sklearn.metrics中的评估方法介绍
- accuracy_score
分类准确率分数是指所有分类正确的百分比。分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。
- 形式:
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数

- recall_score
召回率 =提取出的正确信息条数 /样本中的信息条数。通俗地说,就是所有准确的条目有多少被检索出来了。
- 形式:
sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average='binary', sample_weig

- roc_curve
ROC曲线指受试者工作特征曲线/接收器操作特性(receiver operating characteristic,ROC)曲线,是反映灵敏性和特效性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性。ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真正例率(也就是灵敏度)(True Positive Rate,TPR)为纵坐标,假正例率(1-特效性)(False Positive Rate,FPR)为横坐标绘制的曲线。
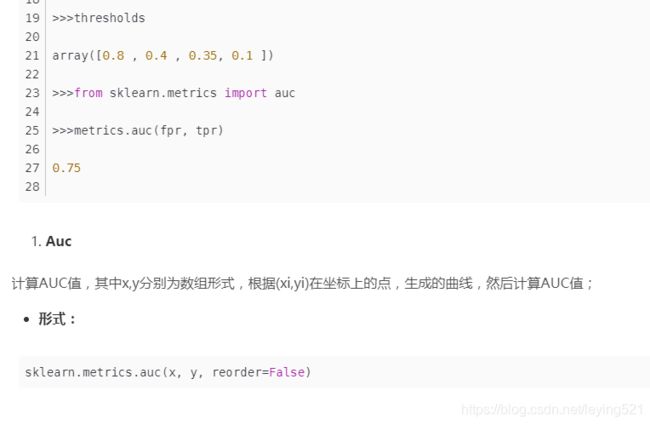
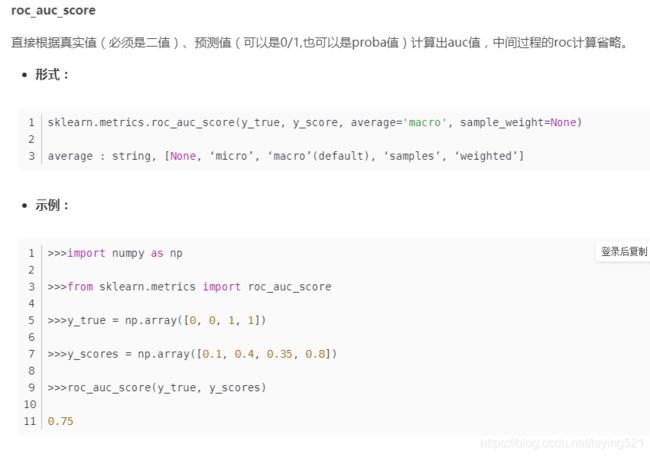
ROC观察模型正确地识别正例的比例与模型错误地把负例数据识别成正例的比例之间的权衡。TPR的增加以FPR的增加为代价。ROC曲线下的面积是模型准确率的度量,AUC(Area under roccurve)。
纵坐标:真正率(True Positive Rate , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN) (正样本预测结果数 / 正样本实际数)
横坐标:假正率(False Positive Rate , FPR)
FPR = FP /(FP + TN) (被预测为正的负样本结果数 /负样本实际数)
- 形式:
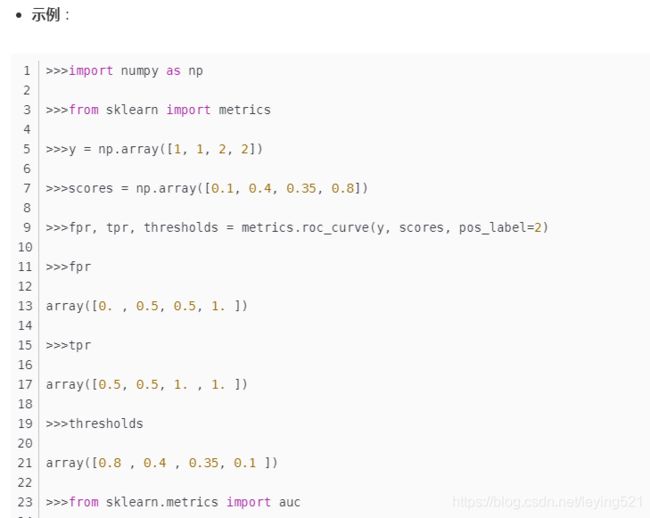
sklearn.metrics.roc_curve(y_true,y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
该函数返回这三个变量:fpr,tpr,和阈值thresholds;
这里理解thresholds:
分类器的一个重要功能“概率输出”,即表示分类器认为某个样本具有多大的概率属于正样本(或负样本)。
“Score”表示每个测试样本属于正样本的概率。
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。其实,我们并不一定要得到每个测试样本是正样本的概率值,只要得到这个分类器对该测试样本的“评分值”即可(评分值并不一定在(0,1)区间)。评分越高,表示分类器越肯定地认为这个测试样本是正样本,而且同时使用各个评分值作为threshold。我认为将评分值转化为概率更易于理解一些。


转自:https://blog.csdn.net/xieganyu3460/article/details/81205993