一文搞懂attention机制
文章目录
-
- 1.简介
- 2.注意力背后的核心理念
- 3.为什么叫做attention
- 4.attention是如何工作的
-
- Decoding at time step 1
- 步骤1 - 计算每个编码器状态的分数
- 步骤2-计算注意力权重
- 步骤3-计算上下文向量
- 步骤4-将上下文向量与前一时间步的输出连接
- 步骤5-解码器输出
- 在时间步骤2解码
- 在时间步骤3解码
- 在时间步骤4解码
- 在时间步骤5解码
- 5.过一下代码
- 6.可视化结果
- 7.结论
- 8. References
翻譯地址:
https://towardsdatascience.com/intuitive-understanding-of-attention-mechanism-in-deep-learning-6c9482aecf4f
总览
https://zhuanlan.zhihu.com/p/31547842
0.了解seqtoseq模型,lstm,gru,变长输入映射到变长输出
1.什么是attention
2.不同的对齐方式确定了不同的attention
3.soft hard attention
1.简介
注意力是深度学习社区中最有影响力的想法之一。即使这种机制现在用于各种问题,如图像字幕等,它最初是在使用Seq2Seq模型的神经机器翻译的背景下设计的。在这篇博文中,我将考虑与运行示例相同的问题来说明这个概念。我们将使用注意力来设计一个将给定的英语句子翻译成马拉地语的系统,这与我在之前的博客中考虑的完全相同。
首先我们来看seqtoseq模型出了什么问题,
seq2seq模型通常由编码器 (encode)- 解码器(decode)架构组成,其中编码器处理输入序列并将信息编码/压缩/概括为固定长度的上下文向量(也称为“思想向量”)。该向量是整个输入序列的良好的压缩特征。然后用该上下文向量初始化解码器,使用该上下文向量开始生成变换后的输出。
这种固定长度的上下文矢量设计的一个关键和明显的缺点是系统无法记住更长的序列。一旦处理完整个序列,通常会忘记序列的早期部分。注意机制的诞生是为了解决这个问题。
让我们把它分解成更精细的细节。由于我已经解释了在我以前的博客中理解注意力所需的大部分基本概念,因此我将直接跳到问题的主题,而不再进一步说明。
2.注意力背后的核心理念
为了说明的目的,我将借用我之前博客中用于解释Seq2Seq模型的相同示例。
输入(英文)句子:“Rahul是个好孩子”
目标(马拉地语)句子:“राहुलचांगलामुलगाआहे”
唯一的变化是,我在前面的解释中使用的不是LSTM层,而是在这里我将使用GRU层。原因是LSTM有两个内部状态(隐藏状态和单元状态),GRU只有一个内部状态(隐藏状态)。这将有助于简化概念和解释。
回想下面的图表,其中我总结了Seq2Seq建模的整个过程过程。

在传统的Seq2Seq模型中,我们丢弃编码器的所有中间状态,并仅使用其最终状态(向量)来初始化解码器。该技术适用于较小的序列,但随着序列长度的增加,单个载体成为瓶颈,并且很难将长序列汇总到单个载体中。这种观察是凭经验进行的,因为注意到随着序列尺寸的增加,系统的性能急剧下降。
注意力背后的核心思想不是抛弃那些中间编码器状态,而是利用所有状态以构造解码器生成输出序列所需的上下文向量。
3.为什么叫做attention
让我们将编码器的每个中间状态命名为:

请注意,由于我们使用的是GRU而不是LSTM,因此我们在每个时间步都只有一个状态而不是两个状态,因此有助于简化说明。另请注意,特别是在序列较长的情况下,注意力是有用的,但为了简单起见,我们将考虑相同的上述示例进行说明
回想一下,这些状态(h1到h5)只不过是固定长度的矢量。为了发展一些直觉,可以将这些状态视为在序列中存储局部信息的向量。
例如;h1存储序列开头的信息(像’Rahul’和’is’这样的单词),而h5存储序列后面部分的信息(像’good’和’boy’这样的单词)
。让我们用我们的编码器GRU代表以下简化图:

Compact Representation of Encoder GRU
现在的想法是集体利用所有这些本地信息,以便在解码目标句子时决定下一个序列。
想象一下,你正在翻译“Rahul是一个好孩子”到“राहुलचांगलामुलगाआहे”。问问自己,你如何在脑海中做到这一点?
当你预测“राहुल”时,很明显这个名字是输入英语句子中出现的“Rahul”一词的结果,而不管句子的其余部分。我们说在预测“राहुल”的同时,我们更加关注输入句中的“Rahul”这个词。
同样,在预测单词“चांगला”时,我们更注重输入句子中的“good”这个词。
同样,在预测单词“मुलगा”时,我们会更加关注输入句子中的“boy”这个词。等等…
因此名称为“注意”。
作为人类,我们很快就能够理解输入序列的不同部分和输出序列的相应部分之间的这些映射。然而,人工神经网络不能直接自动检测这些映射。
因此,开发Attention机制是为了通过Gradient Descent和Back-propagation “学习”这些映射
4.attention是如何工作的
让我们获得技术并深入了解注意机制的细节。
Decoding at time step 1
继续上面的例子,假设我们现在希望我们的解码器开始预测目标序列的第一个单词,即“राहुल”
在时间步骤1,我们可以将整个过程分为以下五个步骤:
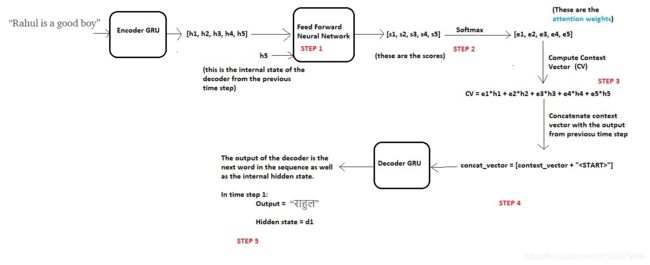
在我们开始解码之前,我们首先需要将输入序列编码为一组内部状态(在我们的例子中为h1,h2,h3,h4和h5)。
现在的假设是,输出序列中的下一个字取决于解码器的当前状态(解码器也是GRU)以及编码器的隐藏状态。因此,在每个时间步,我们考虑这两件事,并按照以下步骤:
步骤1 - 计算每个编码器状态的分数
由于我们预测第一个字本身,因此解码器没有任何当前的内部状态。出于这个原因,我们将编码器的最后状态(即h5)视为先前的解码器状态。
现在使用这两个组件(所有编码器状态和解码器的当前状态),我们将训练一个简单的前馈神经网络
为什么
回想一下,我们正在尝试预测目标序列中的第一个单词,即“राहुल”。根据注意力背后的想法,我们不需要所有编码器状态来预测该字,但我们需要那些在输入序列中存储关于单词“Rahul”的信息的编码器状态。
如前所述,这些中间编码器状态存储输入序列的本地信息。所以很有可能“Rahul”这个词的信息会出现在各州,比方说,h1和h2。
因此,我们希望我们的解码器更多地关注状态h1和h2,同时不太关注编码器的剩余状态。
出于这个原因,我们训练一个前馈神经网络 学习 通过为要关注的状态生成高分来识别相关的编码器状态,同时为要忽略的状态的低分获得。
设s1,s2,s3,s4和s5是相应地为状态h1,h2,h3,h4和h5生成的分数。由于我们假设我们需要更多地关注状态h1和h2并忽略h3,h4和h5以便预测“राहुल”,我们期望上述神经元产生得分,使得s1和s2高,而s3,s4和s5相对较低。
步骤2-计算注意力权重
一旦生成了这些分数,我们对这些分数应用softmax以产生如上所示的注意权重e1,e2,e3,e4和e5。应用softmax的优点如下:
a)所有权重介于0和1之间,即0≤e1,e2,e3,e4,e5≤1b)
所有权重总和为1,即e1 + e2 + 3 + e4 + e5 = 1
因此,我们得到了注意力量的一个很好的概率解释。
在我们的例子中,我们期望如下的值:(仅用于直觉)
e1 = 0.75,e2 = 0.2,e3 = 0.02,e4 = 0.02,e5 = 0.01
这意味着在预测单词“राहुल”时,解码器需要更多地关注状态h1和h2(因为e1和e2的值很高)而忽略状态h3,h4和h5(因为e3的值, e4和e5非常小)
步骤3-计算上下文向量
一旦我们计算了注意力权重,我们就需要计算解码器将使用的上下文向量(思维向量),以便预测序列中的下一个单词。计算方法如下:
context_vector = e1 * h1 + e2 * h2 + e3 * h3 + e4 * h4 + e5 * h5
显然,如果e1和e2的值高并且e3,e4和e5的值低,则上下文向量将包含来自状态h1和h2的更多信息以及来自状态h3,h4和h5的相对更少的信息
步骤4-将上下文向量与前一时间步的输出连接
最后,解码器使用以下两个输入向量来生成序列中的下一个字
a)上下文向量
b)从前一时间步骤生成的输出字。
我们简单地连接这两个向量并将合并的向量馈送到解码器。
**请注意,对于第一个步骤,由于上一个时间步骤没有输出,我们为此使用了一个特殊的标记。**我之前的博客已经详细讨论了这个概念。
步骤5-解码器输出
解码器然后生成序列中的下一个字(在这种情况下,期望生成“राहुल”)并且与输出一起,解码器还将生成内部隐藏状态,并将其称为“d1”。
在时间步骤2解码
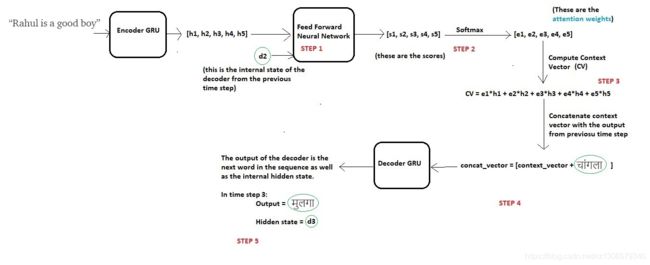
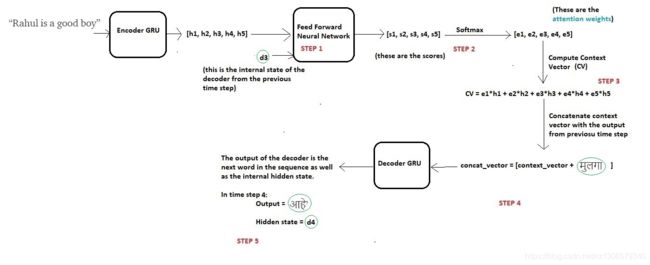
现在为了生成下一个单词“चांगला”,解码器将重复相同的过程,可以在下图中进行总结:
更改以绿色圆圈突出显示

在时间步骤3解码
在时间步骤4解码
在时间步骤5解码

一旦解码器输出令牌,我们就停止生成过程。
注意,与传统Seq2Seq模型的情况下用于所有解码器时间步长的固定上下文向量不同,这里在注意的情况下,我们通过每次计算注意权重来为每个时间步计算单独的上下文向量。
因此,使用这种机制,我们的模型能够在输入序列的不同部分和输出序列的相应部分之间找到有趣的映射。
请注意,在网络训练期间,我们使用强制输入实际单词而不是前一时间步骤中的预测单词(这段存疑)。这个概念也在我之前的博客中有所解释。
5.过一下代码
与任何NLP任务一样,在读取输入文件后,我们执行基本清理和预处理,如下所示:
创建一个类,将每个单词映射到索引,反之亦然,对于任何给定的词汇表:
我们使用tf.data输入管道来创建数据集,然后以小批量加载它。要阅读有关TensorFlow中输入管道的更多信息,请在此处和此处查看官方文档。
现在使用TensorFlow的模型子类API,我们定义模型如下。要阅读有关模型子类的更多信息,请阅读此处的官方文档
定义优化器,损失函数和检查点
使用Eager Execution,我们训练网络10个时期。要阅读有关Eager Execution的更多信息,请参阅此处的官方文档。
推理设置和测试:
6.可视化结果
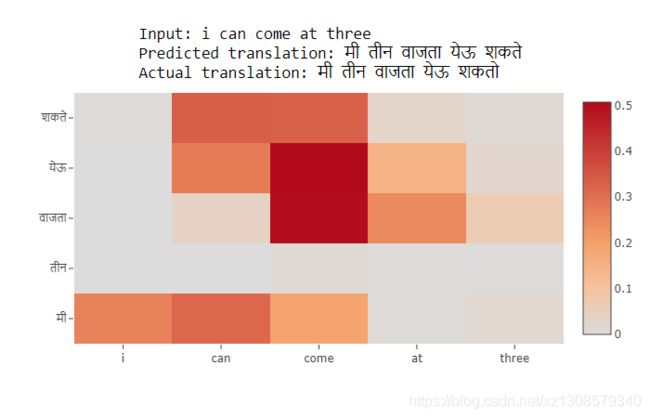
如果您不熟悉热图,可以使用以下方法解释上图:
请注意,“父亲”和“बाबांनी”交叉处的单元格非常暗。这意味着当解码器预测单词“बाबांनी”时,它会更加关注输入单词“father”(这是我们想要的)。

类似地,在预测单词“कॅमेरा”时,解码器非常注意输入单词“camera”。等等。




7.结论
首先要注意的是,翻译结果比我之前博客的结果要好得多。其次,模型能够在输入和输出序列之间找到与我们的直觉相匹配的正确局部映射。
给定更多数据和更多超参数调整,结果和映射肯定会有很大的提升。
使用LSTM层代替GRU并在编码器上添加双向lstm也有助于提高性能
深度学习模型通常被视为黑盒子,这意味着它们无法解释其输出。然而,注意力是成功的方法之一,有助于使我们的模型可解释并解释它为什么做它做的。
注意机制的唯一缺点是它非常耗时且难以并行化系统。为了解决这个问题,谷歌大脑提出了“
Transformer Model”,它只使用了注意力并摆脱了所有的卷积和循环层,从而使其具有高度可并行化和计算效率。
8. References
https://arxiv.org/abs/1409.0473 (Original Paper)
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb (TensorFlow Implementation available on their official website as a tutorial)
https://www.coursera.org/lecture/nlp-sequence-models/attention-model-lSwVa (Andrew Ng’s Explanation on Attention)
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
https://www.tensorflow.org/xla/broadcasting (Broadcasting in TensorFlow)
Dataset: http://www.manythings.org/anki/ (mar-eng.zip)
PS: For complete implementation, refer my GitHub repository here.