kaggle 泰坦尼克事件——随机森林算法实现
泰坦尼克事件——随机森林算法实现
- 前言
- 实现步骤
-
- 1.引入库
- 2.加载数据集
- 3.具体步骤
- 4.数据清洗
- 5.进行特征构建
- 6.构建新的字段,基于scikit-learn中的LabelEncoder()
- 7.特征选择(根据实际情况进行选择,选择不唯一)
- 8.获取训练集和测试集
- 9.随机森林算法的实现
- 10.对特征进行训练
- 11.在test上进行预测
- 12.在test.csv上进行预测
- 总结
前言
泰坦尼克号问题之背景
- 那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
- 训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
- logistic regression(逻辑回归)处理
实现步骤
1.引入库
#加载必要的库
%matplotlib inline
import sys
import pandas as pd
import numpy as np
import sklearn
import random
import time
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import ensemble #随机森林
from sklearn.preprocessing import LabelEncoder #编码转换
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
2.加载数据集
data_raw = pd.read_csv('train.csv')
data_val = pd.read_csv('test.csv')
3.具体步骤
data_raw.head() #显示部分数据 默认五条

data_val.head()
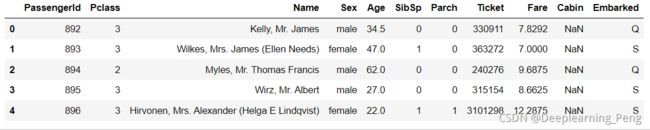
data_raw.info() #表中的详细信息

#列名称转换为小写,方便操作
data_raw.columns = data_raw.columns.str.lower()
data_val.columns = data_val.columns.str.lower()
data_raw.head()

#绘制图形
sns.countplot(data_raw['survived'])

#合并两个数据集,进行数据清洗
data_all = [data_raw,data_val]
4.数据清洗
data_raw.isnull().sum() #统计每个特征有多少为空值

data_val.isnull().sum()
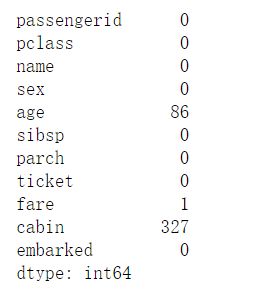
#对原数据进行描述
data_raw.describe(include='all')

#对原始数据进行清洗
for dataset in data_all:
#补足缺省值
dataset['age'].fillna(dataset['age'].median(),inplace=True) #inplace是指指在原始数据集进行操作
dataset['fare'].fillna(dataset['fare'].median(),inplace=True)
dataset['embarked'].fillna(dataset['embarked'].mode()[0],inplace=True)
#删除一些字段
drop_columns = ['cabin','passengerid','ticket']
data_raw.drop(drop_columns, axis=1, inplace = True) #axis是指在列上操作,inplace是指指在原始数据集进行操作
data_val.drop(drop_columns, axis=1, inplace = True)
data_val.isnull().sum()

5.进行特征构建
for dataset in data_all:
#构建新的字段:
#1)family_size 家庭规模 sibsp+parch
dataset['family_size'] = dataset['sibsp']+dataset['parch'] + 1 #加上本人
#2) 单身 single , 0:非单身,1:单身
dataset['single'] = 1
dataset['single'].loc[dataset['family_size']>1] = 0
#3) 身份 title
dataset['title'] = dataset['name'].str.split(', ',expand=True)[1].str.split('.',expand=True)[0]
# dataset['title'] = dataset['name'].apply(lambda x : x.split(,)[1]).apply(lambda x : x.split('.')[0])
#4) 票价 fare_bin
dataset['fare_bin'] = pd.qcut(dataset['fare'],4) #根据票价分为4组,每组元素个数一致
#5) 年龄
dataset['age_bin'] = pd.cut(dataset['age'].astype(int),5)#根据年龄分为5组,每组元素个数不一致
dataset.head()

#根据title统计人数
data_raw['title'].value_counts()
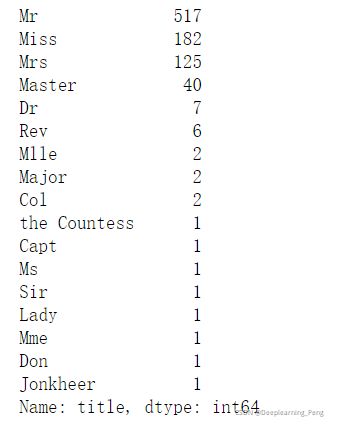
#人数少于十人的归为一类:others
title_names = (data_raw['title'].value_counts() < 10)
data_raw['title'] = data_raw['title'].apply(lambda x : 'others' if title_names[x] else x)
data_raw['title'].value_counts()

#按获救的人进行分组
data_raw['survived'].groupby(data_raw['title']).mean()
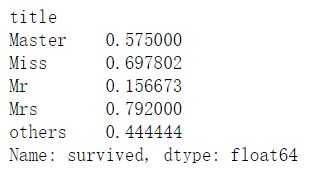
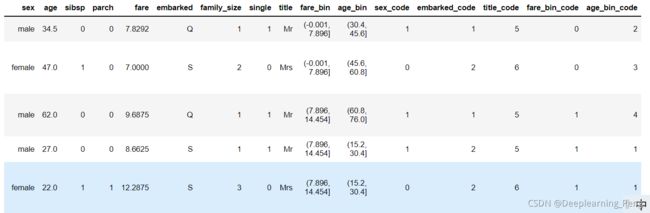
6.构建新的字段,基于scikit-learn中的LabelEncoder()
data_raw.head()

label = LabelEncoder()
for dataset in data_all:
#构建新字段
#1) sex_code
dataset['sex_code'] = label.fit_transform(dataset['sex'])
#2) embarked_code
dataset['embarked_code'] = label.fit_transform(dataset['embarked'])
#3) title_code
dataset['title_code'] = label.fit_transform(dataset['title'])
#4) fare_bin_code
dataset['fare_bin_code'] = label.fit_transform(dataset['fare_bin'])
#5) age_bin_code
dataset['age_bin_code'] = label.fit_transform(dataset['age_bin'])
7.特征选择(根据实际情况进行选择,选择不唯一)
target = ['survived']
data_columns_three = ['sex_code', 'pclass', 'embarked_code', 'title_code', 'family_size', 'age_bin_code', 'fare_bin_code']
columns_three = target + data_columns_three
#通过Pandas中的get_dummies() 进行编码
data_one_dummy = pd.get_dummies(data_raw[data_columns_one])
data_one_dummy_list = data_one_dummy.columns.tolist()
data_one_dummy_list

8.获取训练集和测试集
X_train_three,X_test_three,y_train_three,y_test_three = model_selection.train_test_split(data_raw[data_columns_three],data_raw[target],random_state = 0)
X_train_one.shape

X_test_one.shape
![]()
9.随机森林算法的实现
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(max_features='auto',#自动选择特征
random_state=1,
n_jobs=-1)
param_gird = {#会挑选出最好的参数
'criterion' : ['gini', 'entropy'],
'min_samples_leaf' : [1, 5, 10],
'min_samples_split' : [2, 4, 10, 12, 16],
'n_estimators' : [50, 100, 400, 700, 1000]
}
gs = GridSearchCV(estimator=rf,
param_grid=param_gird,
scoring= 'accuracy',
cv=3,
n_jobs=-1)
10.对特征进行训练
gs = gs.fit(X_train_three,y_train_three)
#创建一个对象
rf2 = RandomForestClassifier(criterion='entropy',
min_samples_leaf=5,
min_samples_split=12,
n_estimators=50,
random_state=1,
n_jobs=-1)
rf2.fit(X_train_three,y_train_three)
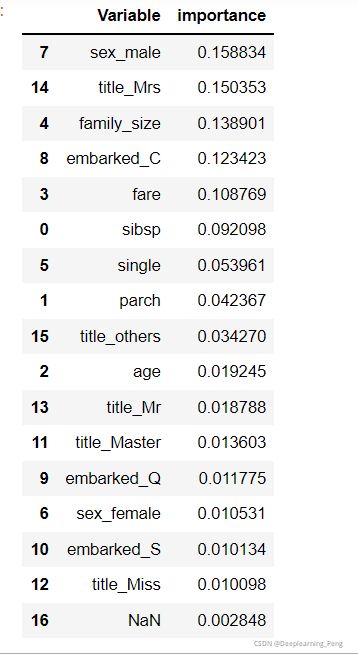
# 根据特征的重要性排序
pd.concat((pd.DataFrame(X_train_three.iloc[:, 1:].columns, columns=['Variable']),
pd.DataFrame(rf2.feature_importances_, columns=['importance'])),
axis=1).sort_values(by='importance', ascending=False)
11.在test上进行预测
pred = rf2.predict(X_test_three)
pred_df = pd.DataFrame(pred,columns=['survived'])
pred_df.head()

12.在test.csv上进行预测
data_val_dummy = pd.get_dummies(data_val[data_columns_three])
data_val_dummy_list = data_val_dummy.columns.tolist()
data_val_dummy_list

pred_val = rf2.predict(data_val_dummy[[
'pclass',
'age',
'fare',
'family_size',
'single',
'sex_female',
'sex_male',
'embarked_C',
'embarked_Q',
'embarked_S',
'title_Col',
'title_Dona',
'title_Dr',
'title_Master',
'title_Miss',
'title_Mr',
'title_Mrs',]])
pred_val_df = pd.DataFrame(pred_val, columns=['survived'])
pred_val_df

总结
如果对相关函数使用不是特别了解,或者对代码有疑问,可以私信我,不足之处请多多指导。