【Flink】详解Flink的八种分区
简介
Flink是一个流处理框架,一个Flink-Job由多个Task/算子构成,逻辑层面构成一个链条,同时Flink支持并行操作,每一个并行度可以理解为一个数据管道称之为SubTask。我们画图来看一下:

数据会在多个算子的SubTask之间相互传递,算子之间的并行度可能是不同的,这样就产生了数据分区问题,其核心问题在于上游的某个SubTask的数据该发送到下游的哪一个SubTask中。为了解决分区相关问题,Flink提供了一系列分区算子,下面将详细为大家介绍分区算子和相关的分区器。
分区算子
Flink一共有6种(rescale和rebalance都是轮询算子)或者7种分区算子:
- shuffle :调用
shuffle方法将会随机分配,总体上服从均匀分布; - rebalance:调用
rebalance方法将会轮询分配,对所有的并⾏⼦任务进⾏轮询分配,可能会导致TM之间的数据交换; - rescale:调用
rescale方法将会以组为单位轮训分配,而不是整体进行轮训,为了避免TM之间的数据交互; - broadcast:调用
broadcast方法将数据流广播给所有的下游子任务; - global:调用
global方法将会进行全局分区,将上游所有数据发送到下游第一个分区中; - keyby:调用
keyby方法将会按键分区。 - 自定义规则:自定义数据分发策略。代表算子为partitionCustom。
分区器
概述
每一个分区算子的底层实际上对应一个分区器,一共8个分区器
- GlobalPartitioner
- ShufflePartitioner
- RebalancePartitioner
- RescalePartitioner
- BroadcastPartitioner
- ForwardPartitioner
- KeyGroupStreamPartitioner
- CustomPartitionerWrapper
各个分区器的继承关系如下:

接下来将详细介绍每一个分区算子和对应的分区器。
ChannelSelector
ChannelSelector是分区器共同实现的接口,定义分区器的基本行为。
public interface ChannelSelector<T extends IOReadableWritable> {
// 初始化ChannelSelector,传入的参数为下游channel的数量
void setup(int numberOfChannels);
// 返回选择的channel索引编号,这个方法决定的上游的数据需要写入到哪个channel中
// 这个方法的Partitioner子类重点需要实现的方法
// 对于broadcast广播类型算子,不需要实现这个方法
// 尽管broadcast不需要实现这个方法,但是还是重写了方法,throw new UnsupportedOperationException
// 传入的参数为记录数据流中的元素,该方法需要根据元素来推断出需要发送到的下游channel
int selectChannel(T record);
// 返回是否为广播类型
boolean isBroadcast();
}
StreamPartitioner
StreamPartitioner抽象类实现了StreamPartitioner接口,它的代码如下所示:
public abstract class StreamPartitioner<T>
implements ChannelSelector<SerializationDelegate<StreamRecord<T>>>, Serializable {
private static final long serialVersionUID = 1L;
// 下游的channel数量
protected int numberOfChannels;
// 初始化的时候就知道下游的channel数量
@Override
public void setup(int numberOfChannels) {
this.numberOfChannels = numberOfChannels;
}
// 肯定不是广播类型
@Override
public boolean isBroadcast() {
return false;
}
public abstract StreamPartitioner<T> copy();
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
final StreamPartitioner<?> that = (StreamPartitioner<?>) o;
return numberOfChannels == that.numberOfChannels;
}
@Override
public int hashCode() {
return Objects.hash(numberOfChannels);
}
// 决定了作业恢复时候上游遇到扩缩容的话,需要处理哪些上游状态保存的数据
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.ARBITRARY;
}
// 决定了作业恢复时候下游遇到扩缩容的话,需要处理哪些下游状态保存的数据
public abstract SubtaskStateMapper getDownstreamSubtaskStateMapper();
// 该方法定义了上下游之间的关系类型,如果返回True,表示上下游SubTask之间有明确的一一对应关系,如果返回False代表上下游SubTask之间没有明确的对应关系
public abstract boolean isPointwise();
}
ShufflePartitioner
@PublicEvolving
public DataStream<T> shuffle() {
return setConnectionType(new ShufflePartitioner<T>());
}
可以看到shuffle算子对应的分区器是【ShufflePartitioner】。
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private Random random = new Random();
// 重要
// 随机返回一个下游Channel,由于random.nextInt符合均匀分布,所以shuffle的数据分布也符合均匀分布
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return random.nextInt(numberOfChannels);
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.ROUND_ROBIN;
}
@Override
public StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();
}
// ShufflePartitioner上下游Subtask之间没有明确对应关系
@Override
public boolean isPointwise() {
return false;
}
@Override
public String toString() {
return "SHUFFLE";
}
}
图例

GlobalPartitioner
public DataStream<T> global() {
return setConnectionType(new GlobalPartitioner<T>());
}
可以看到global对应的分区器是【GlobalPartitioner】。
public class GlobalPartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
// 数据永远发往下游第一个SubTask。
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return 0;
}
@Override
public StreamPartitioner<T> copy() {
return this;
}
// 恢复任务的时候将会恢复到第一个任务。
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.FIRST;
}
// ShufflePartitioner上下游Subtask之间没有明确对应关系
@Override
public boolean isPointwise() {
return false;
}
@Override
public String toString() {
return "GLOBAL";
}
}
图例

ForwardPartitioner
public class ForwardPartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
// 还是发往下游第一个SubTask,不同的是这里的下游SubTask是在本地的。
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return 0;
}
public StreamPartitioner<T> copy() {
return this;
}
// 上下游SubTask是一一对应的,如果上下游算子并行度不一致就会报错
@Override
public boolean isPointwise() {
return true;
}
@Override
public String toString() {
return "FORWARD";
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
}
ForwardPartitioner在StreamGraph的addEdgeInternal方法中自动创建(生成StreamGraph的过程),代码片段如下所示:
// ...
if (partitioner == null
&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
// 只有在上游和下游的并行度相同且没有指定相关分区器的时候,才会使用ForwardPartitioner
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
// 否 则使用RebalancePartitioner
partitioner = new RebalancePartitioner<Object>();
}
// 这里还会再次检测上游和下游的并行度是否一致
// 防止用户强行指定使用ForwardPartitioner时候上下游的并行度不一致
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException(
"Forward partitioning does not allow "
+ "change of parallelism. Upstream operation: "
+ upstreamNode
+ " parallelism: "
+ upstreamNode.getParallelism()
+ ", downstream operation: "
+ downstreamNode
+ " parallelism: "
+ downstreamNode.getParallelism()
+ " You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
// ...
或者调用forward算子创建,这个方法基本不使用。
public DataStream<T> forward() {
return setConnectionType(new ForwardPartitioner<T>());
}
图例

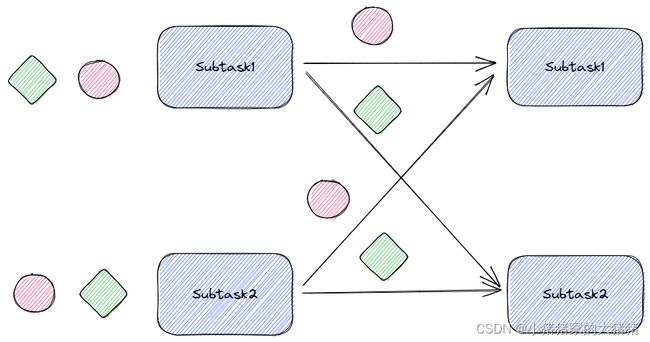
RebalancePartitioner
public DataStream<T> rebalance() {
return setConnectionType(new RebalancePartitioner<T>());
}
可以看到rebalance对应的分区器是【RebalancePartitioner】。
public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
// 记录要接受数据的下游Channel编号
private int nextChannelToSendTo;
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
// 采用取余的方式找出发送的下游channel
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
// 恢复的时候将保存数据轮询发送
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.ROUND_ROBIN;
}
public StreamPartitioner<T> copy() {
return this;
}
// 上下游SubTask之间没有意义对应关系
@Override
public boolean isPointwise() {
return false;
}
@Override
public String toString() {
return "REBALANCE";
}
}
图例
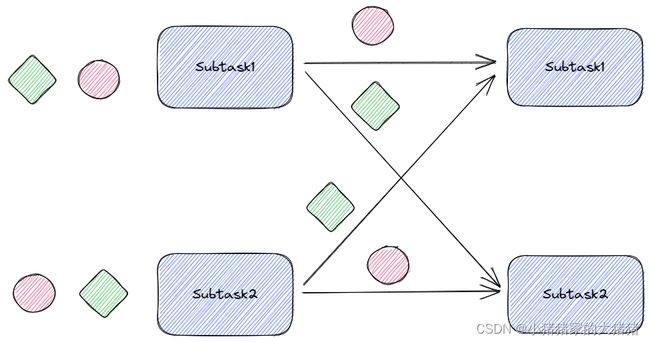
RescalePartitioner
public DataStream<T> rescale() {
return setConnectionType(new RescalePartitioner<T>());
}
可以看到rescale对应的分区器是【RescalePartitioner】。跟rebalance不同,例如上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。如果上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。(可以理解是一种负载均衡的轮询)
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
// 采用的方式和rebalance一致,都是轮询的策略
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
// 恢复的时候不支持扩缩容,因为原本的对应关系已经被破坏了
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
// 恢复的时候不支持扩缩容,因为原本的对应关系已经被破坏了
@Override
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "RESCALE";
}
// 这是有一一对应关系的分区方式
@Override
public boolean isPointwise() {
return true;
}
}
图例

KeyGroupPartitioner
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key) {
Preconditions.checkNotNull(key);
return new KeyedStream<>(this, clean(key));
}
// 调用keyby返回一个KeyedStream
// 在KeyedStream底层用一个PartitionTransformation包装了KeyGroupStreamPartitioner(键提取器,和默认最大键组数)
//
public KeyedStream(
DataStream<T> dataStream,
KeySelector<T, KEY> keySelector,
TypeInformation<KEY> keyType) {
this(
dataStream,
new PartitionTransformation<>(
dataStream.getTransformation(),
new KeyGroupStreamPartitioner<>(
keySelector,
StreamGraphGenerator.DEFAULT_LOWER_BOUND_MAX_PARALLELISM)),
keySelector,
keyType);
}
以下是【KeyGroupStreamPartitioner】的源码分析
public class KeyGroupStreamPartitioner<T, K> extends StreamPartitioner<T>
implements ConfigurableStreamPartitioner {
private static final long serialVersionUID = 1L;
private final KeySelector<T, K> keySelector;
private int maxParallelism;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
K key;
try {
// 通过keySelector获取键
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException(
"Could not extract key from " + record.getInstance().getValue(), e);
}
//
return KeyGroupRangeAssignment.assignKeyToParallelOperator(
key, maxParallelism, numberOfChannels);
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.RANGE;
}
// 上下游SubTask没有一一对应关系
@Override
public boolean isPointwise() {
return false;
}
// 这里是检查是否配置了最大并行度(最大建组数),如果有配置则替代默认值
@Override
public void configure(int maxParallelism) {
KeyGroupRangeAssignment.checkParallelismPreconditions(maxParallelism);
this.maxParallelism = maxParallelism;
}
}
// 包装了一层检查一下键是否是null
// key:键;
// maxParallelis:支持的最大并行度,也就是键组的数量
// parallelism:当前并行度
public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
// 分配键组
// key:键;
// maxParallelis:支持的最大并行度,也就是键组的数量
public static int assignToKeyGroup(Object key, int maxParallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
// 通过键组ID*当前并行度/最大键组数量默认128来分配数据流向的channel
// maxParallelis:支持的最大并行度,也就是键组的数量
// parallelism:当前并行度
// keyGroupId:键组ID
public static int computeOperatorIndexForKeyGroup(int maxParallelism, int parallelism, int keyGroupId) {
return keyGroupId * parallelism / maxParallelism;
}
图例
Flink如何使用分区器
Flink通过RecordWriter向下游写入输入。RecordWriter通过RecordWriterBuilder创建。
public RecordWriter<T> build(ResultPartitionWriter writer) {
if (selector.isBroadcast()) {
return new BroadcastRecordWriter<>(writer, timeout, taskName);
} else {
return new ChannelSelectorRecordWriter<>(writer, selector, timeout, taskName);
}
}
在build方法中会调用【selector】的isBroadcast方法,如果是广播类型,则创建【BroadcastRecordWriter】对象来写数据,否则创建【ChannelSelectorRecordWriter】对象来写数据。
以下是【BroadcastRecordWriter】对象的源码分析:
public final class BroadcastRecordWriter<T extends IOReadableWritable> extends RecordWriter<T> {
broadcastEmit方法
// writer都是调用emit方法,在BroadcastRecordWriter中进行了包装,实质调用的是broadcastEmit方法
@Override
public void emit(T record) throws IOException {
broadcastEmit(record);
}
@Override
public void broadcastEmit(T record) throws IOException {
// 检查
checkErroneous();
// 先使用序列化器将数据序列化,然后进行广播
targetPartition.broadcastRecord(serializeRecord(serializer, record));
if (flushAlways) {
flushAll();
}
}
}
以下是【ChannelSelectorRecordWriter】对象源码分析:
public final class ChannelSelectorRecordWriter<T extends IOReadableWritable>
extends RecordWriter<T> {
private final ChannelSelector<T> channelSelector;
@Override
public void emit(T record) throws IOException {
// 分区器根据当前记录计算出下游Subtask的索引,然后发送
emit(record, channelSelector.selectChannel(record));
}
protected void emit(T record, int targetSubpartition) throws IOException {
checkErroneous();
// 先进行序列化操作
// targetSubpartition就是上一步中分区器计算的SubTask索引
targetPartition.emitRecord(serializeRecord(serializer, record), targetSubpartition);
if (flushAlways) {
targetPartition.flush(targetSubpartition);
}
}
}
总结
- Flink本身提供了多种分区API,在底层使用的都是分区器,Flink一般提供了7种分区器;
- 按键分区本质上是按键组分区,通过分配键组的方式分配键;
rescale(本地轮流分配)和rebalance(轮流分配)有区别,前者考虑了TM之间数据传输的问题,可以理解是一种软负载均衡的轮询;
往期回顾
- 【Flink】浅谈Flink背压问题(1)
- 【分布式】浅谈CAP、BASE理论(1)
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,列表相关的知识点也可进行分享。