max_{a\in A}\sum_{x^{\prime}\in X}{P_{x->x^{\prime}}^a(\frac{1}{T}R_{x->x^{\prime}}^a+\frac{T-1}{T}V_{T-1}^{\pi}(x^{\prime}))} VTπx=maxa∈Ax′∈X∑Px−>x′a(T1Rx−>x′a+TT−1VT−1π(x′))
定义一个 Q ( x , a ) Q(x,a) Q(x,a)表示在 x x x状态下通过动作 a a a能达到的奖赏函数,上面的公式就可以写成,称作Bellman等式:
V T π x = m a x a ∈ A Q π ∗ ( x , a ) V_T^{\pi}{x}=max_{a\in A}Q^{\pi^*}(x,a) VTπx=maxa∈AQπ∗(x,a)


上面是一个不等式的推导,从不等式中可以看出对某个策略 π \pi π的改进方法,从中挑选一个动作 a a a,将其改成 a ′ a^{\prime} a′,变更的条件就是 Q ( x , a ′ ) > Q ( x , a ) Q(x,a^{\prime})>Q(x,a) Q(x,a′)>Q(x,a)。更改后得到策略 π ′ \pi^{\prime} π′,从而也有了值函数 V ′ ( x ) V^{\prime}(x) V′(x),一直修改策略中的动作,直到 V ( x ) = V ′ ( x ) V(x)=V^{\prime}(x) V(x)=V′(x),这是的 π ′ \pi^{\prime} π′就是最优的策略。
综合上面的策略评估和改进策略,就可以迭代生成到最优的策略,先初始化以一个策略,然后评估,如果不是最优,就改进,不停的迭代直到生成最优的策略:

这个方法被称为策略迭代。
策略迭代中,每次生成一个策略,都需要进行策略评估,比较费事,可以直接用值函数进行评估:

免模型学习
在真实场景中,模型的四元组不太可能全都知道,比如上面的K-摇臂模型就是。更何况还有更复杂的场景。我们只需要知道做了某个动作,有一些什么奖赏,去不停的尝试,和监督学习类似,视图去估计这样的一个模型,来确定策略。这样的学习方式称作免模型学习。
在这种情况下:
-
对策略无法做评估
-
因为不知道到底有多少动作可选, V ( x ) V(x) V(x)无法计算,只能使用 Q ( x , a ) Q(x,a) Q(x,a)来评估。
蒙特卡洛强化学习
采样
蒙特卡洛强化学习是基于采样的学习方法。对整个系统进行多次采样,在K-摇臂中就是投币,每次采样投100个币,共投5次,算作有5次采样。对每次的采样进行记录:
< x 0 , a 0 , r 1 , x 1 , a 1 , r 2 , … , x T − 1 , a T − 1 , r T >
对每次的采样中的状态-动作键值对所对应的奖赏进行平均,比如键值对 < x 0 , a 0 >
在采样的过程中,如果策略是确定性的,多次采样可能是得到相同或者非常类似的轨迹,这对估计整个模型是不利的,因此,还需要想办法得到多条轨迹,但是策略本身是不能变的,策略变了,评估就没有意义了。
采样的贪心 ϵ \epsilon ϵ策略:借用K-摇臂中的贪心策略,而贪心策略是指以 ϵ \epsilon ϵ的概率是从所有动作中随机选取一个;以 1 − ϵ 1-\epsilon 1−ϵ的概率选取最优的动作。这样,每个不在原始策略中的动作的样本出现的概率也会有 ϵ ∣ A ∣ \frac{\epsilon}{|A|} ∣A∣ϵ,从而得到不同的轨迹,也不会大概率的改变平均值。
策略改进
增加了贪心策略的采样不影响上面提到的Bellman等式,所以改进方法不变,整个的蒙特卡洛学习方法流程如下:

- 评估和改进都是同一个策略,成为“同策略”算法
- 每得到一个样本,进行增量的更新,贪心策略也是增量的。
从上面的过程可以看出来,策略更新的时候也是使用了贪心算法的,有一定的概率选的不是最好的动作,导致最终效果会没那么好。而我们引入贪心只是为了增加轨迹的多样性,并不是要在改进的时候使用。因此有了下面的改进:

这里面主要就是增加了一个 p i pi pi的部分。这部分就是改进点,我们使用贪心算法选择了不同的轨迹,那么两条不同的轨迹可以看成是两个不同的策略生成的:一个是我们需要评估和优化的策略 π \pi π,一个是基于贪心策略修改了动作的策略 π ′ \pi^{\prime} π′。
那么,策略 π \pi π生成这个轨迹的概率是 P π P^{\pi} Pπ,策略 π ′ \pi^{\prime} π′生成这个轨迹的概率是 P π ′ P^{\pi^{\prime}} Pπ′。然后一段看得不明白过程但是不太明白为什么这么证明的证明过程证明了我们只需要一个比值:
P π P π ′ \frac{P^{\pi}}{P^{\pi^{\prime}}} Pπ′Pπ
其中,根据策略出来的概率 P π = 1 P^{\pi} = 1 Pπ=1,而 P π ′ P^{\pi^{\prime}} Pπ′为贪心策略里面的那两个值,也就是成了这个算法中的最要改进点。
这样的算法过程称作异策略算法,因为评估和改进的策略不是同一个。
时态差分学习
这个算法是针对上面的蒙特卡洛方法进行改进的。在蒙特卡洛方法中,每次都要对Q进行求和平均计算,还有奖赏的计算。这个方法参考之前K-摇臂章节中提到的增量更新方法,将蒙特卡洛方法过程中的第4-8步进行优化。
使用公式:
Q t + 1 p i ( x , a ) = Q t p i ( x , a ) + 1 t + 1 ( r t + 1 − Q t p i ( x , a ) ) Q_{t+1}^{pi}(x,a)=Q_{t}^{pi}(x,a)+\frac{1}{t+1}(r_{t+1}-Q_{t}^{pi}(x,a)) Qt+1pi(x,a)=Qtpi(x,a)+t+11(rt+1−Qtpi(x,a))
也就是每次只需要保留 t t t时刻的状态-动作方法 Q t Q_t Qt,还有得到 t + 1 t+1 t+1时刻的奖赏 r r r即可。
后面的一段话描述,当天没看懂,过个周末来看,貌似看明白了,果然还是要休息一下。
上面这个公式可以理解为 t t t时刻的函数 Q t Q_t Qt,加一个增量项的结果。后面的一截就是增量项,而 1 t + 1 \frac{1}{t+1} t+11为这个增量项的权重,这里是做的平均。所以把这个换成一个系数 α \alpha α,代表每次增量的权重: α t + 1 ( r t + 1 − Q t p i ( x , a ) ) \alpha_{t+1}(r_{t+1}-Q_t^{pi}(x,a)) αt+1(rt+1−Qtpi(x,a))。 α \alpha α为学习率,如果针对每个 Q t Q_t Qt进行展开,所有的系数之和会为1,我理解是 α + α 2 + ⋯ + α t \alpha+\alpha^2+\dots+\alpha^t α+α2+⋯+αt,因为 α \alpha α是小于1的正数,为什么等于0不太清楚。
书中给出了 γ \gamma γ折扣奖赏在上一公式上的推导,也就是把上面公式中的 r t + 1 r_{t+1} rt+1改成了 γ \gamma γ奖赏的计算方式:
Q t + 1 π ( x , a ) = Q t π ( x , a ) + α ( R x − > x ′ a + γ Q t π ( x ′ , a ′ ) − Q t π ( x , a ) ) Q_{t+1}^{\pi}(x,a)=Q_{t}^{\pi}(x,a)+\alpha(R_{x->x^{\prime}}^a+\gamma Q_{t}^{\pi}(x^{\prime},a^{\prime})-Q_{t}^{\pi}(x,a)) Qt+1π(x,a)=Qtπ(x,a)+α(Rx−>x′a+γQtπ(x′,a′)−Qtπ(x,a))
每到一个新的时刻,就使用这个公式进行计算。这个公式只需要
- 前一步的状态 x x x,state
- 前一步的动作 a a a, action
- 奖赏 R x − > x ′ a R_{x->x^{\prime}}^a Rx−>x′a, reward
- 当前状态 x ′ x^{\prime} x′, state
- 下一步动作 a ′ a^{\prime} a′, action
通过选择最大的 Q Q Q来更新策略,这就是Sarsa算法(上面五个要素的首字母)。

如果选择和更新是基于不同的策略,和上面的蒙特卡洛一样,就是“异策略”算法 Q − Q- Q−学习算法:

值函数近似
之前的强化学习模型中的 X X X,也就是状态空间都是按照离散值来的,如果 X X X是一个连续值,该怎么生成策略呢?第一想法就是做离散化,但是问题在于很多情况下的 X X X定义域是不清楚的,没法准确的做离散化。
也就是说,在Sarsa算法中, Q ( x , a ) Q(x,a) Q(x,a)没法进行计算和表示。因为在有限离散值中,函数Q是和 x , a x,a x,a的一个表格函数,想象成一个 x x x行, a a a列的表格,行列定了,Q就定了。而此时 x x x是一个连续值,除非定义了一个明确的计算函数,否则没法知道Q的值。所以需要换一种方式。
-
x x x状态空间不确定,也就是 V ( x ) V(x) V(x)的值函数没法表示,可以考虑直接学习获得一个值函数 V ( x ) V(x) V(x)
-
令 V θ ( x ) = θ T x V_{\theta}(x)=\theta^Tx Vθ(x)=θTx,使用最小二乘法计算损失,为了使误差最小,使用梯度下降法,就是之前神经网络的那一坨的推导方式
可以得到参数向量 θ \theta θ的更新方式:
θ = θ + α ( r + γ θ T x ′ − θ T x ) x \theta=\theta+\alpha(r+\gamma\theta^Tx^{\prime}-\theta^Tx)x θ=θ+α(r+γθTx′−θTx)x
x ′ x^{\prime} x′是下一时刻的状态。 -
V ( x ) V(x) V(x)这个值函数出来了,因为Sarsa中是需要状态-动作函数 Q ( x , a ) Q(x,a) Q(x,a),所以还需要做一下转换。两种装换形式
- 将上式中的 x x x向量变成 ( x , a ) (x,a) (x,a),增加一维,将动作放进去,直接计算得到的就是带动作的 θ \theta θ
- 新形成一个 a a a向量进行计算。
最终的方式就是状态连续值版本的Sarsa算法:

模仿学习
如果状态集和动作集很广,而步数T要比较大时。这个搜索空间会比较巨大,很难短时间内完成策略的制定。如果此时有一部分专家数据,可以知道机器快速完成搜索和学习,那么就像机器去模仿这些专家数据,成为模仿学习。
假设有一批专家的决策轨迹数据:
τ i = < s 1 i , a 1 i , s 2 i , a 2 i , … , s n i + 1 i > \tau_i=
其中, n i n_i ni为第 i i i条轨迹中的转移次数。
直接模仿学习
将上面的数据重新构造为:
D = { ( s 1 , a 1 ) , ( s 2 , a 2 ) , … , ( s ∑ i = 1 m n i , a ∑ i = 1 m n i ) , } D=\lbrace (s_1,a_1),(s_2,a_2),\dots,(s_{\sum_{i=1}^m{n_i}},a_{\sum_{i=1}^m{n_i}}),\rbrace D={(s1,a1),(s2,a2),…,(s∑i=1mni,a∑i=1mni),}
也就是将每个状态,动作的元素抽取出来。利用这样的一个数据集合去训练初始的策略模型,然后再在这个初始的策略模型基础上利用上述的强化学习模型进行学习,会缩短整个迭代次数。
逆强化学习
逆强化学习是试图从专家数据中获取一个奖赏函数,这个奖赏函数会使得策略让这些专家数据的出现概率最高。

其中的第5行代码就是通过各种转换获得的奖赏目标优化函数。