推荐算法--基于物品的协同过滤算法
“无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。”
ItemCF:ItemCollaborationFilter,基于物品的协同过滤
算法核心思想:给用户推荐那些和他们之前喜欢的物品相似的物品。
比如,用户A之前买过《数据挖掘导论》,该算法会根据此行为给你推荐《机器学习》,但是ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。
==>该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
基于物品的协同过滤算法主要分为两步:
一、计算物品之间的相似度;
二、根据物品的相似度和用户的历史行为给用户生成推荐列表;
下面分别来看这两步如何计算:
一、计算物品之间的相似度:
我们使用下面的公式定义物品的相似度:

其中,|N(i)|是喜欢物品i的用户数,|N(j)|是喜欢物品j的用户数,|N(i)&N(j)|是同时喜欢物品i和物品j的用户数。
从上面的定义看出,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,两个物品相似度越高,说明这两个物品共同被很多人喜欢。
这里面蕴含着一个假设:就是假设每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因而有很大的相似度。
举例,用户A对物品a、b、d有过行为,用户B对物品b、c、e有过行为,等等;

依此构建用户——物品倒排表:物品a被用户A、E有过行为,等等;
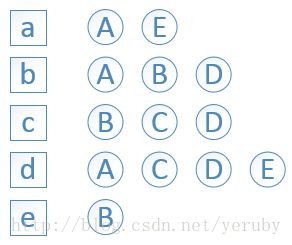
建立物品相似度矩阵C:
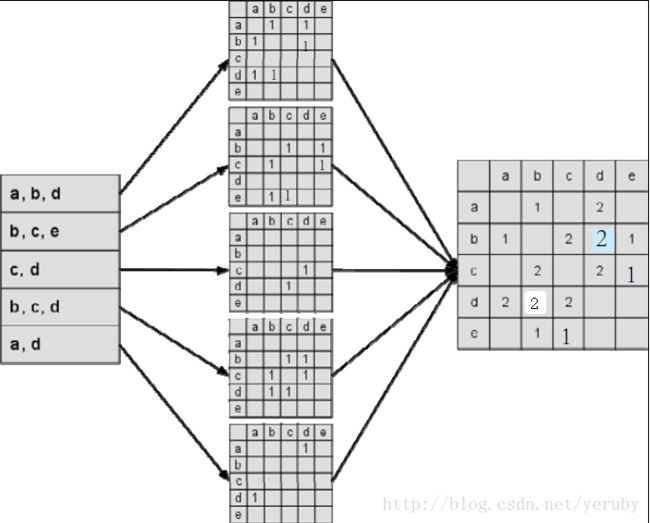
其中,C[i][j]记录了同时喜欢物品i和物品j的用户数,这样我们就可以得到物品之间的相似度矩阵W。
在得到物品之间的相似度后,进入第二步。
二、根据物品的相似度和用户的历史行为给用户生成推荐列表:
ItemCF通过如下公式计算用户u对一个物品j的兴趣:

其中,Puj表示用户u对物品j的兴趣,N(u)表示用户喜欢的物品集合(i是该用户喜欢的某一个物品),S(i,k)表示和物品i最相似的K个物品集合(j是这个集合中的某一个物品),Wji表示物品j和物品i的相似度,Rui表示用户u对物品i的兴趣(这里简化Rui都等于1)。
该公式的含义是:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
下面是一个书中的例子,帮助理解ItemCF过程:

至此,基础的ItemCF算法小结完毕。
下面是书中提到的几个优化方法:
(1)、用户活跃度对物品相似度的影响
即认为活跃用户对物品相似度的贡献应该小于不活跃的用户,所以增加一个IUF(Inverse User Frequence)参数来修正物品相似度的计算公式:

用这种相似度计算的ItemCF被记为ItemCF-IUF。
ItemCF-IUF在准确率和召回率两个指标上和ItemCF相近,但它明显提高了推荐结果的覆盖率,降低了推荐结果的流行度,从这个意义上说,ItemCF-IUF确实改进了ItemCF的综合性能。
(2)、物品相似度的归一化
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确度。其研究表明,如果已经得到了物品相似度矩阵w,那么可用如下公式得到归一化之后的相似度矩阵w':
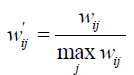
最终结果表明,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。
用这种相似度计算的ItemCF被记为ItemCF-Norm。