数据分析-深度学习 Pytorch Day7
图像识别:CIFAR10图形识别
1.CIFAR10数据集共有60000张彩色图像,这些图像式32*32*3,分为10个类,每个类6000张
2.这里面有50000张用于训练,构成5个训练批,每一批10000张图;另外10000张用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。
3.一个训练批中的各类图像并不一定数量相同,总的来看训练集,每一类都有5000张图片

# 导入包
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms,datasets
# 设置transforms
transform = transforms.Compose([
transforms.ToTensor(), # numpy -> Tensor
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) # 归一化 ,范围[-1,1]
])
# 下载训练数据集
# 训练集
trainset = datasets.CIFAR10(root='./CIFAR10',train=True,download=True,transform=transform)
# 测试集
testset = datasets.CIFAR10(root='./CIFAR10',train=False,download=True,transform=transform)
出现如下图结果数据集下载成功

# 批量获取数据
from torch.utils.data.dataloader import DataLoader
BATCH_SIZE = 32
train_loader = DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True,num_workers=8,pin_memory=True)
test_loader = DataLoader(testset,batch_size=BATCH_SIZE,shuffle=True,num_workers=8,pin_memory=True)
注意:其中BATCH_SIZE = 32 中的32 可以根据自己电脑配置来定,配置高可以定128 低可以定16
# 可视化显示
import matplotlib.pyplot as plt
import numpy as np
# 十个类别
classes = ('plane','car','bird','cat','deer',
'dog','frog','horse','ship','truck')
def imshow(img):
img = img / 2 + 0.5 # 逆正则化
np_img = img.numpy() # tensor --> numpy
plt.imshow(np.transpose(np_img,(1,2,0))) # 改变通道顺序
plt.show()
# 随机获取一批数据
imgs,labs = next(iter(train_loader))
print(imgs.shape)
print(labs.shape)
#调用方法
imshow(torchvision.utils.make_grid(imgs))
# 输出这批图片对应的标签
print(' '.join('%5s' % classes[labs[i]] for i in range(BATCH_SIZE))) 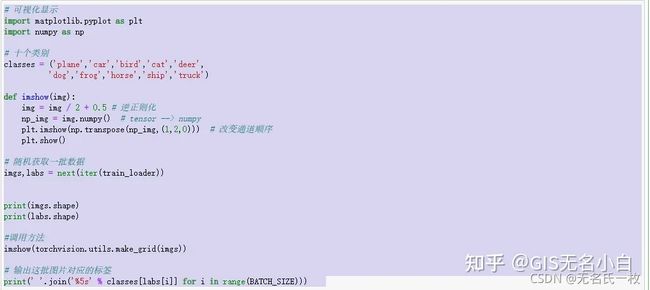
结果如下:

其中
torch.Size([32, 3, 32, 32])
torch.Size([32])中32代表32张图片,3代表3个通道,32代表像素
# 定义网络模型
import torch.nn as nn
import torch.nn.functional as F
'''
知识点:
1.特征图尺寸的计算公式为:[(原图片尺寸 = 卷积核尺寸) / 步长] + 1
'''
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 卷积层1.输入是32*32*3,计算(32-5)/ 1 + 1 = 28,那么通过conv1输出的结果是28*28*6
self.conv1 = nn.Conv2d(3,6,5) # imput:3 output:6, kernel:5
# 池化层, 输入时28*28*6, 窗口2*2,计算28 / 2 = 14,那么通过max_poll层输出的结果是14*14*6
self.pool = nn.MaxPool2d(2,2) # kernel:2 stride:2
# 卷积层2, 输入是14*14*6,计算(14-5)/ 1 + 1 = 10,那么通过conv2输出的结果是10*10*16
self.conv2 = nn.Conv2d(6,16,5) # imput:6 output:16, kernel:5
# 全连接层1
self.fc1 = nn.Linear(16*5*5, 120) # input:16*5*5,output:120
# 全连接层2
self.fc2 = nn.Linear(120, 84) # input:120,output:84
# 全连接层3
self.fc3 = nn.Linear(84, 10) # input:84,output:10
def forward(self,x):
# 卷积1
'''
32x32x3 --> 28x28x6 -->14x14x6
'''
x = self.pool(F.relu(self.conv1(x)))
# 卷积2
'''
14x14x6 --> 10x10x16 --> 5x5x16
'''
x = self.pool(F.relu(self.conv2(x)))
# 改变shape
x = x.view(-1,16*5*5)
# 全连接层1
x = F.relu(self.fc1(x))
# 全连接层2
x = F.relu(self.fc2(x))
# 全连接层3
x = self.fc3(x)
return x 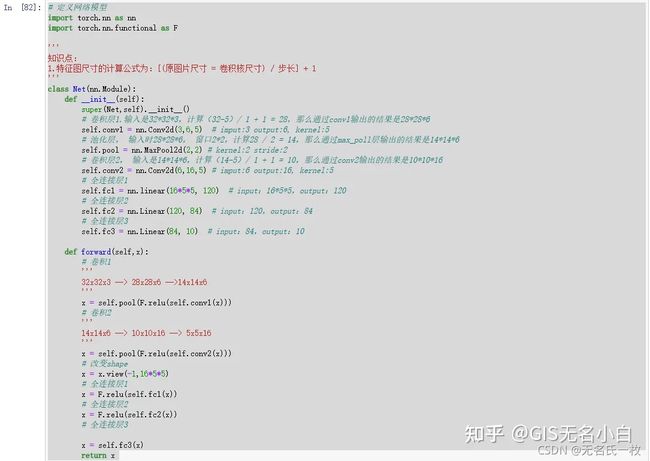
注意:__init__这一块下划线要注意,按理说只要将模型定义到__init__()里就ok了,但是大家容易少打一个下划线会报错,将下划线_改为__即可解决问题。
# 创建模型
net = Net().to('cuda')
电脑有GPU的话这一步是部署到CUDA上运行调用GPU, 这一步容易出现下图问题:
这时候多运行几次,代码是没有问题的,应为JUPYTER是在网页上运行,需要时间反应,多运行几次
如果出现以下问题:
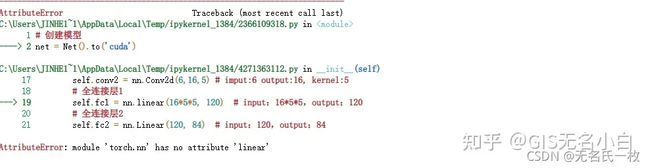
注意Linear中的L要大写
# 定义优化器和损失函数
import torch.optim as optim
criterion = nn.CrossEntropyLoss() # 交叉式损失函数
optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9) # 优化器
# 定义函数
EPOCHS = 200
for epoch in range(EPOCHS):
train_loss = 0.0
for i, (datas,labels) in enumerate(train_loader):
datas,labels = datas.to('cuda'),labels.to('cuda')
# 梯度置零
optimizer.zero_grad()
# 训练
outputs = net(datas)
# 计算损失
loss = criterion(outputs,labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 累计损失
train_loss += loss.item()
# 打印信息
print(epoch+1, i+1,train_loss/len(train_loader.dataset))
循环次数可以自己设置,这里设置为200轮,for循环读取训练集
输出结果如下:

# 测试
correct = 0
total = 0
# flag=True
with torch.no_grad():
for i , (datas,labels) in enumerate(test_loader):
# 输出
outputs = model(datas) # outputs.data,shape --> torch.Size([128,10])
_, predicted = torch.max(outputs.data, dim=1) # 第一个是值得张量,第二个是序号张量
# 累计数据值
total += labels.size(0) # labels.size() --> torch.Size([128]) , labels.size(0) --> 128
# 比较有多少个预测正确
correct += (predicted == labels).sum() # 相同为1,不同为0,利用sum()总求和
print("在1000张测试集图片上的准确率:{:.3f}%".format(torch.true_divide(correct,total))# 显示每一类预测的概率
class_correct = list(0. for i in range(10))
total = list(0. for i in range(10))
with torch.no_grad():
for (images,labels) in test_loader:
outputs = model(images) # 输出
_,predicted = torch.max(outputs,dim=1) # 获取到每一行的最大索引
c = (predicted ==labels).squeeze() # squeeze() 去掉0维【默认】,unsqueeze() 增加一维
if labels.shape[0] == 128:
for i in range(BATCH_SIZE):
label = labels[i] # 获取每一个label
class_correct[label] += c[i].item() # 累计维True都个数,注意:1 + True = 2,1 + False = 1
total[label] += 1 # 该类总的个数
# 输出正确率
for i in range(10):
print("正确率 : %5s : $2d %%" % (classes[i],100 * class_correct[i] / total[i])