MS-Model【2】:nnFormer
文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
- 1.3. Related work
- 2. Method
-
- 2.1. Overview
- 2.2. Encoder
-
- 2.2.1. Components
- 2.2.2. The embedding layer
- 2.2.3. Local Volume-based Multi-head Self-attention (LV-MSA)
- 2.2.4. The down-sampling layer
- 2.3. Bottleneck
- 2.4. Decoder
-
- 2.4.1. Skip Attention
- 3. Experiment
-
- 3.1. Implementation details
-
- 3.1.1. Learning rate
- 3.1.2. Pre-processing and augmentation strategies
- 3.1.3. Deep supervision
- 3.2. Ablation study
- 总结
前言
本文在医学图像分割领域中的另一个十分常用的基线网络 nnUNet 的基础上修改得到,在多器官分割任务(十项全能数据集)上取得了十分不错的成绩
原论文链接:nnFormer: Interleaved Transformer for Volumetric Segmentation
论文复现参考:MS-Train【2】:nnFormer
本文中设计到的 3 个重要模型可以参考我的其他 blog:
CV-Model【6】:Vision Transformer
CV-Model【7】:Swin Transformer
MS-Model【1】:nnU-Net
1. Abstract & Introduction
1.1. Abstract
目前的方法要么不采用 Transformer,要么使用 Transformer 的效率不够高,无法捕捉医学成像中的长期依赖性
nnFormer 不仅利用交错卷积和自我注意操作的结合,而且还引入了基于局部和全局体积的自我注意机制来学习体积表示。此外,nnFormer 提出使用跳过注意力来取代传统的类似 U-Net 架构中跳过连接的串联/求和操作
这项任务是对三维计算机断层扫描(CT)中捕获的不同器官进行分割
1.2. Introduction
过往的一些主流模型通常将 ConvNets 作为主体,在此基础上进一步应用转化器来捕捉长期的依赖关系,但这样无法充分的发挥 Transformer 的优势。换句话说,一到两层的变换器不足以将长期依赖关系与卷积表征纠缠在一起,而卷积表征通常包含精确的空间信息并提供分层的概念
本文在技术上的主要贡献:
- 卷积和自我注意操作的交错组合
- 利用基于局部和全局体积的自我注意,分别建立特征金字塔和提供大的感受野
- 提出跳过注意,以取代跳过连接中的传统连接 / 求和操作
1.3. Related work
由于 Transformer 本身可以有效地捕捉和利用像素或体素之间的长期依赖(long-term dependencies),近期出现了非常多结合 CNN 和 Transformer 的针对医疗影像处理的模型和网络。其中大部分结果表明,在 CNN 中合适的位置嵌入类 Transformer 的结构,可以有效地提升网络的性能
基于 Transformer 的医疗影像处理模型和网络通常可以分为两类:
- 仍然使用
CNN作为主要的特征提取器,辅以类Transformer结构以捕捉特征中的全局信息,再将此信息嵌入到CNN中- nnU-Net
- 目前性能最好的全卷积医学分割神经网络
- nnU-Net 是 U-Net 架构的集合体,具有数据预处理、数据增强和后处理的自动化管道
- 对二维窗口 patches 比三维体积 patches 效果更好
- TransUNet
- 第一个提出的架构,在医学图像分割的背景下利用
Transformer Convnets被设计为特征提取器,Transformer层被覆盖以帮助编码全局背景
- 第一个提出的架构,在医学图像分割的背景下利用
- Swin-UNet
- 在一个类似 U-Net 的架构中使用一个编码器-解码器
- Swin-UNet 使用
ConvNets中使用的特征金字塔,然后在其上设置Transformer
- nnU-Net
- 直接使用纯
Transformer结构进行处理- Convolution-free medical image segmentation using transformers
- 首次引入了无卷积的分割模型,将扁平化的图像表示转发给 transformers
- 输出被重组为三维张量,与分割掩码对齐
- Convolution-free medical image segmentation using transformers
相关工作的缺点:
Transformer的优势没有得到充分的利用,几层Transformer不足以纠缠长期的依赖关系- 由于卷积表征包含精确的空间信息,这种信息在一组多幅图像(三维斑块的二维窗口)上会丢失
- 大多数方法将卷积网作为基础特征提取器,
Transformer只在顶部应用,以帮助从卷积网中提取的特征向量编码全局背景 - 只使用变换器,通过直接压平原始像素和应用一维预处理并不能提供足够丰富的特征集来建立模型
ConvNets是图像数据的首选工具,因为它们能捕获精确的局部特征,因此需要将它们纳入模型
nnFormer 的优势:
- 混合 stem
- 卷积和自关注交错使用,以充分发挥它们的优势
- Convolution:捕捉精确的局部信息。
- Self-Attention:捕捉长期的依赖关系
2. Method
2.1. Overview

nnFormer 的整体架构如上图所示,它保持了与 U-Net 类似的 U 型结构,主要由三部分组成,即 Encoder、Bottleneck 和 Decoder:
- Encoder 包括一个嵌入层、两个局部 transformer 块(每个块包含两个连续的层)和两个下采样层
- 对称的是,Decoder 分支包括两个 transformer 块,两个上采样层和最后一个用于进行掩码预测的补丁扩展层
- Bottleneck 部分包括一个下采样层、一个上采样层和三个全局 transformer 块,用于提供大的接收场以支持 Decoder
受 U-Net 的启发,本文在 Encoder 和 Decoder 的相应特征金字塔之间以对称的方式添加了跳过连接,这有助于恢复预测中的细粒度细节。然而,与通常使用求和或串联操作的非典型跳过连接不同,本文引入了跳过关注来弥补 Encoder 和 Decoder 之间的差距
Fig 2 图 a 中的 nnFormer 的详细结构如下图所示:
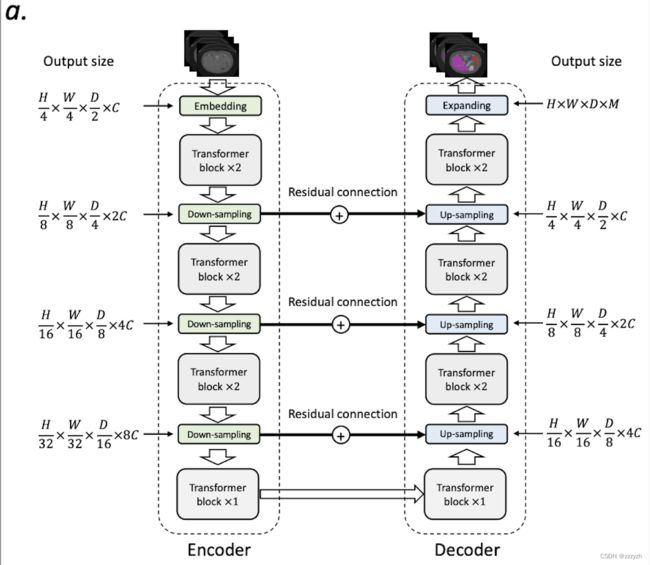
2.2. Encoder
nnFormer 的输入是一个三维补丁 X ∈ R H × W × D X \in R^{H \times W \times D} X∈RH×W×D(通常是从原始图像中随机裁剪的),参数含义:
- H , W , D H, W, D H,W,D 分别表示每个输入扫描的高度、宽度和深度
2.2.1. Components
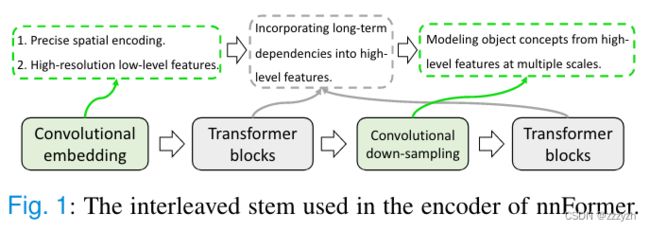
nnFormer 使用混合 stem,其中卷积和自我注意被交错使用,以充分发挥它们各自的优势
- 把一个轻量级的
Convolutional embedding layer放在Transformer block的前面- 这个嵌入层对精确的像素级空间信息进行编码,并提供低水平但高分辨率的三维特征
- 在嵌入块之后,
Transformer block和卷积下采样块交错在一起使用- 以充分融合不同尺度的高层次和分层物体概念的长期依赖关系,这有助于提高学习表征的泛化能力和稳健性
2.2.2. The embedding layer
Embedding block 将每个输入扫描 X X X 转化为高维张量 X e ∈ R H 4 × W 4 × D 2 × C X_e \in R^{\frac{H}{4} \times \frac{W}{4} \times \frac{D}{2} \times C} Xe∈R4H×4W×2D×C
参数含义:
- H 4 × W 4 × D 2 \frac{H}{4} \times \frac{W}{4} \times \frac{D}{2} 4H×4W×2D 代表补丁标记的数量
- C C C 代表序列长度(这些数字在不同的数据集上可能略有不同)
与 ViT 和 Swin Transformer 在嵌入块中使用大的卷积核来提取特征不同,本文发现应用小的卷积核的连续卷积层在初始阶段带来更多的好处:
- 应用连续的卷积层
- 在嵌入块中使用卷积层,因为它们对像素级的空间信息进行编码,比变换器中使用的补丁式位置编码更精确
- 小尺寸核
- 与大尺寸的内核相比,小的内核尺寸有助于降低计算的复杂性,同时提供同等大小的感受野

上图所示的 Embedding block 是一个四层的卷积结构(针对不同数据集参数上可能会有出入,具体参考 Fig 2 图 b)
- 核大小为 3
- 在每个卷积层之后(除了最后一个),附加一个
GELU激活函数和一个layer normalization层
Embedding block 主要用来将输入的影像转化为网络可以处理的特征。使用四层的卷积来处理输入的原因如下:
- 卷积网络可以更好的保留更加精确的位置信息
- 卷积操作可以提供高分辨率的底层特征,这是后面应用
Transformer block的基础
2.2.3. Local Volume-based Multi-head Self-attention (LV-MSA)
nnFormer 在三维局部体积内计算 self-attention
假设 X L V ∈ R L × C X_{LV} \in R^{L \times C} XLV∈RL×C 代表 local transformer block 的输入
- 首先被重塑为 X ^ L V ∈ R N L V × N T × C \hat{X}_{LV} \in R^{N_{LV} \times N_T \times C} X^LV∈RNLV×NT×C
- N L V N_{LV} NLV 是预先定义的三维局部
- N T = S H × S W × S D N_T = S_H \times S_W \times S_D NT=SH×SW×SD 表示每个
volume中补丁标记的数量 - { S H , S W , S D } \{ S_H, S_W, S_D \} {SH,SW,SD} 代表局部
volume的大小
如下图所示:在每个区块中进行两个连续的 transformer 层,其中第二层可以被视为第一层的移位版本(即 SLV-MSA)

计算过程可以总结为以下几点:

l l l 代表层的索引, M L P MLP MLP 代表多层感知机
LV-MSA 在一个 h × w × d h \times w \times d h×w×d 的 patches 体积上的计算复杂度为:
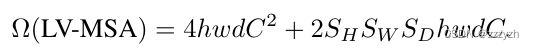
SLV-MSA 将 LV-MSA 中使用的三维局部体积置换为 ( ⌊ S H 2 ⌋ , ⌊ S W 2 ⌋ , ⌊ S D 2 ⌋ ) (\lfloor \frac{S_H}{2} \rfloor, \lfloor \frac{S_W}{2} \rfloor, \lfloor \frac{S_D}{2} \rfloor) (⌊2SH⌋,⌊2SW⌋,⌊2SD⌋),以引入不同局部体积之间的更多相互作用
在实践中,SLV-MSA 的计算复杂度与 LV-MSA 相似
相较于传统的 voxel 和 voxel 之间计算 self-attention 的方式,LV-MSA 可以大大地降低计算的复杂度,这些降低的复杂度主要集中在网络早期的计算过程中,伴随着特征空间维度的下降 ( H , W , D ) (H, W, D) (H,W,D) 以及通道输入 ( C ) (C) (C) 的增多,其实这种优势就不明显了
每个三维局部体中 query-key-value (QKV) attention 可以通过以下公式计算:

参数含义:
- Q , K , V ∈ R N T × d k Q, K, V \in R^{N_T \times d_k} Q,K,V∈RNT×dk 表示 query,key 和 value 的矩阵
- B ∈ R N T B \in R^{N_T} B∈RNT 是相对位置编码
2.2.4. The down-sampling layer
卷积下采样产生了层次化的表示,有助于在多个尺度上对物体概念进行建模
进行下采样的原因:
- 多次下采样可以建立多尺度的特征金字塔结构
- 下采样可以大大降低 GPU 显存的消耗

在大多数情况下,下采样层涉及到一个跨度卷积操作,其中跨度在所有维度上都被设置为 2。然而,在实践中,关于特定维度的步长可以设置为 1,因为在这个维度上,切片的数量是有限的,过度下采样(即使用大的下采样步长)可能是有害的
2.3. Bottleneck
将二维 multi-head self-attention 机制扩展到三维版本,如下图所示:
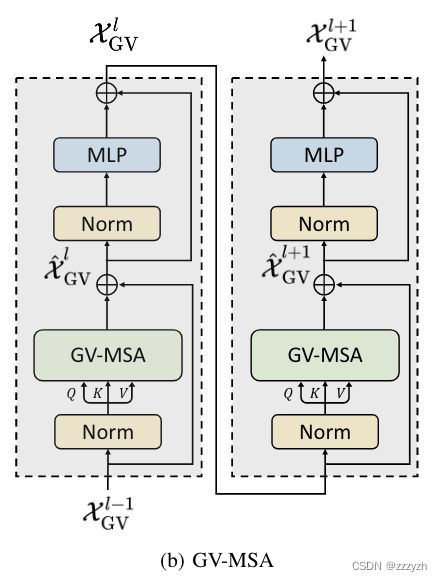
其计算复杂性可以表述为:
![]()
当 { h , w , d } \{ h, w, d \} {h,w,d} 相比 { S H , S W , S D } \{ S_H, S_W, S_D \} {SH,SW,SD} 较大时,GV-MSA 需要更多的计算资源
在 Bottleneck 中, { h , w , d } \{ h, w, d \} {h,w,d} 在经过几个下采样层后已经变得小得多,使得它们的乘积,即 h w d hwd hwd, ,具有与 S H S W S D S_H S_W S_D SHSWSD 相似的大小,这就为应用 GV-MSA 创造了条件
与 LV-MSA 相比,GV-MSA 能够提供更大的接收场,而大的接收场已经被证明在不同的应用中是有益的
本文在 Bottleneck 处使用了三个全局转换块(即六个 GV-MSA 层)来为解码器提供足够的接收场
2.4. Decoder
Decoder 中的两个转换块的结构与编码器中的转换块是高度对称的
本文采用分层去卷积将低分辨率的特征图向上采样为高分辨率的特征图,而这些特征图又通过 Skip Attention 与来自编码器的表示合并,以捕捉语义和细粒度的信息
与上采样区块类似,最后一个补丁扩展区块也采取去卷积操作来产生最终的掩码预测
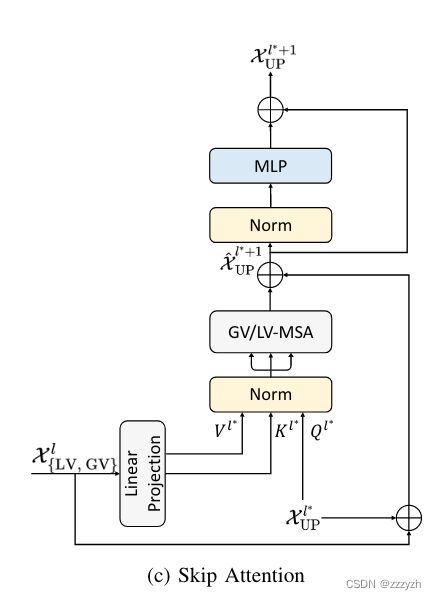
2.4.1. Skip Attention
编码器的第 l l l 个 Transformer block 的输出,即 X { L V , G V } l X^l_{\{ LV,GV \}} X{LV,GV}l,经过线性投影(即单层神经网络)后,被转换并分割成一个 key 矩阵 K l ∗ K^{l^∗} Kl∗ 和一个 value 矩阵 V l ∗ V^{l^∗} Vl∗:

L P LP LP 代表线性投影
X U P l ∗ X^{l^∗}_{UP} XUPl∗ 即 Decoder 的第 l ∗ l^∗ l∗ 层上采样后的输出特征图,被视为 query Q l ∗ Q^{l^∗} Ql∗
然后,可以在 Decoder 中对 Q l ∗ , K l ∗ , V l ∗ Q^{l^∗}, K^{l^∗}, V^{l^∗} Ql∗,Kl∗,Vl∗ 进行 LV/GV-MSA,即:

具体结构图如下所示:
3. Experiment
3.1. Implementation details
3.1.1. Learning rate
- 初始学习率被设定为 0.01
- 默认的优化器是
SGD - 动量设置为 0.99
- 权重衰减被设置为 3e-5
- 计算
cross entropy loss和dice loss
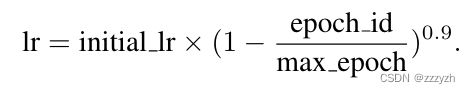
3.1.2. Pre-processing and augmentation strategies
所有图像将首先被重新取样到相同的目标间距
在训练过程中,旋转、缩放、高斯噪声、高斯模糊、亮度和对比度调整、模拟低分辨率、伽马增强和镜像等增强措施按给定顺序应用
3.1.3. Deep supervision
Decoder 中每个阶段的输出被传递到最后的扩展块,在那里将应用 cross entropy loss 和 dice loss
考虑一个典型阶段的预测,本文对 ground truth 分割掩码进行下采样,以匹配预测的分辨率。因此,最终的训练目标函数是三个分辨率下所有损失的总和
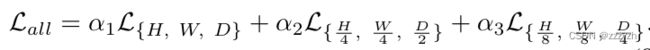
α { 1 , 2 , 3 } \alpha \{ 1, 2, 3 \} α{1,2,3} 表示不同分辨率下损失的大小系数,在实践中, α { 1 , 2 , 3 } \alpha \{ 1, 2, 3 \} α{1,2,3} 随着分辨率的降低而减半,导致 α 2 = α 1 2 , α 3 = α 1 4 \alpha_2 = \frac{\alpha_1}{2}, \ \ \alpha_3 = \frac{\alpha_1}{4} α2=2α1, α3=4α1。最后,所有的权重系数都归一化为 1
3.2. Ablation study
- 预训练十分有必要
- nnFormer 使用的是自然图像上预训练的模型,如果使用医疗影像的预训练模型,效果应该还可以更好
- 最开始的卷积结构很有用
- 说明了目前基于局部的处理方式在图像处理方面值得借鉴
- Transformer blocks 并不一定是越多越好
- 这个特点在医疗影像分割任务上尤其显著,因为分割的任务的数据量比较小,所以一个更加简单的网络结构或者加入一定程度的预训练是有必要的
总结
可以说,nnFormer 是基于 Swin Transformer 和 nnUNet 的经验结合产生的具有高性能的模型,但是在技术上的创新并不多
但同时,这也为后来的工作提供了思考的方向:将 U-Net 结构的思维引入 Transformer 以减少计算量,或是将 Transformer 的思维引入 U-Net 结构以实现长距离关系的捕捉