2019 Domain-Specific Batch Normalization for Unsupervised Domain Adaptation
论文地址:https://arxiv.org/pdf/1906.03950v1.pdf
代码地址:https://github.com/wgchang/DSBN
1 研究动机与研究思路
研究动机: 因为源域和目标域领域具有不同的特征,通过分离领域特定信息和领域不变信息可以获得更好的泛化性能。为了分离领域特定信息进行无监督的领域自适应,本文提出了一种新的基于特定域批归一化的无监督域适应框架DSBN,通过在卷积神经网络中专门设置批量归一化层来适应两个领域,同时允许它们共享所有其他模型参数。
研究思路: DSBN利用BN参数捕获领域特殊性信息,并利用该参数将领域特殊性数据转换为域不变表示。DSBN层由批归一化( Batch Normalization,BN )的两个分支组成,每个分支单独负责一个域(两个域在两个阶段都有单独的批归一化层)。
算法普遍适用于各种具有BN层的无监督域适应深度神经网络。
2 主要工作
本文的主要工作:
- 提出了一种新的基于DSBN的无监督领域自适应框架,它是一种适用于各种深度神经网络模型的域适应通用方法。
- 引入了一种包含伪标签估计和多任务分类的DSBN两阶段学习方法,该方法自然地集成到现有的无监督领域自适应方法中。
- 通过其直接的扩展提供了一种多源的无监督领域自适应的通用算法。
3 方法
3.1 主要框架
本文提出一个基于DSBN的无监督域适应的两阶段框架,首先在目标域中生成未标记数据的伪标注,然后使用伪标注学习一个完全监督的模型。具体来说,第一阶段使用无监督的域适应算法(例如MSTN [ 27 ]或CPUA [ 14 ] )来估计目标域中的示例的伪标签。第二阶段,利用源域和目标域的数据,在完全监督的情况下训练一个包含DSBN层的多任务分类网络,其中第一阶段生成的伪标注被分配给目标域数据。为了进一步提高准确率,迭代第二阶段训练并细化目标域中示例的标签。
3.2 准备工作
3.2.1 参数说明
X S \mathcal{X}_S XS表示有标记的源域, X T \mathcal{X}_T XT表示无标记的目标域,其中 n S n_S nS 和 n T n_T nT分别表示 X S \mathcal{X}_S XS和 X T \mathcal{X}_T XT的势。本文的目标是在完全监督的基础上,通过迁移从源域学习到的分类知识,对目标域中的实例进行分类。本节将详细讨论两种最新的方法来集成特定领域批归一化技术。
3.2.2 移动语义迁移网络(Moving Semantic Transfer Network)
MSTN [ 27 ]基于未标记目标域样本的伪标注,提出了语义匹配损失函数来跨域对齐相同类的质心。总损失函数 L \mathcal{L} L的形式定义为
L = L c l s ( X S ) + λ L d a ( X S , X T ) + λ L s m ( X S , X T ) \mathcal{L}=\mathcal{L}_{\mathrm{cls}}\left(\mathcal{X}_S\right)+\lambda \mathcal{L}_{\mathrm{da}}\left(\mathcal{X}_S, \mathcal{X}_T\right)+\lambda \mathcal{L}_{\mathrm{sm}}\left(\mathcal{X}_S, \mathcal{X}_T\right) L=Lcls(XS)+λLda(XS,XT)+λLsm(XS,XT)
分类损失 L c l s \mathcal{L}_{\mathrm{cls}} Lcls为源域数据集的交叉熵损失,领域对抗损失 L d a \mathcal{L}_{\mathrm{da}} Lda使得网络混淆了域成员。语义匹配损失 L s m ( X S , X T ) \mathcal{L}_{\mathrm{sm}}\left(\mathcal{X}_S, \mathcal{X}_T\right) Lsm(XS,XT)将相同类别的质心跨域对齐。需要注意的是,用伪标签来计算语义匹配损失。
直观地看,损失函数鼓励两个域具有相同的分布,特别是通过添加对抗和语义匹配损失项。因此,基于损失函数的学习网络可以应用于目标领域的实例。
3.2.3 类预测不确定性对齐(Class Prediction Uncertainty Alignment)
CPUA [ 14 ]是一种非常简单的方法,它只对齐域之间的类概率。CPUA解决了两个域中的类不平衡问题,并引入了一个类加权损失函数来利用类先验知识。
设 p S ( c ) = n S c / n S p_S(c)=n_S^c / n_S pS(c)=nSc/nS 是具有类标号 c c c的源域样本的分数, p ~ T ( c ) = n T c / n T \widetilde{p}_T(c)=n_T^c / n_T p T(c)=nTc/nT为目标样本中伪标记为 c c c的比例。 n T c n_T^c nTc 表示 { x ∈ X T ∣ y ~ ( x ) = c } \left\{x \in \mathcal{X}_T \mid \widetilde{y}(x)=c\right\} {x∈XT∣y (x)=c},的势,其中 y ~ ( x ) = argmax i ∈ C F ( x ) [ i ] \widetilde{y}(x)=\operatorname{argmax}_{i \in C} F(x)[i] y (x)=argmaxi∈CF(x)[i] .则每个域的类权重分别为:
w S ( x , y ) = max y ′ p S ( y ′ ) p S ( y ) w_S(x, y)=\frac{\max _{y^{\prime}} p_S\left(y^{\prime}\right)}{p_S(y)} wS(x,y)=pS(y)maxy′pS(y′)
和
w T ( x ) = max y ′ p ~ T ( y ′ ) p ~ T ( y ~ ( x ) ) w_T(x)=\frac{\max _{y^{\prime}} \widetilde{p}_T\left(y^{\prime}\right)}{\widetilde{p}_T(\widetilde{y}(x))} wT(x)=p T(y (x))maxy′p T(y′)
它们的总损失函数可以写为:
L = L cls ( X S ) + λ L d a ( X S , X T ) \mathcal{L}=\mathcal{L}_{\text {cls }}\left(\mathcal{X}_S\right)+\lambda \mathcal{L}_{\mathrm{da}}\left(\mathcal{X}_S, \mathcal{X}_T\right) L=Lcls (XS)+λLda(XS,XT)
where
L c l s ( X S ) = 1 n S ∑ ( x , y ) ∈ X S w S ( x , y ) ℓ ( F ( x ) , y ) , L d a ( X S , X T ) = 1 n S ∑ ( x , y ) ∈ X S w S ( x , y ) ℓ ( D ( F ( x ) ) , 1 ) , + 1 n T ∑ x ∈ X T w T ( x ) ℓ ( D ( F ( x ) ) , 0 ) . \begin{aligned} \mathcal{L}_{\mathrm{cls}}\left(\mathcal{X}_S\right) & =\frac{1}{n_S} \sum_{(x, y) \in \mathcal{X}_S} w_S(x, y) \ell(F(x), y), \\ \mathcal{L}_{\mathrm{da}}\left(\mathcal{X}_S, \mathcal{X}_T\right) & =\frac{1}{n_S} \sum_{(x, y) \in \mathcal{X}_S} w_S(x, y) \ell(D(F(x)), 1), \\ & +\frac{1}{n_T} \sum_{x \in \mathcal{X}_T} w_T(x) \ell(D(F(x)), 0) . \end{aligned} Lcls(XS)Lda(XS,XT)=nS1(x,y)∈XS∑wS(x,y)ℓ(F(x),y),=nS1(x,y)∈XS∑wS(x,y)ℓ(D(F(x)),1),+nT1x∈XT∑wT(x)ℓ(D(F(x)),0).
注意到 F ( ⋅ ) F(\cdot) F(⋅)一个分类网络, ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ(⋅,⋅)表示交叉熵损失, D ( ⋅ ) D(\cdot) D(⋅)是一个域判别器。
3.3 领域特定的批归一化
本部分对批归一化( Batch Normalization,BN )与DSBN进行比较,然后介绍了DSBN及其对多源域适应的扩展。
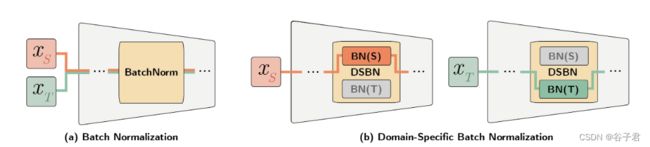
图1 BN与DSBN的区别。DSBN层由批归一化层中的两个分支组成,一个分支用于源域( S ),另一个分支用于目标域( T )。每个输入实例根据其领域选择其中一个分支。在具有DSBN层的域自适应网络中,除DSBN层外的所有参数在两个域中共享,有效地学习了两个域中共有的信息,同时通过DSBN层的域特定BN参数有效地捕获了域特定的属性。
3.3.1 批量归一化BN
BN是深度网络中广泛使用的训练技术。一个BN层在每一个通道维度的N个示例中白化激活(whitens activations),并使用仿射参数 γ \gamma γ和 β \beta β变换白化激活。
用 x ∈ R H × W × N \mathrm{x} \in \mathbb{R}^{H \times W \times N} x∈RH×W×N 表示每个通道的激活,BN表示为
B N ( x [ i , j , n ] ; γ , β ) = γ ⋅ x ^ [ i , j , n ] + β , \mathrm{BN}(\mathrm{x}[i, j, n] ; \gamma, \beta)=\gamma \cdot \hat{\mathrm{x}}[i, j, n]+\beta, BN(x[i,j,n];γ,β)=γ⋅x^[i,j,n]+β,
其中
x ^ [ i , j , n ] = x [ i , j , n ] − μ σ 2 + ϵ . \hat{\mathbf{x}}[i, j, n]=\frac{\mathrm{x}[i, j, n]-\mu}{\sqrt{\sigma^2+\epsilon}} . x^[i,j,n]=σ2+ϵx[i,j,n]−μ.
一个小批量内激活的均值和方差, μ \mu μ 和 σ \sigma σ,计算得到
μ = ∑ n ∑ i , j x [ i , j , n ] N ⋅ H ⋅ W , σ 2 = ∑ n ∑ i , j ( x [ i , j , n ] − μ ) 2 N ⋅ H ⋅ W . \begin{aligned} \mu & =\frac{\sum_n \sum_{i, j} \mathrm{x}[i, j, n]}{N \cdot H \cdot W}, \\ \sigma^2 & =\frac{\sum_n \sum_{i, j}(\mathrm{x}[i, j, n]-\mu)^2}{N \cdot H \cdot W} . \end{aligned} μσ2=N⋅H⋅W∑n∑i,jx[i,j,n],=N⋅H⋅W∑n∑i,j(x[i,j,n]−μ)2.
ϵ \epsilon ϵ 是一个小的常数以避免被零除。
在训练过程中,BN通过更新因子为 α \alpha α的指数移动平均来估计整个激活的均值和方差,记为 μ ˉ \bar{\mu} μˉ和 σ ˉ \bar{\sigma} σˉ。形式上,给定第 t th t^{\text {th }} tth 个小批量,其均值和方差为
μ ˉ t + 1 = ( 1 − α ) μ ˉ t + α μ t , ( σ ˉ t + 1 ) 2 = ( 1 − α ) ( σ ˉ t ) 2 + α ( σ t ) 2 . \begin{aligned} \bar{\mu}^{t+1} & =(1-\alpha) \bar{\mu}^t+\alpha \mu^t, \\ \left(\bar{\sigma}^{t+1}\right)^2 & =(1-\alpha)\left(\bar{\sigma}^t\right)^2+\alpha\left(\sigma^t\right)^2 . \end{aligned} μˉt+1(σˉt+1)2=(1−α)μˉt+αμt,=(1−α)(σˉt)2+α(σt)2.
在测试阶段,BN使用估计的均值和方差进行归一化输入激活。需要注意的是,如果域偏移显著,同时共享源域和目标域的均值和方差是不合适的。
3.3.2 特定领域批标准化DSBN
DSBN是利用为每个领域预留的多组BN [ 5 ]实现的。形式上,DSBN为每个域标签 d ∈ { S , T } d \in\{S, T\} d∈{S,T}分配特定于域的仿射参数 γ d \gamma_d γd和 β d \beta_d βd。令 x d ∈ R H × W × N \mathbf{x}_d \in \mathbb{R}^{H \times W \times N} xd∈RH×W×N 表示每个通道的激活属于一个域标签d,则DSBN层可以写为
DSBN d ( x d [ i , j , n ] ; γ d , β d ) = γ d ⋅ x ^ d [ i , j , n ] + β d \operatorname{DSBN}_d\left(\mathbf{x}_d[i, j, n] ; \gamma_d, \beta_d\right)=\gamma_d \cdot \hat{\mathbf{x}}_d[i, j, n]+\beta_d DSBNd(xd[i,j,n];γd,βd)=γd⋅x^d[i,j,n]+βd
其中
x ^ d [ i , j , n ] = x d [ i , j , n ] − μ d σ d 2 + ϵ \hat{\mathbf{x}}_d[i, j, n]=\frac{\mathbf{x}_d[i, j, n]-\mu_d}{\sqrt{\sigma_d^2+\epsilon}} x^d[i,j,n]=σd2+ϵxd[i,j,n]−μd
μ d = ∑ n ∑ i , j x d [ i , j , n ] N ⋅ H ⋅ W σ d 2 = ∑ n ∑ i , j ( x d [ i , j , n ] − μ d ) 2 N ⋅ H ⋅ W \begin{aligned} \mu_d & =\frac{\sum_n \sum_{i, j} \mathbf{x}_d[i, j, n]}{N \cdot H \cdot W} \\ \sigma_d^2 & =\frac{\sum_n \sum_{i, j}\left(\mathbf{x}_d[i, j, n]-\mu_d\right)^2}{N \cdot H \cdot W} \end{aligned} μdσd2=N⋅H⋅W∑n∑i,jxd[i,j,n]=N⋅H⋅W∑n∑i,j(xd[i,j,n]−μd)2
在训练过程中,DSBN通过更新因子为 α \alpha α的指数移动平均法分别估计每个域的激活均值和方差
μ ˉ d t + 1 = ( 1 − α ) μ ˉ d t + α μ d t ( σ ˉ d t + 1 ) 2 = ( 1 − α ) ( σ ˉ d t ) 2 + α ( σ d t ) 2 \begin{aligned} \bar{\mu}_d^{t+1} & =(1-\alpha) \bar{\mu}_d^t+\alpha \mu_d^t \\ \left(\bar{\sigma}_d^{t+1}\right)^2 & =(1-\alpha)\left(\bar{\sigma}_d^t\right)^2+\alpha\left(\sigma_d^t\right)^2 \end{aligned} μˉdt+1(σˉdt+1)2=(1−α)μˉdt+αμdt=(1−α)(σˉdt)2+α(σdt)2
每个域的估计均值和方差用于DSBN测试阶段对应域的算例。
本文期望DSBN通过分别估计每个域的批统计量和学习仿射参数来捕获特定域的信息。本认为,DSBN可以让网络更好地学习领域不变的特征,因为通过从给定领域捕获的统计信息和学习的参数,可以有效地去除网络中的特定领域信息。
DSBN容易嵌入现有的深度神经网络进行无监督域适应。现有的分类网络 F ( ⋅ ) F(\cdot) F(⋅) 可以通过将所有BN层替换为DSBN层并使用带有领域标签的数据训练整个网络来转换为领域特定的网络。域特定网络用 F d ( ⋅ ) F_d(\cdot) Fd(⋅)表示,它依赖于域变量 d ∈ { S , T } d \in\{S, T\} d∈{S,T},专门化于源域或目标域。
3.3.3 多源域适应扩展
DSBN通过在其中添加更多的域分支,很容易扩展为多源无监督域适应。适用于多源域适应的损失函数可以简单地由所有源域的损失之和定义,如下:
L = 1 ∣ D S ∣ ∑ i ∣ D S ∣ ( L cls ( X S i ) + L align ( X S i , X T ) ) \mathcal{L}=\frac{1}{\left|\mathcal{D}_S\right|} \sum_i^{\left|\mathcal{D}_S\right|}\left(\mathcal{L}_{\text {cls }}\left(\mathcal{X}_{S_i}\right)+\mathcal{L}_{\text {align }}\left(\mathcal{X}_{S_i}, \mathcal{X}_T\right)\right) L=∣DS∣1i∑∣DS∣(Lcls (XSi)+Lalign (XSi,XT))
其中, D S = { X S 1 , X S 2 , … } \mathcal{D}_S=\left\{\mathcal{X}_{S_1}, \mathcal{X}_{S_2}, \ldots\right\} DS={XS1,XS2,…} 是源域集合, L align \mathcal{L}_{\text {align }} Lalign 可以是源域和目标域对齐的任意一种损失。其余训练过程与单源域适应情况相同。
3.4 基于DSBN的领域自适应
DSBN是一种通用的无监督域自适应技术,通过批量归一化可以集成到基于深度神经网络的各种算法中。本文的框架分两个阶段训练用于无监督域适应的深度网络。在第一阶段,本文训练一个现有的无监督域适应网络来生成目标域数据的初始伪标注。第二阶段以源域中的背景真值和目标域中的伪标注作为监督学习两个域的最终模型,其中目标域中的伪标注在训练过程中被逐级细化。
两个阶段的网络都加入了DSBN层,更有效地学习领域不变表示,从而更好地适应目标域。为了进一步提高准确率,本文可以进行第二阶段训练的额外迭代,其中伪标注使用前一次迭代中的结果进行更新。
3.4.1 阶段1:训练初始伪标签
本文选择了两种最先进的模型作为初始伪标签生成器:MSTN [ 27 ]和CPUA [ 14 ]。用DSBNs替换它们的BN层,使它们能更有效地学习域不变表示。然后通过网络的原始损失和学习策略进行训练。一个训练好的初始伪标签生成器记为 F T 1 F_T^1 FT1。
3.4.2 第二阶段:带伪标签的自训练

图2 第二阶段训练概述。为了对目标域样本使用中间伪标签,使用第一阶段训练的网络 F T 1 ( x ) F_T^1(x) FT1(x)作为第二阶段的伪标签。在此阶段,网络仅在两个域中使用分类损失进行训练。
在第二阶段,本文利用来自两个域的数据和它们的标签,利用丰富的域不变表示,在完全监督的情况下训练两个域的最终模型。网络使用两个分类损失进行训练,一个用于具有真实标签的源域,另一个用于具有伪标注的目标域,得到的网络用 F d 2 F_d^2 Fd2表示,其中 d ∈ { S , T } d \in\{S, T\} d∈{S,T}。总损失函数由来自两个域的两个损失项的简单求和给出如下:
L = L cls ( X S ) + L cls pseudo ( X T ) \mathcal{L}=\mathcal{L}_{\text {cls }}\left(\mathcal{X}_S\right)+\mathcal{L}_{\text {cls }}^{\text {pseudo }}\left(\mathcal{X}_T\right) L=Lcls (XS)+Lcls pseudo (XT)
其中
L cls ( X S ) = ∑ ( x , y ) ∈ X S ℓ ( F S 2 ( x ) , y ) , L cls pseudo ( X T ) = ∑ x ∈ X T ℓ ( F T 2 ( x ) , y ′ ) \begin{aligned} \mathcal{L}_{\text {cls }}\left(\mathcal{X}_S\right) & =\sum_{(x, y) \in \mathcal{X}_S} \ell\left(F_S^2(x), y\right), \\ \mathcal{L}_{\text {cls }}^{\text {pseudo }}\left(\mathcal{X}_T\right) & =\sum_{x \in \mathcal{X}_T} \ell\left(F_T^2(x), y^{\prime}\right) \end{aligned} Lcls (XS)Lcls pseudo (XT)=(x,y)∈XS∑ℓ(FS2(x),y),=x∈XT∑ℓ(FT2(x),y′)
式中: ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ(⋅,⋅) 为交叉熵损失, y ′ y^{\prime} y′ 表示分配给目标域样本 x ∈ X T x \in \mathcal{X}_T x∈XT的伪标签。伪标签 y ′ y^{\prime} y′由F1T初始化,并由 F T 2 F_T^2 FT2逐步精化:
y ′ = argmax c ∈ C { ( 1 − λ ) F T 1 ( x ) [ c ] + λ F T 2 ( x ) [ c ] } , y^{\prime}=\underset{c \in C}{\operatorname{argmax}}\left\{(1-\lambda) F_T^1(x)[c]+\lambda F_T^2(x)[c]\right\}, y′=c∈Cargmax{(1−λ)FT1(x)[c]+λFT2(x)[c]},
其中 F T i ( x ) [ c ] F_T^i(x)[c] FTi(x)[c]表示由 F T i F_T^i FTi给出的类别 c c c的预测分数, λ \lambda λ是一个在训练过程中从0到1逐渐变化的权重因子。由于 F T 2 F_T^2 FT2在训练的同时参与伪标签的生成,因此该方法可以看作是一种self-supervised训练。在训练的早期阶段,由于 F T 2 F_T^2 FT2的预测可能是不可靠的,所以本文对 F T 1 F_T^1 FT1给出的初始伪标注赋予了更多的权重。然后权重λ逐渐增大,在训练的最后阶段,伪标签完全依赖于 F T 2 F_T^2 FT2。本文遵循[ 3 ]来抑制潜在的噪声伪标注;适应因子 λ \lambda λ按 λ = 2 1 + exp ( − γ ⋅ p ) − 1 \lambda=\frac{2}{1+\exp (-\gamma \cdot p)}-1 λ=1+exp(−γ⋅p)2−1递增, γ = 10 \gamma=10 γ=10.。
由于 F T 2 F_T^2 FT2利用 F T 1 F_T^1 FT1给出的合理初始伪标注进行训练,而 F T 1 F_T^1 FT1仅依靠弱信息进行域对齐,因此 F T 2 F_T^2 FT2比 F T 1 F_T^1 FT1总体上能更准确地识别目标域图像。为了进一步提高初始伪标注的精度,利用 F T 2 F_T^2 FT2估计更精确的初始伪标注。因此,本文迭代地执行第二阶段过程,其中初始伪标注使用前一次迭代中模型的预测结果进行更新。本文实证地观察到这种迭代方法对于提高目标域的分类精度是有效的。
4 实验
4.1 实验设置
4.1.1 数据集
使用三个数据集进行实验:VisDA-C [ 16 ],Office-31 [ 17 ]和Office - Home [ 26 ]。
- VisDA - C是面向2017年视觉域适应挑战赛的大规模基准数据集。它由合成和真实两个域组成,从MS - COCO [ 8 ]数据集中获取了12个常见对象类的152 409张合成图像和55 400张真实图像。
- Office - 31是域适应的标准基准,它由31个类别的3个不同域组成:2817张图像的Amazon ( A )、795张图像的Webcam ( W )和498张图像的DSLR ( D )。
- Office-Home [ 26 ]有4个域:Art ( Ar ),2 427张图像;剪纸艺术( Cl ),4 365张图像;Product ( Pr ),4 439张图像;Real-World ( Rw ),4 357张图像。每个领域包含65类常见日常用品。
4.1.2 实现细节
使用ResNet - 101作为VisDA - C数据集的主干网络,使用ResNet - 50作为Office - 31和Office - Home数据集的主干网络。所有网络都有BN层,并在ImageNet上进行预训练。为了比较BN层和DSBN层的截然不同,所有实验都为每个域构建了小批量并分别forward。批次大小设置为40。
采用Adam优化器, β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9, \beta_2=0.999 β1=0.9,β2=0.999。设定阶段1和阶段2的初始学习率 η 0 = 1.0 × 1 0 − 4 \eta_0=1.0 \times 10^{-4} η0=1.0×10−4 和 5.0 × 1 0 − 5 5.0 \times 10^{-5} 5.0×10−5。如文献[ 3 ]所述,学习率由公式 η p = η 0 ( 1 + α p ) β \eta_p=\frac{\eta_0}{(1+\alpha p)^\beta} ηp=(1+αp)βη0调整,其中 α = 10 \alpha=10 α=10, β = 0.75 \beta=0.75 β=0.75, p p p表示从0到1线性变化的训练进度。优化器的最大迭代次数设置为50000次。
4.2 结果
在标准的基准数据集上展示了基于单源域和多源域适应的实验结果。
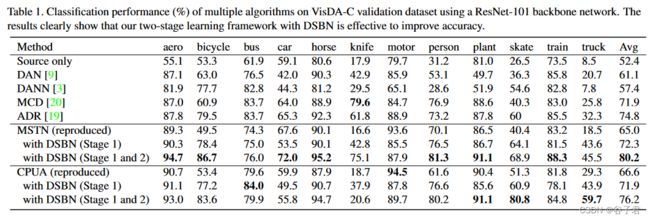
VisDA - C表1量化了MSTN和CPUA作为初始伪标签生成器的方法的性能,并与VisDA - C数据集上的最新记录进行了比较。表中’ DSBN ( Stage 1 ) ‘表示我们用DSBNs替换BN层并进行第一阶段训练,’ DSBN (第一阶段和第二阶段) '表示我们同时进行第一阶段和第二阶段训练。我们提出的方法通过将DSBNs应用到基线模型中,显著且持续地提高了准确率,并在与MSTN结合时达到了最先进的性能[ 27 ]。模型可靠地识别了刀、人、滑冰和卡车等hard classes。

Office - 31表2给出了在Office - 31数据集上使用MSTN和CPUA的总体评分。在两个阶段训练的DSBN模型都取得了最好的性能,并且始终优于两个基线模型。表2还表明,框架可以成功应用于当前的域适应算法,并极大地提升了性能。
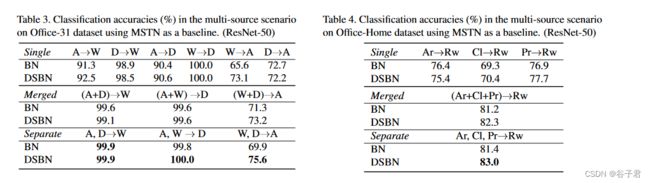
多源域表3和表4分别给出了Office - 31和Office - Home数据集上的多源域适配结果。为了比较多源与单源域适应,我们将单源结果报告在表的顶部作为" Single “,并附加两个不同的多源场景:” Merged “和” Separation “。” Merged “是指来自多个源域的数据被合并并构建一个新的更大的源域数据集,而” Separation "则表示每个源域被单独考虑。在单独的情况下,网络中总共有|DS| +1个域和相同数量的DSBN分支。虽然当目标任务容易时,BN和DSBN之间存在边际性能增益,但模型在所有设置下都一致优于BN模型。特别地,对于表3中任务’A’的hard域适应,源域分离的DSBN明显优于合并的情况。这一结果意味着DSBN在多源域适应任务中也具有优势。不存在DSBN的情况下,单独情形并不总是优于合并情形。
4.3 分析
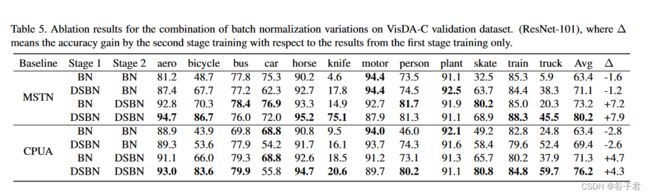
消融研究进行消融实验,以分析DSBN相对BN的效果。表5汇总了以MSTN和CPUA为基线架构在VisDA - C数据集上的消融结果,其中表中最后一列给出了第二阶段训练相对于第一阶段训练结果的精度增益。我们测试了几种不同训练程序的组合进行两阶段训练。这一结果直接表明,DSBN在两个训练过程中都起到了至关重要的作用。另一个重要的方面是,DSBN的第二阶段训练额外提高了成绩,但第二阶段的普通BN没有帮助。这意味着在训练阶段分离领域特定信息有助于得到可靠的伪标注。值得注意的是,特别是对于hard classes,这样的倾向更加明显。

特征可视化图4是在VisDA - C数据集上,以MSTN为基线,可视化BN (左)和DSBN (右)的实例嵌入。我们观察到,通过集成DSBN,同一类别中两个域的示例更好地对齐,这意味着DSBN是学习域不变表示的有效方法。

迭代学习采用第一阶段得到的网络作为第二阶段的伪标签,第二阶段学习到的网络比伪标签更强。因此,通过迭代地应用第二阶段学习过程来获得进一步的性能提升,其中当前迭代中的伪标注由上一阶段的结果给出。为了验证这个想法,我们使用MSTN作为基线算法在VisDA - C数据集上评估每次迭代中的分类精度。如表6所示,第二阶段的迭代学习随着迭代的进行精度逐渐提高。
5 结论
我们提出了用于无监督域适应的域特定批标准化。所提出的方法具有独立的批标准化层分支,每个域一个,同时跨域共享所有其他参数。这种思想普遍适用于具有批量归一化层的深度神经网络。将该方法与两阶段训练策略应用于最近的两种无监督域适应算法MSTN和CPUA,并在标准的基准数据集上展示了出色的性能。