【Python绘图小课堂】词云韦恩图(上篇-分词)

数据说明
本案例数据为电影《白蛇传·情》豆瓣短评数据:
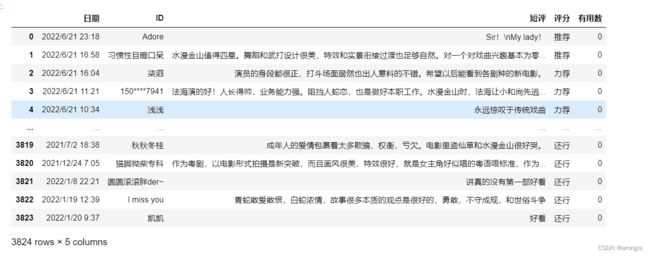
其中,评分有:推荐、力荐、还行、较差、很差 五种,我们将推荐与力荐的评论归为“好评”,并赋值为1,将其余三种评论归为“中差评”,赋值为0:
#将评分转化为数值
data['评分'] = data['评分'].replace(['力荐','推荐','还行','较差','很差'],[1,1,0,0,0]) 分词
对于评论文本数据的分析,最基础的就是分词,观察词频。分词的方法有很多,最常见的就是jieba分词:
#使用精确模式分词
def cut_word(word):
jieba.load_userdict('my_dict.txt')
cw = jieba.cut(word)
return list(cw)
#使用全模式分词
def cut_word_all(word):
jieba.load_userdict('my_dict.txt')
cw = jieba.cut(word,cut_all=True)
return list(cw)
这里提到了两种模式,一个是精确模式,另一个是全模式。精确模式即把文本最精确地分开,全模式则是找出句子中所有的可以成词的词语,在不同应用场景下有不同的模式选择,本案例中使用精确模式。
自定义词典
"my_dict.txt"文件是自定义词典,对于一些jieba分词无法按需划分的词语,可以建立一个txt文件,将词语放入,格式为一个词语在一行:
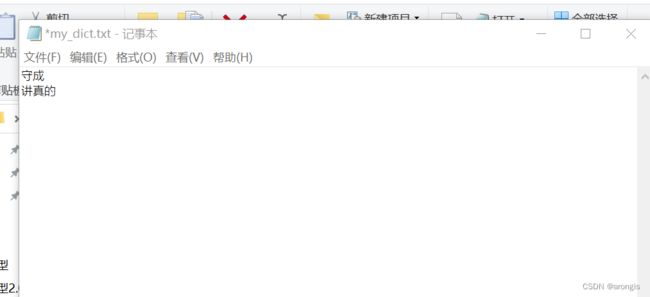
去停用词
#去停用词
with open('./hit_stopwords.txt','r',encoding = 'utf8') as f:
stopwords = [w.strip() for w in f] #去掉词语两端可能存在的空格
def q_ting(cut_word):
for i in range(len(cut_word)):
for j in range(len(cut_word[i])-1):
#print(i,j)
#cut_word[i][j] = cut_word[i][j].strip()
if str(cut_word[i][j]).strip() in stopwords:
#print(i,j)
cut_word[i][j] = None
if len(str(cut_word[i][j]).strip())==0: #去除空格
cut_word[i][j] = None
return cut_word
#去除None值
def q_none(cut_word):
for i in range(len(cut_word)):
while None in cut_word[i]:
cut_word[i].remove(None)
for i in range(len(cut_word)):
while '。' in cut_word[i]:
cut_word[i].remove('。')
return cut_word去停用词有很多方法,上面的函数可以实现将分词结果放在DataFrame的一列中:
#分词
data['word_cut'] = data['短评'].apply(cut_word)
#去停用词
data['word_cut'] = q_ting(data['word_cut'])
data['word_cut'] = q_none(data['word_cut'])
词频统计
#统计词频
def freq_count(cut_word):
freq_cut_word = pd.DataFrame(pd.Series(cut_word.sum()).value_counts())
freq_cut_word.columns = ['count']
freq_cut_word['word'] = freq_cut_word.index
freq_cut_word.index = range(len(freq_cut_word))
return freq_cut_word分词结束后,我们就可以进行词频统计:
#全部评论
comment_all = freq_count(data['word_cut'])
print(comment_all)
#分别取出好评与中差评数据
high_comment = data[data['评分']==1] #好评
low_comment = data[data['评分']==0] #中差评
high_comment.index = range(len(high_comment))
low_comment.index = range(len(low_comment))
#全部好评词频
comment_high = freq_count(high_comment['word_cut'])
#全部中差评词频
comment_low = freq_count(low_comment['word_cut']) 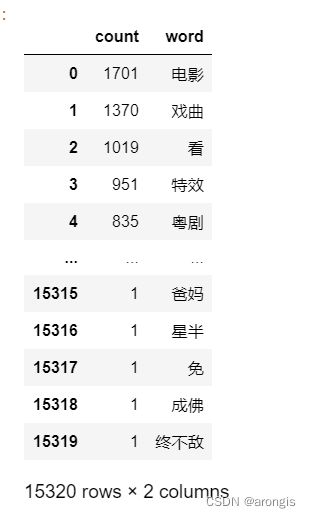
韦恩图绘图准备
我们要绘制的韦恩图主要分为三个部分:好评词汇(不包含中差评出现的词)、好评与中差评中均出现的词、中差评词汇(不包含好评出现的词),知道这三部分的词及词频后,我们就可以绘制词云形式的韦恩图了。
要知道上述三部分词语,我们可以利用Python集合的 .difference() 函数与 .intersection()函数:
comment_diff_list_high = set(comment_high['word']).difference(set(comment_low['word']))
comment_diff_list_low = set(comment_low['word']).difference(set(comment_high['word']))
comment_inner_list = set(comment_low['word']).intersection(set(comment_high['word']))在获得三部分的词语后,我们再得到相应的词频:
def my_differ(comment_high,comment_diff_list_high):
comment_diff_high_word = []
comment_diff_high_count = []
for i in range(len(comment_high)):
if comment_high['word'][i] in comment_diff_list_high:
comment_diff_high_word.append(comment_high['word'][i])
comment_diff_high_count.append(comment_high['count'][i])
comment_diff_high = pd.DataFrame([])
comment_diff_high['word'] = comment_diff_high_word
comment_diff_high['count'] = comment_diff_high_count
return comment_diff_highcomment_high_diff_low = my_differ(comment_high,comment_diff_list_high)
comment_low_diff_high = my_differ(comment_low,comment_diff_list_low)
comment_inner = my_differ(comment_all,comment_inner_list)下一步,我们就可以用传统词云绘制的方法,来实现词云韦恩图啦!