机器学习算法--03聚类算法
本文是对聚类算法的概念、原理的学习,并附有代码,特别学习了聚类算法中的两种常见算法:KMeans和DBSCAN
一、什么是聚类
1.含义
聚类(Clustering) 是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大,即把相似的东西分到一组;
参考自https://zhuanlan.zhihu.com/p/104355127
聚类算法是一种典型的无监督学习算法(输入只有特征值,没有目标值,没有确定的结果),主要用于将相似的样本自动归类到一个类别中。【聚类算法是⽆监督的学习算法,⽽分类算法属于监督的学习算法。】
难点:如何评估,如何调参
2.应用
1.针对目标用户的群体分类:
广告推荐、到店针对性服务……
2.针对商品:
歌曲推荐、视频推荐、购物推荐……
3.其他:
图像分割,降维,识别、离群点检测……
二、KMeans算法
1.k-means的含义
- K : 初始中心点个数(计划聚类数,也叫质心数)
- means:求中心点到其他数据点距离的平均值
新手推荐:什么是 K-Means(K均值聚类)?【知多少】_哔哩哔哩_bilibili
2.算法具体流程
- 随机设置K个特征空间内的点作为初始的聚类中心,如下图b;
- 对于其他每个点计算到K个中心的距离,接着其他点选择最近的⼀个聚类中心点作为自己的标记类别,如下图c;
- 之后重新计算出每个聚类的新中心点(把每个点的X加起来取平均值就是新中心点的X,Y同理),如下图d;
- 如果计算得出的新中心点与原中心点⼀样(质心不再移动),那么结束,否则重新进行第二步过程,如下图e、f;
详细步骤见:机器学习算法 06 —— 聚类算法(k-means、算法优化、特征降维、主成分分析PCA)

3.KMeans代码
import numpy as np
class KMeans:
#构造函数
def __init__(self,data,num_clusters):#注意 init 两边的占位符“_”应是两个
self.data=data
self.num_clusters=num_clusters
def train(self,max_iterations):
#1.先随机选择K个中心点
centroids=KMeans.centroids_init(self.data,self.num_clusters)
#2.开始训练
num_examples=self.data.shape[0]#行
closest_centroids_ids=np.empty((num_examples,1))#np.empty()--依据给定形状和类型(shape,[dtype, order])返回一个新的空数组
#print(closest_centroids_ids.shape())
for _ in range(max_iterations):
#3.得到当前每一个样本点到K个中心点的距离,并找到最近的
closest_centroids_ids=KMeans.centroids_find_closest(self.data,centroids)
#4.进行中心点位置更新
centroids=KMeans.centroids_compute(self.data,closest_centroids_ids,self.num_clusters)
return centroids,clostest_centroids_ids
def centroids_init(self,data,num_clusters):# 随机选择k个初始点
num_examples=data.shape[0]#行数:150
#random_ids[:num_clustres]#取前num_clustres个数
random_ids=np.random.permutation(num_examples)#随机排列序列,对[0,num_examples)之间的序列进行随机排序,是一个一维数组
#以前3个数为下标再取值
centroids=data[random_ids[:num_clusters],:]
return centroids
def centroids_find_closest(data,centroids):
num_examples=data.shape[0]
num_centroids=centroids.shape[0]
closest_centroids_ids=np.zeros((num_examples,1))
for example_index in range(num_examples):
distance=np.zeros((num_centroids,1))# 对每个样本构造一个距离矩阵(每个样本到中心点的距离)
for centroid_index in range(num_centroids):
distance_diff=data[example_index,:]-centroids[centroid_index,:]
distance[centroids_index]=np.sum(distance_diff**2)
closest_centroids_ids[example_index]=np.argmin(distance)#选最小距离
return clostest_centroids_ids
def centroids_compute(data,closest_centroids_ids,num_clusters):#利用均值,更新簇的中心点
num_fetures=data.shape[1]#列
centroids=np.zeros((num_clusters,num_features))#矩阵第一维度是K,第二维度是特征的个数
for centroids_id in range(num_clusters):
closest_ids=closest_centroids_ids==centroid_id#得到点的归属
centroids[centroid_id]=np.mean(data[closest_ids.flatten(),:],axis=0)
return centroids
相关知识点:
① data.shape[0]
- 而对于矩阵来说:
shape[0]:表示矩阵的行数
shape[1]:表示矩阵的列数 - 对于图像来说:
image.shape[0]——图片高
image.shape[1]——图片长
image.shape[2]——图片通道数
一般来说,-1代表最后一个,所以shape[-1]代表最后一个维度,如在二维张量里,shape[-1]表示列数,注意,即使是一维行向量,shape[-1]表示行向量的元素总数,换言之也是列数;参考自:shape[0/1/-1]
② np.random.permutation():随机排列序列

4.KMeans算法的应用
4.1自创数据集调用KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
# 创建数据集
# X为样本特征,y为样本簇类别。创建1000个样本,每个样本2个特征,共4个簇(因为有四个簇中心点,所以就有四个簇)。
X, y = make_blobs(n_samples=1000,#数据样本点个数,默认值100
n_features=2,#每个样本的特征(或属性)数,也表示数据的维度,默认值是2
centers=[[-1,1],[0,0],[1,1],[2,2], [3,3]], # 每个簇的中心点
cluster_std=[0.4,0.2,0.2,0.2, 0.3], # 每个簇的方差
random_state=9)
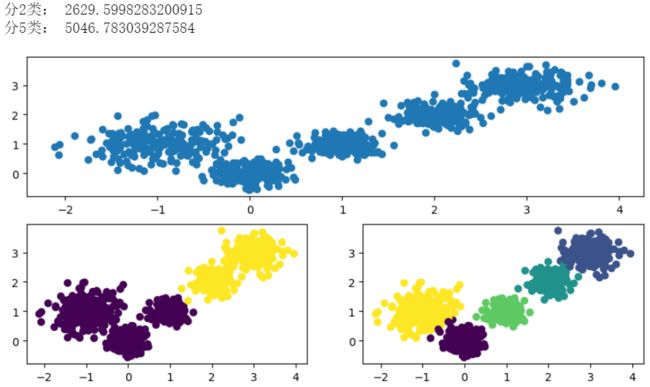
# 图像化展示
# 创建画布
fig = plt.figure(figsize=(10, 5), dpi=100)
ax1 = fig.add_subplot(211)
ax1.scatter(X[:, 0], X[:, 1])
# 使用K-means进行聚类-2类
# 创建估计器
estimator = KMeans(n_clusters=2, random_state=9)
# 开始训练并得到预测值
y_pre1 = estimator.fit_predict(X)
# 图像化展示
ax2 = fig.add_subplot(223)
ax2.scatter(X[:, 0], X[:, 1], c=y_pre1)
# 用Calinski-Harabasz 评估聚类情况(越大越好)
print("分2类:", calinski_harabasz_score(X, y_pre1))
# 使用K-means进行聚类-5类
# 创建估计器
estimator = KMeans(n_clusters=5, random_state=9)
# 开始训练并得到预测值
y_pre2 = estimator.fit_predict(X)
# 图像化展示
ax3 = fig.add_subplot(224)
ax3.scatter(X[:, 0], X[:, 1], c=y_pre2)
# 用Calinski-Harabasz 评估聚类情况(越大越好)
print("分5类:", calinski_harabasz_score(X, y_pre2))
plt.show()
结果:
相关知识点:
① KMeansAPI
sklearn.cluster.KMeans
中文详细介绍:https://blog.csdn.net/xiaoQL520/article/details/78269539
② 评估方法:
评估聚类的方法主要有两种:
- 内部评估方法:不需要借助其他监督数据,通过一个单一的量化得分评估算法好坏
- 外部评估方法:需要知道数据的类别,通过将聚类结果与ground truth进行对比,评估算法好坏
Calinski-Harbasz Score 属于内部评估方法
详细见下面聚类评估方法的轮廓系数法
4.2调用自创KMeans+鸢尾花数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#从k_means文件中导入KMeans类
from k_means import KMeans
#读取数据集
data = pd.read_csv('./iris.csv')
iris_types = ['SETOSA','VERSICOLOR','VIRGINICA']
x_axis = 'petal_length'
y_axis = 'petal_width'
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
for iris_type in iris_types:
#散点图:plt.scatter(x,y,label)
#先选x轴:data[x_axis],再做判断,判断它是否属于这个类别,因为要做三次画
plt.scatter(data[x_axis][data['class']==iris_type],data[y_axis][data['class']==iris_type],label = iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1,2,2)
plt.scatter(data[x_axis][:],data[y_axis][:])
plt.title('label unknown')
plt.show()
num_examples = data.shape[0]
x_train = data[[x_axis,y_axis]].values.reshape(num_examples,2)
#指定好训练所需的参数
num_clusters = 3
max_iteritions = 50
#创建KMeans类对象
k_means = KMeans(x_train,num_clusters)
centroids,closest_centroids_ids = k_means.train(max_iteritions)
# 对比结果
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class']==iris_type],data[y_axis][data['class']==iris_type],label = iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1,2,2)
for centroid_id, centroid in enumerate(centroids):
current_examples_index = (closest_centroids_ids == centroid_id).flatten()
plt.scatter(data[x_axis][current_examples_index],data[y_axis][current_examples_index],label = centroid_id)
for centroid_id, centroid in enumerate(centroids):
plt.scatter(centroid[0],centroid[1],c='black',marker = 'x')
plt.legend()
plt.title('label kmeans')
plt.show()
结果:

这是一个对比实验,左边的图是根据已知的label画出的,右边是用kmeans算法训练前后的聚类图,通过比较下面两张图可知:大部分是分对了,只有少部分没分对
相关知识点:
①iris数据集
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html
鸢尾花数据集简介:
该数据集一共包含4个特征变量,1个类别变量。共有150个样本,iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。

iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一行代表某个被测量的鸢尾植物,一共采样了150条记录。
这里只用了花瓣长度和宽度两列的数据
4.3聚类算法实践
完整代码:https://github.com/GrowUpward/MechineLearningAlgorathms/blob/main/03%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/03%E8%81%9A%E7%B1%BB.ipynb
代码包含:
①自创数据集+决策边界,
重点理解KMeans(n_clusters=8, *, init=‘k-means++’, n_init=‘warn’, max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm=‘lloyd’)中的参数–n_init
②聚类评估方法:
- 误差平方和(SSE)
误差平方和(The sum of squares due to error)真实值和误差值的差的平方再求整体和;
对应KMeans中的 inertia:每个样本与其质心距离的平方和
kmeans.inertia_==-kmeans.score(X) #X是数据集 - 肘方法
如果k值越大,得到的结果肯定会越来越小,但是这却不是我们想要的结果,为了得到最佳k值,我们可以采用此方法;
肘方法(Elbow method)是用来确定K值的,也就是看分成几个类别。
每次聚类完成后计算每个点到其所属簇的中心点的距离平方和,在这个平方和变化过程中,会出现⼀个拐点也即“肘”点,下降率突然变缓时即认为是最佳的k值;还可以用此方法确定最大迭代次数。

- 轮廓系数法
也就是上面的Calinski-Harbasz Score
a:当前样本点与同类的其他样本点的平均距离,b:当前样本点与最接近的另一个类的其他样本点的平均距离。当前样本点的得分是s

s衡量的是当前样本点是否离当前类的其他样本点近,并且与最接近的另一个类足够远。对于每个样本点都需要计算这样一个得分,计算复杂度较大。
- a->小,b->大,当前样本点在该簇的可能性越大,s=1,模型效果越好
- a->大,b->小,当前样本点在该簇的可能性越小,s=-1,模型效果越差
- -1
KMeans存在的问题:

此时bad_kmeans的inertia值为2179.48,而good_kmeans的inertia值为2241.90
因此inertia的值只能作为一个参考,并不能作为实际的判断指标,除此,肘方法和轮廓系数法也是;
③图像分割小例子

④用半监督学习做关于数字的聚类

5.KMeans的特点
优势:
- 简单,快速,适合常规数据集
劣势:
- K值难确定
- 复杂度与样本呈线性关系
- 很难发现任意形状的簇

三、DBSCAN算法
1.基本概念
(Density-Based Spatial Clustering of Applications with Noise)
- 核心对象:若某个点的密度达到算法设定的阈值则其为核心点。
(即 r 邻域内点的数量不小于 minPts) - ϵ-邻域的距离阈值:设定的半径r
- 直接密度可达:若某点p在点q的 r 邻域内,且q是核心点则p-q直接密度可达。
- 密度可达:若有一个点的序列q0、q1、…qk,对任意qi-qi-1是直接密度可达的,则称从q0到qk密度可达,这实际上是直接密度可达的“传播”。
- 密度相连:若从某核心点p出发,点q和点k都是密度可达的,则称点q和点k是密度相连的。
- 边界点:属于某一个类的非核心点,不能发展下线了
- 噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的
2.算法原理
如下图,假设A点为起始点,以A为圆心,以r为半径形成一个红色的圆圈,这个红色的圆圈根据一定的规则在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。其它没有被收纳的根据一样的规则成簇。(形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。
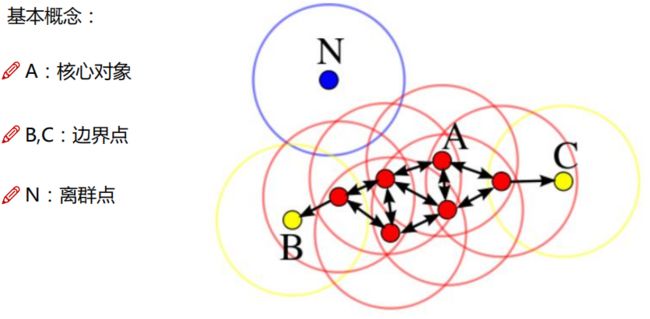
参考自:https://blog.csdn.net/huacha__/article/details/81094891
3.参数选择
- 半径ϵ,可以根据K距离来设定:找突变点
K距离:给定数据集P={p(i); i=0,1,…n},计算点P(i)到集合D的子集S中所有点
之间的距离,距离按照从小到大的顺序排序,d(k)就被称为k-距离。 - MinPts: k-距离中k的值,一般取的小一些,多次尝试
DBSCAN算法迭代可视化展示:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
4.特点
- 优势:
不需要指定簇个数
可以发现任意形状的簇
擅长找到离群点(检测任务)
两个参数就够了 - 劣势:
高维数据有些困难(可以做降维)
参数难以选择(参数对结果的影响非常大)
Sklearn中效率很慢(数据削减策略)
5.代码
参见:https://github.com/GrowUpward/MechineLearningAlgorathms/blob/main/03%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/03%E8%81%9A%E7%B1%BB.ipynb