《PyTorch深度学习实践》学习笔记 【3】
《PyTorch深度学习实践》学习笔记 【3】
学习资源:
《PyTorch深度学习实践》完结合集
三、梯度下降
类似牛顿迭代法/ 二分法,对cost func 求导 , 利用偏导进行迭代,使得cost func 达到最小值。
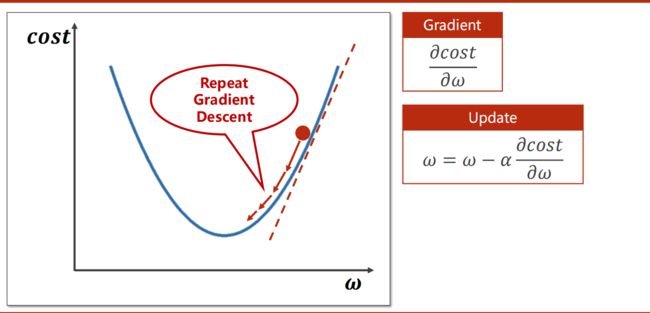
具体的求导过程

关键迭代式:

课上实例代码【2】
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
#线性函数
def forward(x):
return x * w
#MSE
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
#求导函数
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
#迭代!求w
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Epoch:', epoch, 'w=', w, 'loss=', cost_val)
print('Predict (after training)', 4, forward(4))
四、反向传播
4.1 背景
简单模型,直接可以利用损失函数对w的导数,来更新w
但是对于复杂模型,有成千上万个参数,无法直接给出固定的显示的损失函数解析式。
反向传播就是为了解决这个问题,首先看一下两层的网络[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sFK3K8qx-1628951953270)(C:\Users\26421\AppData\Roaming\Typora\typora-user-images\image-20210814165213414.png)]
令F(x)= Wx+b , 则两层的神经网络,相当于复合函数 F(F(x)),
复合函数运算后的结果仍然是线性函数。
每计算一层,就会使得最终的W和b不断调整,这样就实现了参数逼近的过程。
回过头看梯度下降法,就是通过计算损失函数的导数 来计算参数逼近 ;
这里没有用到导数,同样实现了参数的逼近。
矩阵求导的资料:《 MatrixCookbook矩阵手册》
有需要再查阅


4.2 前向传播 和 反向传播
前馈计算loss,反向计算导数
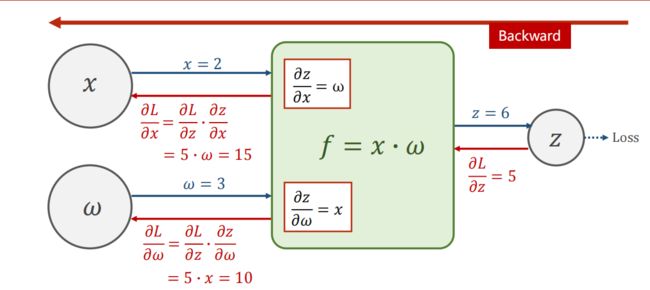
如果要计算 ∂ L o s s ∂ w \frac{\partial Loss}{\partial w} ∂w∂Loss ,按照你做题的思路求导,首先计算出各个导数的式子,再代入计算。
程序中也是如此,按照链式法则进行求导计算,从最底层出发,将各个导数值和函数值都计算出来。
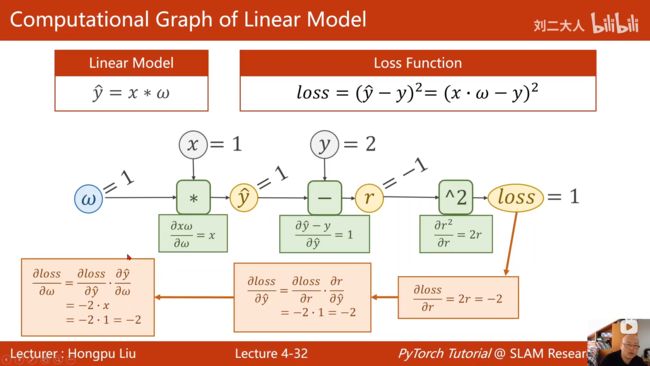
4. 3 Tensor
Tensor是TensorFlow中的基本数据类型,
Tensor中主要元素的是Data(数据)和Grad(导数)
4.4 代码部分
核心代码讲解:
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) ##1.计算loss(前向)
l.backward() ##2.计算偏导并保存在变量中(后向传播)
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data #3. 用梯度下降做更新
w.grad.data.zero_()# grad 设置为0
代码注释中的 1 2 3 步 可以看下面的图
五、用Pytorch实现线性回归
5.1 回顾
sgd: 随机梯度下降(需要对参数求偏导)
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) ##计算loss(前向)
l.backward() ##计算偏导并保存在变量中(后向传播)
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data #用梯度下降做更新
w.grad.data.zero_()# grad 设置为0
-
正向前馈:loss
-
反向反馈:计算梯度
-
梯度更新
-
清0(权重不会自动清零)
5.2 Pytorch 工具处理流程
5.2.1 四个步骤

- 准备数据
这里的X_data Y_data 都必须是矩阵(3*1 here)
之前我们做训练的过程,要人工求出导数解析式
现在我们的主要任务是构造计算图,(Pytorch可以自动求导数)
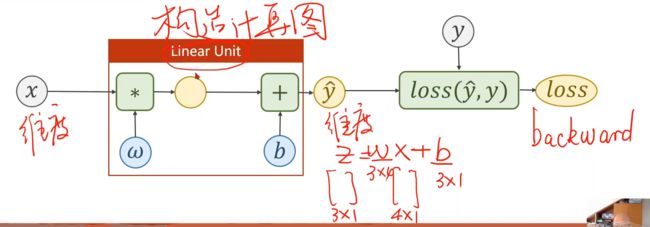
仿射模型,我们要确定W,b 的维数/形状(参数数目)
只要知道 X的维度 ,Y_head的维度 即可确定上面W,b的形状。
Loss函数求出来是和Y_head一样的维度,但是我们要对其反向传播,就需要将其标量化(eg.求和)
5.2.2 代码
重点讲一下第二步:实例化模型
import torch
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
##构造一个对象,包含Weight(参数w) 和 Bias(参数b) ,之后就可以直接用Linear计算Wx+b
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):##这里主要考虑的override,覆盖父类的默认函数
y_pred = self.linear(x)
return y_pred
model = LinearModel()##实例化一个对象
-
所有的模型都要继承自Module,因为Module中有很多方法是我们训练的时候必要的。
-
你需要至少__ init __() 和 forward() 两个函数
-
Module自动生成Backward()
-
未定义(比如无法求导,或者你想改进)的两种处理方法:
自定义(使用torch的基本方法)封装成Module
自定义计算块并继承自Functions类
全过程
## 1.准备数据
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
##2. 准备模型,实例化对象
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()## 父类
self.linear = torch.nn.Linear(1, 1)##构造一个对象,包含Weight(参数w) 和 Bias(参数b) ,之后就可以直接用Linear计算Wx+b
def forward(self, x):##这里主要考虑的override,覆盖父类的默认函数
y_pred = self.linear(x)
return y_pred
model = LinearModel()
##3. loss和优化器
criterion = torch.nn.MSELoss(size_average=False) ##计算MSE
##优化器:知道了哪些参数和学习率 , 未来就能够针对性地去优化
# 参数model.parameters()可以递归地找出模型里面的所有参数
# 参数lr:learning rate (就是w=w- α*导数 中的α)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
##4.经典训练三步走
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss)
optimizer.zero_grad() #清零,因为grad会累加
loss.backward() #Auto Grad
optimizer.step() #update
# Output weight and bias
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)