基于MegEngine实现语义分割【附部分源码及模型】
文章目录
- 前言
- 语义分割发展史及意义
- 一、数据集的准备
- 二、基于MegEngine的语义分割框架构建
-
- 1.引入库
- 2.CPU/GPU配置
- 3.数据标准化
- 4.解析数据集到列表中
- 5.设置数据迭代器
- 6.获取loader
- 7.模型构建
- 8.模型训练
-
- 1.优化器及参数初始化
- 2.模型训练
- 3.模型保存
- 9.模型预测
- 三、基于MegEngine的模型构建
- 四、模型主入口
- 五、效果展示
-
- 1.自定义数据集效果展示
- 2.VOC数据集效果展示
- 六、各模型免费下载
- 总结
前言
本文主要讲解基于megengine深度学习框架实现目标检测,鉴于之前写chainer的麻烦,本结构代码也类似chainer的目标检测框架,各个模型只需要修改网络结构即可,本次直接一篇博文写完目标检测框架及网络结构的搭建,让志同道合者不需要切换文章。
环境配置:
python 3.8
megengine 1.9.1
cuda 10.1
语义分割发展史及意义
图像语义分割,它是将整个图像分成一个个像素组,然后对其进行标记和分类。特别地,语义分割试图在语义上理解图像中每个像素的角色。
图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统中举足轻重。众所周知,图像是由一个个像素(Pixel)组成的,而语义分割就是将图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。语义图像分割就是将每个像素都标注上其对应的类别。需要注意的是,这里不但单独区分同一类别的不同个体,而是仅仅关系该像素是属于哪个类别。
分割任务对于许多任务都非常有用,比如自动驾驶汽车(为了使自动驾驶汽车能够适应现存道路,其需要具有对周围环境的感知能力);医疗图像判断(可以通过机器辅助放射治疗师的分析,从而加速放射检查)
一、数据集的准备
语义分割数据标注主要使用labelImg工具,python安装只需要:pip install labelme 即可,然后在命令提示符输入:labelme即可,如图:
在这里只需要修改“OpenDir“,“OpenDir“主要是存放图片需要标注的路径
选择好路径之后即可开始绘制:
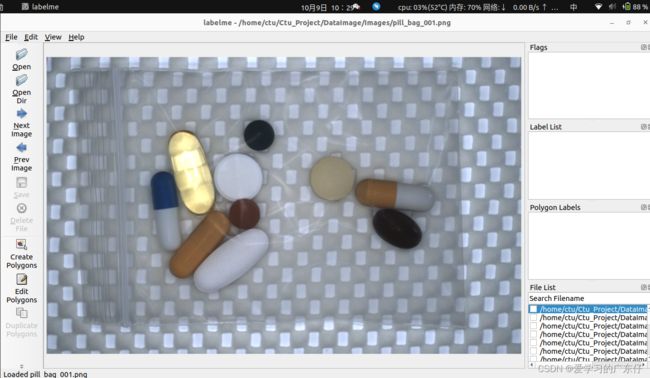
我在平时标注的时候快捷键一般只用到:
createpolygons:(ctrl+N)开始绘制
a:上一张
d:下一张
绘制过程如图:
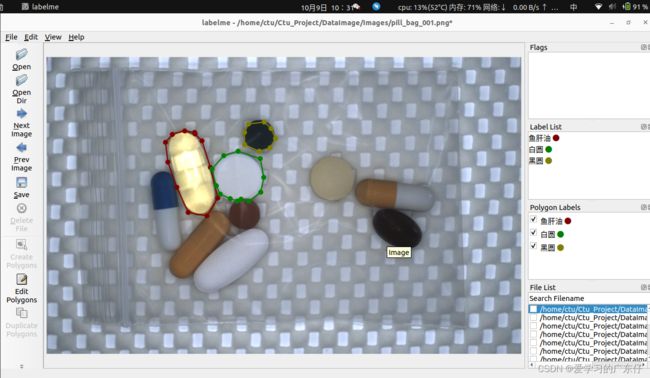
就只需要一次把目标绘制完成即可。
二、基于MegEngine的语义分割框架构建
本语义分割架目录结构如下:
BaseModel:此目录保存基于VOC数据集、cityspace数据集已经训练好的模型
core:此目录主要保存标准的py文件,功能如语义分割评估算法等计算
data:此目录主要保存标准py文件,功能如数据加载器,迭代器等
nets:此目录主要保存模型结构
result_Model:此目录是自定义训练数据集的保存模型位置
Ctu_Segmentation.py:语义分割主类实现及主入口
1.引入库
import os,time,megengine,math,json,random,cv2,sys
sys.path.append('.')
import numpy as np
from PIL import Image
import megengine as mge
import megengine.distributed as dist
import megengine.functional as F
from megengine.autodiff import GradManager
from megengine.data import DataLoader, Infinite, RandomSampler
from megengine.data import transform as T
from megengine.optimizer import SGD
2.CPU/GPU配置
if USEGPU!='-1' and dist.helper.get_device_count_by_fork("gpu") > 0:
megengine.set_default_device('gpux')
else:
megengine.set_default_device('cpux')
USEGPU='-1'
os.environ['CUDA_VISIBLE_DEVICES']= USEGPU
3.数据标准化
self.img_mean = [103.530, 116.280, 123.675] # BGR
self.img_std = [57.375, 57.120, 58.395]
4.解析数据集到列表中
def CreateDataList_Segmentation(DataDir,train_split=0.9):
DataList = [os.path.join(DataDir, fileEach) for fileEach in [each for each in os.listdir(DataDir) if re.match(r'.*\.json', each)]]
All_label_name = ['_background_']
for each_json in DataList:
try:
data = json.load(open(each_json))
except:
try:
data = json.load(open(each_json,encoding='utf-8'))
except:
data = json.load(open(each_json,encoding='utf-8',errors='ignore'))
for shape in sorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']
if label_name not in All_label_name:
All_label_name.append(label_name)
random.shuffle(DataList)
if train_split<=0 or train_split>=1:
train_list = DataList
val_list = DataList
else:
train_list = DataList[:int(len(DataList)*train_split)]
val_list = DataList[int(len(DataList)*train_split):]
return train_list,val_list, All_label_name
def JsonToLabel(JsonFile,classes_names):
try:
data = json.load(open(JsonFile))
except:
try:
data = json.load(open(JsonFile,encoding='utf-8'))
except:
data = json.load(open(JsonFile,encoding='utf-8',errors='ignore'))
imageData = data.get('imageData')
label_name_to_value = {'_background_': 0}
for shape in sorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']
if label_name not in label_name_to_value:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
img = utils.img_b64_to_arr(imageData)
lbl, _ = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
colormap = imgviz.label_colormap()
lbl_pil.putpalette(colormap.flatten())
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
new = Image.new("RGB", [np.shape(lbl_pil)[1], np.shape(lbl_pil)[0]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes_names.index(name)
new = new + np.expand_dims(index_all * (np.array(lbl_pil) == index_json), -1)
new = Image.fromarray(np.uint8(new))
lab = cv2.cvtColor(np.asarray(new), cv2.COLOR_RGB2GRAY)
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
return img, lab
5.设置数据迭代器
class PascalVOC(Dataset):
def __init__(self, data_list,classes_names):
super().__init__()
self.data_list = data_list
self.classes_names = classes_names
self.img_infos = dict()
def __getitem__(self, index):
target = []
image,mask = JsonToLabel(self.data_list[index],self.classes_names)
target.append(image)
mask = mask[:, :, np.newaxis]
target.append(mask)
return tuple(target)
def __len__(self):
return len(self.data_list)
6.获取loader
self.train_dataloader = DataLoader(
train_dataset,
sampler=train_sampler,
transform=T.Compose(
transforms=[
T.RandomHorizontalFlip(0.5),
T.RandomResize(scale_range=(0.5, 2)),
T.RandomCrop(
output_size=(self.image_size, self.image_size),
padding_value=[0, 0, 0],
padding_maskvalue=255,
),
T.Normalize(mean=self.img_mean, std=self.img_std),
T.ToMode(),
],
order=["image", "mask"],
),
num_workers=num_workers,
)
7.模型构建
self.model = DeepLabV3Plus(num_classes=len(self.classes_names),backbone=backbone)
8.模型训练
1.优化器及参数初始化
backbone_params = []
head_params = []
for name, param in self.model.named_parameters():
if "backbone" in name:
backbone_params.append(param)
else:
head_params.append(param)
opt = SGD(
[
{
"params": backbone_params,
"lr": learning_rate * 0.1,
},
{"params": head_params},
],
lr=learning_rate,
momentum=0.9,
weight_decay=0.0001,
)
gm = GradManager()
gm.attach(self.model.parameters())
2.模型训练
with gm:
pred = self.model(mge.tensor(inputs))
mask = mge.tensor(labels) != 255
pred = pred.transpose(0, 2, 3, 1)
loss = F.loss.cross_entropy(pred[mask], mge.tensor(labels)[mask], 1)
gm.backward(loss)
opt.step().clear_grad()
3.模型保存
模型保存结构必须保持结构一致,如图:
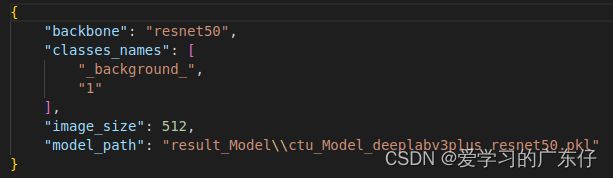 主要包含主干网络结构,类别,图像大小,模型保存路径
主要包含主干网络结构,类别,图像大小,模型保存路径
megengine.save(
{"epoch": epoch, "state_dict": self.model.state_dict()}, ClassDict['model_path'],
)
9.模型预测
def predict(self,img_cv):
ori_h, ori_w = img_cv.shape[:2]
processed_img = self.transform.apply(img_cv)[np.newaxis, :]
processed_img = megengine.tensor(processed_img, dtype="float32")
pred = self.model(processed_img)
pred = pred.numpy().squeeze().argmax(0)
pred = cv2.resize(pred.astype("uint8"), (ori_w, ori_h), interpolation=cv2.INTER_NEAREST)
seg_img = np.zeros((ori_h, ori_w, 3))
for c in range(len(self.classes_names)):
seg_img[:,:,0] += ((pred[:,: ] == c )*( self.colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((pred[:,: ] == c )*( self.colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((pred[:,: ] == c )*( self.colors[c][2] )).astype('uint8')
image_result = seg_img.astype("uint8")
img_add = cv2.addWeighted(img_cv, 1.0, image_result, 0.7, 0)
return img_add
三、基于MegEngine的模型构建
deeplab3+代码实现
import megengine.functional as F
import megengine.module as M
from nets.resnet import resnet18,resnet34,resnet50,resnet101,resnet152,resnext50_32x4d,resnext101_32x8d
class ASPP(M.Module):
def __init__(self, in_channels, out_channels, dr=1):
super().__init__()
self.conv1 = M.Sequential(
M.Conv2d(
in_channels, out_channels, 1, 1, padding=0, dilation=dr, bias=False
),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
self.conv2 = M.Sequential(
M.Conv2d(
in_channels,
out_channels,
3,
1,
padding=6 * dr,
dilation=6 * dr,
bias=False,
),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
self.conv3 = M.Sequential(
M.Conv2d(
in_channels,
out_channels,
3,
1,
padding=12 * dr,
dilation=12 * dr,
bias=False,
),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
self.conv4 = M.Sequential(
M.Conv2d(
in_channels,
out_channels,
3,
1,
padding=18 * dr,
dilation=18 * dr,
bias=False,
),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
self.conv_gp = M.Sequential(
M.Conv2d(in_channels, out_channels, 1, 1, 0, bias=False),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
self.conv_out = M.Sequential(
M.Conv2d(out_channels * 5, out_channels, 1, 1, padding=0, bias=False),
M.BatchNorm2d(out_channels),
M.ReLU(),
)
def forward(self, x):
conv1 = self.conv1(x)
conv31 = self.conv2(x)
conv32 = self.conv3(x)
conv33 = self.conv4(x)
gp = F.mean(x, [2, 3], True)
gp = self.conv_gp(gp)
gp = F.nn.interpolate(gp, x.shape[2:])
out = F.concat([conv1, conv31, conv32, conv33, gp], axis=1)
out = self.conv_out(out)
return out
class DeepLabV3Plus(M.Module):
def __init__(self, num_classes=21,backbone='resnet18'):
super().__init__()
self.output_stride = 16
self.num_classes = num_classes
self.model_name={
'resnet18':resnet18,
'resnet34':resnet34,
'resnet50':resnet50,
'resnet101':resnet101,
'resnet152':resnet152,
'resnext50_32x4d':resnext50_32x4d,
'resnext101_32x8d':resnext101_32x8d
}
self.backbone_net=backbone
self.aspp = ASPP(
in_channels=2048, out_channels=256, dr=16 // self.output_stride
)
self.dropout = M.Dropout(0.5)
self.upstage1 = M.Sequential(
M.Conv2d(256, 48, 1, 1, padding=0, bias=False),
M.BatchNorm2d(48),
M.ReLU(),
)
self.upstage2 = M.Sequential(
M.Conv2d(256 + 48, 256, 3, 1, padding=1, bias=False),
M.BatchNorm2d(256),
M.ReLU(),
M.Dropout(0.5),
M.Conv2d(256, 256, 3, 1, padding=1, bias=False),
M.BatchNorm2d(256),
M.ReLU(),
M.Dropout(0.1),
)
self.conv_out = M.Conv2d(256, self.num_classes, 1, 1, padding=0)
for m in self.modules():
if isinstance(m, M.Conv2d):
M.init.msra_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, M.BatchNorm2d):
M.init.ones_(m.weight)
M.init.zeros_(m.bias)
if self.backbone_net == 'resnet18' or self.backbone_net=='resnet34':
self.backbone = self.model_name[self.backbone_net](
replace_stride_with_dilation=[False, False, False]
)
else:
self.backbone = self.model_name[self.backbone_net](
replace_stride_with_dilation=[False, False, True]
)
del self.backbone.fc
def forward(self, x):
layers = self.backbone.extract_features(x)
up0 = self.aspp(layers["res5"])
up0 = self.dropout(up0)
up0 = F.nn.interpolate(up0, layers["res2"].shape[2:])
up1 = self.upstage1(layers["res2"])
up1 = F.concat([up0, up1], 1)
up2 = self.upstage2(up1)
out = self.conv_out(up2)
out = F.nn.interpolate(out, x.shape[2:])
return out
四、模型主入口
本人主要习惯简洁方式,因此主入口的实现过程也是很简单的
if __name__ == "__main__":
# ctu = Ctu_Segmentation(USEGPU="0",image_size=512)
# ctu.InitModel(r'E:\DL_Project\DataSet\DataSet_Segmentation\DataSet_AQ_HuaHeng1\DataImage',train_split=1,batch_size=2,Pre_Model=None,backbone='resnet50',num_workers=0)
# ctu.train(TrainNum=400,learning_rate=0.0001, ModelPath='result_Model')
ctu = Ctu_Segmentation(USEGPU="-1")
ctu.LoadModel("./BaseModel/ctu_params_voc.json")
for root, dirs, files in os.walk(r'./BaseModel'):
for f in files:
img_cv = ctu.read_image(os.path.join(root, f))
if img_cv is None:
continue
res_img = ctu.predict(img_cv)
cv2.imshow("result", res_img)
cv2.waitKey()
五、效果展示
1.自定义数据集效果展示
待定
2.VOC数据集效果展示

六、各模型免费下载
cityspace
voc
总结
本文调用方式简单,对模型感兴趣的或者其他问题的可以私聊