文章目录
- 一. 创建tensor
- 二. tensor属性
-
- 1. 判断属性
-
- is_cuda 是否存储在GPU上
- is_quantized
- is_meta
- 2. 基本属性
-
- dtype 数据类型
- device 计算引擎
- shape 形状
- 3. 操作
-
- T 转置
- real 返回复数实部的新tensor
- imag 返回复数虚部的新tensor
- 4. 其它
-
- 三. tensor方法
-
- 1. 构造新tensor
-
- new_tensor 创建新tensor
- new_full 创建指定形状指定值的tensor
- new_empty 创建指定形状的空tensor
- new_ones 创建指定形状值为1的tensor
- 2. 数学函数
-
- abs, abs_, absolute, absolute_ 绝对值
- add, add_ 求和
- addcdiv, addcdiv_ o u t i = i n p u t i + v a l u e × t e n s o r 1 i t e n s o r 2 i out_i = input_i + value × \frac{tensor1_i}{tensor2_i} outi=inputi+value×tensor2itensor1i
- addcmul, addcmul_ o u t i = i n p u t i + v a l u e × t e n s o r 1 i × t e n s o r 2 i out_i = input_i + value × tensor1_i × tensor2_i outi=inputi+value×tensor1i×tensor2i
- addbmm, addbmm_ β i n p u t + α ( ∑ i = 0 b − 1 b a t c h 1 i @ b a t c h 2 i ) \beta\ input+\alpha(\sum_{i=0}^{b-1} batch1_i@batch2_i) β input+α(∑i=0b−1batch1i@batch2i) [^1]
- baddbmm, baddbmm_ o u t i = β i n p u t i + α ( b a t c h 1 i @ b a t c h 2 i ) out_i=\beta\ input_i + \alpha(batch1_i @ batch2_i) outi=β inputi+α(batch1i@batch2i)
- addmm, addmm_, sspaddmm β i n p u t + α ( m a t 1 @ m a t 2 ) \beta\ input+\alpha(mat1@mat2) β input+α(mat1@mat2) [^1]
- addmv, addmv_ β i n p u t + α ( m a t @ v e c ) \beta\ input+\alpha(mat@vec) β input+α(mat@vec) [^1]
- addr, addr_ o u t = β i n p u t + α ( v e c 1 ⊗ v e c 2 ) out = \beta\ input + \alpha(vec1⊗vec2) out=β input+α(vec1⊗vec2) [^2]
- bernoulli, bernoulli_ 伯努利分布
- all 判断所有元素是否都为True(或非零值)
- any 判断是否包含True(或非零值)
- amax 获取缩减指定维度后的最大值
- amin 获取缩减指定维度后的最小值
- argmax 获取缩减指定维度后的最大值的索引
- argmin 获取缩减指定维度后的最小值的索引
- argsort 获取排序后值在原数据中的索引位置
- angle 角度
- acos, acos_, arccos, arccos_ 反余弦
- asin, asin_, arcsin, arcsin_ 反正弦
- atan, atan_, arctan, arctan_ 反正切
- atan2, atan2_ o u t i = a t a n ( i n p u t i / o t h e r i ) out_i = atan(input_i / other_i) outi=atan(inputi/otheri)
- backward
- 3. 转换
-
- as_strided 生成视图
- bfloat16 将数据类型转换为bfloat16
- 4. 其它
-
一. 创建tensor
tensor类似于numpy的ndarray, 很多操作方法也相似
import torch
import numpy as np
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
print(x_data)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
print(x_np)
x_ones = torch.ones_like(x_data)
print(x_ones)
x_rand = torch.rand_like(x_data, dtype=torch.float)
print(x_rand)
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
二. tensor属性
1. 判断属性
is_cuda 是否存储在GPU上
is_quantized
is_meta
2. 基本属性
dtype 数据类型
| Data type |
dtype |
Legacy Constructors |
| 32-bit floating point |
torch.float32 or torch.float |
torch.*.FloatTensor |
| 64-bit floating point |
torch.float64 or torch.double |
torch.*.DoubleTensor |
| 64-bit complex |
torch.complex64 or torch.cfloat |
|
| 128-bit complex |
torch.complex128 or torch.cdouble |
|
| 16-bit floating point 1 |
torch.float16 or torch.half |
torch.*.HalfTensor |
| 16-bit floating point 2 |
torch.bfloat16 |
torch.*.BFloat16Tensor |
| 8-bit integer (unsigned) |
torch.uint8 |
torch.*.ByteTensor |
| 8-bit integer (signed) |
torch.int8 |
torch.*.CharTensor |
| 16-bit integer (signed) |
torch.int16 or torch.short |
torch.*.ShortTensor |
| 32-bit integer (signed) |
torch.int32 or torch.int |
torch.*.IntTensor |
| 64-bit integer (signed) |
torch.int64 or torch.long |
torch.*.LongTensor |
| Boolean |
torch.bool |
torch.*.BoolTensor |
device 计算引擎
shape 形状
3. 操作
T 转置
real 返回复数实部的新tensor
共享底层存储
imag 返回复数虚部的新tensor
共享底层存储
4. 其它
grad 梯度
ndim
三. tensor方法
1. 构造新tensor
默认使用旧tensor的dtype和device创建一个新tensor
此处罗列共同参数, 下方不再赘述
| 参数名 |
默认值 |
说明 |
| dtype |
None |
指定生成的tensor的数据类型 |
| device |
None |
指定计算引擎 |
| requires_grad |
False |
是否允许反向传播 |
requires_grad没懂先引用
new_tensor 创建新tensor
| 参数名 |
默认值 |
说明 |
| data |
- |
源数据, 且新生成的tensor总是发生数据拷贝 |
new_full 创建指定形状指定值的tensor
| 参数名 |
默认值 |
说明 |
| size |
- |
形状 |
| fill_value |
- |
值 |
new_empty 创建指定形状的空tensor
默认会有值填充但其值没有实际含义
new_ones 创建指定形状值为1的tensor
2. 数学函数
_ 结尾的函数会共享底层存储
abs, abs_, absolute, absolute_ 绝对值
add, add_ 求和
o u t = i n p u t + α o t h e r out=input+\alpha\ other out=input+α other
| 参数名 |
默认值 |
说明 |
| other |
- |
可以是数字或tensor等 |
| alpha |
1 |
other的权重 |
addcdiv, addcdiv_ o u t i = i n p u t i + v a l u e × t e n s o r 1 i t e n s o r 2 i out_i = input_i + value × \frac{tensor1_i}{tensor2_i} outi=inputi+value×tensor2itensor1i
o u t i = i n p u t i + v a l u e × t e n s o r 1 i t e n s o r 2 i out_i = input_i + value × \frac{tensor1_i}{tensor2_i} outi=inputi+value×tensor2itensor1i
| 参数名 |
默认值 |
说明 |
| tensor1 |
- |
|
| tensor2 |
- |
|
| value |
1 |
|
addcmul, addcmul_ o u t i = i n p u t i + v a l u e × t e n s o r 1 i × t e n s o r 2 i out_i = input_i + value × tensor1_i × tensor2_i outi=inputi+value×tensor1i×tensor2i
o u t i = i n p u t i + v a l u e × t e n s o r 1 i × t e n s o r 2 i out_i = input_i + value × tensor1_i × tensor2_i outi=inputi+value×tensor1i×tensor2i
| 参数名 |
默认值 |
说明 |
| tensor1 |
- |
|
| tensor2 |
- |
|
| value |
1 |
|
addbmm, addbmm_ β i n p u t + α ( ∑ i = 0 b − 1 b a t c h 1 i @ b a t c h 2 i ) \beta\ input+\alpha(\sum_{i=0}^{b-1} batch1_i@batch2_i) β input+α(∑i=0b−1batch1i@batch2i)
input.shape => ( n ∗ p ) i n p u t 即 当 前 t e n s o r (n * p)\ _{input即当前tensor} (n∗p) input即当前tensor
out.shape => ( n ∗ p ) (n * p) (n∗p)
β i n p u t + α ( ∑ i = 0 b − 1 b a t c h 1 i @ b a t c h 2 i ) \beta\ input+\alpha(\sum_{i=0}^{b-1} batch1_i@batch2_i) β input+α(i=0∑b−1batch1i@batch2i)
| 参数名 |
默认值 |
说明 |
| batch1 |
- |
形状 ( b ∗ n ∗ m ) (b * n * m) (b∗n∗m) |
| batch2 |
- |
形状 ( b ∗ m ∗ p ) (b * m * p) (b∗m∗p) |
| beta |
1 |
β \beta β |
| alpha |
1 |
α \alpha α |
baddbmm, baddbmm_ o u t i = β i n p u t i + α ( b a t c h 1 i @ b a t c h 2 i ) out_i=\beta\ input_i + \alpha(batch1_i @ batch2_i) outi=β inputi+α(batch1i@batch2i)
input.shape => ( b ∗ n ∗ p ) i n p u t 即 当 前 t e n s o r (b * n * p)\ _{input即当前tensor} (b∗n∗p) input即当前tensor
out.shape => ( b ∗ n ∗ p ) (b * n * p) (b∗n∗p)
o u t i = β i n p u t i + α ( b a t c h 1 i @ b a t c h 2 i ) out_i=\beta\ input_i + \alpha(batch1_i @ batch2_i) outi=β inputi+α(batch1i@batch2i)
| 参数名 |
默认值 |
说明 |
| batch1 |
- |
形状 ( b ∗ n ∗ m ) (b * n * m) (b∗n∗m) |
| batch2 |
- |
形状 ( b ∗ m ∗ p ) (b * m * p) (b∗m∗p) |
| beta |
1 |
β \beta β |
| alpha |
1 |
α \alpha α |
addmm, addmm_, sspaddmm β i n p u t + α ( m a t 1 @ m a t 2 ) \beta\ input+\alpha(mat1@mat2) β input+α(mat1@mat2)
input.shape => ( n ∗ p ) i n p u t 即 当 前 t e n s o r (n * p)\ _{input即当前tensor} (n∗p) input即当前tensor
out.shape => ( n ∗ p ) (n * p) (n∗p)
o u t = β i n p u t + α ( m a t 1 @ m a t 2 ) out = \beta\ input+\alpha(mat1@mat2) out=β input+α(mat1@mat2)
| 参数名 |
默认值 |
说明 |
| mat1 |
- |
形状 ( n ∗ m ) (n * m) (n∗m) |
| mat2 |
- |
形状 ( m ∗ p ) (m * p) (m∗p) |
| beta |
1 |
β \beta β |
| alpha |
1 |
α \alpha α |
addmv, addmv_ β i n p u t + α ( m a t @ v e c ) \beta\ input+\alpha(mat@vec) β input+α(mat@vec)
input.shape => ( n , ) i n p u t 即 当 前 t e n s o r (n, )\ _{input即当前tensor} (n,) input即当前tensor
out.shape => ( n , ) (n, ) (n,)
o u t = β i n p u t + α ( m a t @ v e c ) out = \beta\ input+\alpha(mat@vec) out=β input+α(mat@vec)
| 参数名 |
默认值 |
说明 |
| mat |
- |
形状 ( n , m ) (n, m) (n,m) |
| vec |
- |
形状 ( m , ) (m, ) (m,) 一维, 进行矩阵运算时转为 (m, 1) |
| beta |
1 |
β \beta β |
| alpha |
1 |
α \alpha α |
addr, addr_ o u t = β i n p u t + α ( v e c 1 ⊗ v e c 2 ) out = \beta\ input + \alpha(vec1⊗vec2) out=β input+α(vec1⊗vec2)
input.shape => ( n , m ) i n p u t 即 当 前 t e n s o r (n, m)\ _{input即当前tensor} (n,m) input即当前tensor
out.shape => ( n , m ) (n, m) (n,m)
o u t = β i n p u t + α ( v e c 1 ⊗ v e c 2 ) out = \beta\ input + \alpha(vec1⊗vec2) out=β input+α(vec1⊗vec2)
| 参数名 |
默认值 |
说明 |
| vec1 |
- |
形状 ( n , ) (n, ) (n,) 运算时转为 (n, 1) |
| vec2 |
- |
形状 ( m , ) (m, ) (m,) 原酸时转为 (1, m) |
| beta |
1 |
β \beta β |
| alpha |
1 |
α \alpha α |
bernoulli, bernoulli_ 伯努利分布
o u t i ∼ B e r n o u l l i ( p = i n p u t i ) ; 0 ≤ i n p u t i ≤ 1 out_i ∼ Bernoulli(p = input_i); 0 \le input_i \le 1 outi∼Bernoulli(p=inputi);0≤inputi≤1
伯努利分布指的是对于随机变量X有, 参数为p(0
| 参数名 |
默认值 |
说明 |
| generator |
- |
类似于随机数种子, 同一个种子返回的数据是固定的. 例如: torch.Generator().manual_seed(2) |
| ### allclose $ |
input - other |
\le atol + rtol × |
out => bool
∣ i n p u t − o t h e r ∣ ≤ a t o l + r t o l × ∣ o t h e r ∣ | input - other | \le atol + rtol × |other| ∣input−other∣≤atol+rtol×∣other∣
| 参数名 |
默认值 |
说明 |
| other |
- |
|
| rtol |
1e-05 |
|
| atol |
1e-08 |
|
| equal_nan |
False |
如果为True两个NaN将被视为相等否则视为不相等 |
all 判断所有元素是否都为True(或非零值)
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度 |
| keepdim |
False |
结果是否保留原维度 |
any 判断是否包含True(或非零值)
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度 |
| keepdim |
False |
结果是否保留原维度 |
amax 获取缩减指定维度后的最大值
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度, 默认获取全局最大值 |
| keepdim |
False |
结果是否保留原维度 |
amin 获取缩减指定维度后的最小值
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度, 默认获取全局最小值 |
| keepdim |
False |
结果是否保留原维度 |
argmax 获取缩减指定维度后的最大值的索引
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度 |
| keepdim |
False |
结果是否保留原维度 |
argmin 获取缩减指定维度后的最小值的索引
| 参数名 |
默认值 |
说明 |
| dim |
None |
缩减的维度 |
| keepdim |
False |
结果是否保留原维度 |
argsort 获取排序后值在原数据中的索引位置
| 参数名 |
默认值 |
说明 |
| dim |
-1 |
排序维度, 默认对最后一个维度排序 |
| descending |
False |
默认升序排序 |
angle 角度
tensor值为复数
acos, acos_, arccos, arccos_ 反余弦
asin, asin_, arcsin, arcsin_ 反正弦
atan, atan_, arctan, arctan_ 反正切
atan2, atan2_ o u t i = a t a n ( i n p u t i / o t h e r i ) out_i = atan(input_i / other_i) outi=atan(inputi/otheri)
o u t i = a t a n ( i n p u t i / o t h e r i ) out_i = atan(input_i / other_i) outi=atan(inputi/otheri)
backward
| 参数名 |
默认值 |
说明 |
| gradient |
None |
|
| retain_graph |
None |
|
| create_graph |
False |
|
| inputs |
None |
|
3. 转换
as_strided 生成视图
| 参数名 |
默认值 |
说明 |
| size |
- |
输出tensor的形状 |
| stride |
- |
生成视图时每一个维度的步长 |
| storage_offset |
0 |
偏移量 |
a = torch.randn(3, 3)
b = torch.as_strided(a, (2, 2, 2), (1, 3, 1), 1)
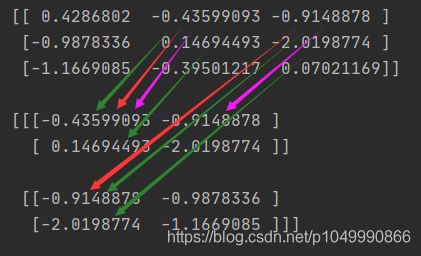
由于示例偏移量是1所以从第二个元素开始生成视图
如图红色是第一个维度, 每隔一个元素取一个值
绿色是第二个维度, 每隔三个元素取一个值
紫色是第三个维度, 每隔一个元素取一个值
bfloat16 将数据类型转换为bfloat16
等同于 self.to(torch.bfloat16)
| 参数名 |
默认值 |
说明 |
| memory_format |
torch.preserve_format |
|
4. 其它
apply_ 对每一个元素进行替换
仅适用于CPU处理器
此函数类似于python的map
| 参数名 |
默认值 |
说明 |
| callable |
- |
输入一个值输出一个值的函数 |