文献阅读:AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization
- AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization
- 1. 内容简介
- 2. 原理 & 模型结构
- 3. 实验
- 1. 模型预训练语料 & 数据处理
- 2. 中文语料下的finetune实验
- 1. 分类任务中效果
- 2. 阅读理解任务中效果
- 3. sota模型对比
- 3. 英文语料下的finetune实验
- 1. 分类任务中效果
- 2. 阅读理解任务中效果
- 3. sota模型对比
- 4. 实例分析
- 5. 其他
- 1. encoder层是否学到不同粒度的信息
- 2. self-attention考察
- 4. 结论
- 5. 参考链接
1. 内容简介
这篇文献是字节跳动实验室李航博士在8月份发布的一篇文献,他的核心内容还是在bert的基础上的一个变体模型。
与Roberta,span bert等不同,这篇文章的主要关注点在于输入文本的颗粒度上。他的最核心观点认为:bert使用的分词颗粒度太细了,会丢失词的信息,因此通过调整输入序列的词颗粒度,可以优化模型的效果。
一种比较直接的思路就是使用词颗粒度的输入,但是单纯的使用词颗粒度的输入同样可能带来一定的问题,首先词表过大将会带来许多词汇的学习不充分以及unk问题,另一方面,分词本身也会由于分词本身的错误带来许多的问题。
因此,李航博士尝试同时采用词颗粒度以及字颗粒度的输入,来同时抓取两者的信息,从而提升模型的性能,在多项NLU任务中获得了SOTA的效果。
某种意义而言,这就很像是ensemble的方式,但是后者会大幅的增加参数量,减慢模型的运行效率。因此,李航博士共享了除了embedding层之外的所有参数,从而使得参数量的增加控制在了一个可以接受的范围内。
2. 原理 & 模型结构
如前所述,这篇文章的最核心思想就是在模型的信息输入层使用多颗粒度的信号。
给出论文中给出的整体的模型结构图如下:
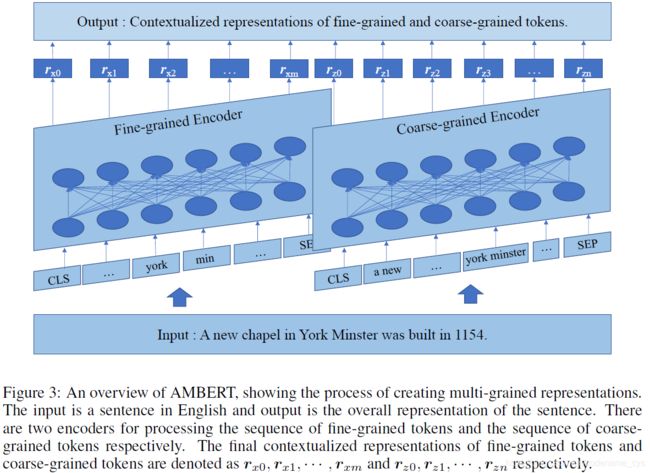
其核心在于输入将会被处理为两个不同颗粒度的序列,而后分别将其通过embedding层之后再通过encoder层,最后将两个encoder层的输出结果进行concat操作。
而模型的训练方式还是采用bert的MLM模型训练方式,即mask输入中的部分token,而后对其进行预测,不过论文中并没有明确地写明粗细颗粒度的输入文本中mask的部分是否一致。
另外,针对这一个模型的loss函数,则是简单的采用两个颗粒度下的loss相加的方式,其loss函数定义公式如下:
l o s s = − ∑ i = 1 m m i l ˙ o g ( p θ ( x i ∣ x ^ ) ) − ∑ i = 1 n n j l ˙ o g ( p θ ( z j ∣ z ^ ) ) loss = -\sum_{i=1}^{m}{m_i \dot log(p_{\theta}(x_i|\hat{x}))} - \sum_{i=1}^{n}{n_j \dot log(p_{\theta}(z_j|\hat{z}))} loss=−i=1∑mmil˙og(pθ(xi∣x^))−i=1∑nnjl˙og(pθ(zj∣z^))
其中, x x x和 z z z分别为粗细颗粒度下的输入词汇, m m m和 n n n表示mask,如果一个词被mask了,则 m i m_i mi( n j n_j nj)为1,反之为0。
3. 实验
下面,我们来具体看一下作者针对ambert进行的一些具体的实验。
1. 模型预训练语料 & 数据处理
首先,我们来看一下作者有关模型预训练使用的语料。
针对中文模型的预训练,作者使用了57G的文本,全部来源于头条数据;而针对英文模型的预训练,作者使用了47G的文本,基本和bert保持一致,不过,BookCorpus数据已经无法获取了,因此作者没有使用这部分数据。
有关中文的粗细颗粒度分词方式,细粒度的就是采用了字的分词,粗粒度则是采用了字条跳动内部的分词工具,但是两者共用同一份词表。
而有关英文的分词方式,细颗粒度的同样直接以单词为单位进行分词,粗颗粒度则是通过统计n-gram词频的方式获得。
模型训练则是使用V100的卡,mask的比例保持和bert一致,均为15%。
2. 中文语料下的finetune实验
该文献在分类以及阅读理解任务中测试了finetune之后的模型效果,并且在clue系列任务下比较了ambert与当前的sota模型直接的效果比较。
1. 分类任务中效果
finetune中文预训练模型之后在分类任务中的模型效果如下图所示:
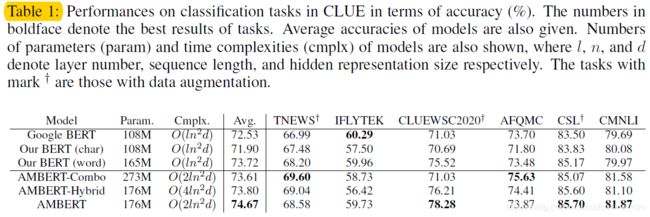
其中,AMBERT-Combo模型为放弃encoder部分的参数共享,直接暴力地使用两个encoder模型进行concat之后进行处理;而AMBERT-Hybrid则是在只是用一个encoder,在输入数据中直接concat粗细颗粒度的文本,这样,self-attention就会同时看到两部分的数据。
可以看到,在大部分的下游任务中,使用了粗细颗粒度信息的模型效果是优于单一的bert模型的。但是由于实质上ambert相当于是两个bert模型的ensemble,因此,不太好说他的效果提升是否真的来源于同时使用了不同颗粒度信息。
另一方面,针对AMBERT以及AMBERT-Combo模型,可以看到,AMBERT模型的效果在大部分任务中还是优于Combo模型的,所以可以证明:联合不同颗粒度信息确实可以提升模型的信息抽取能力,进而提升模型的效果。
2. 阅读理解任务中效果
同样的,我们在阅读理解任务中比较AMBERT与BERT之间的性能差异。
给出实验结果对比图如下:
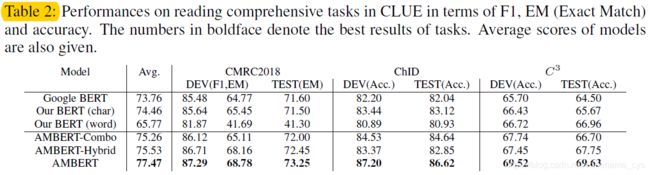
可以看到:
- 在阅读理解任务当中,AMBERT全面碾压了BERT模型。
3. sota模型对比
最后,我们考察以下除了bert之外当前的一些sota模型与AMBERT模型的性能比较。
给出实验结果图如下:
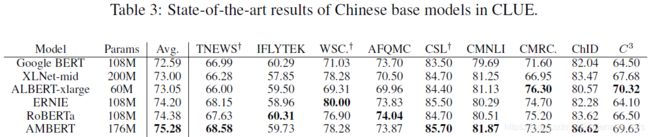
可以看到:
- 在大多数实验中,AMBERT都有着较好的性能表达。
3. 英文语料下的finetune实验
同样的,我们对英文的AMBERT模型效果进行考察。
1. 分类任务中效果
同样的,给出英文AMBERT模型在分类任务下的实验结果图如下:
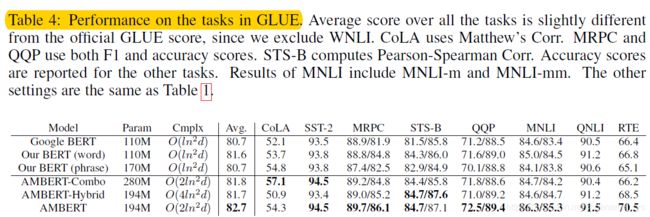
可以看到:
- 与中文预训练模型的结果相一致,AMBERT的效果全面超过BERT模型,仅在少数任务中劣于AMBERT-Combo模型。
2. 阅读理解任务中效果
我们直接给出英文阅读理解任务中的实验结果图下:

可以看到:
- 上述分类问题的结论同样适用于英文的阅读理解任务。
3. sota模型对比
最后,同样的,与中文模型的考察方式相一致,我们考察一下当前各个sota模型的效果与AMBERT的性能比较。
给出实验结果图如下:
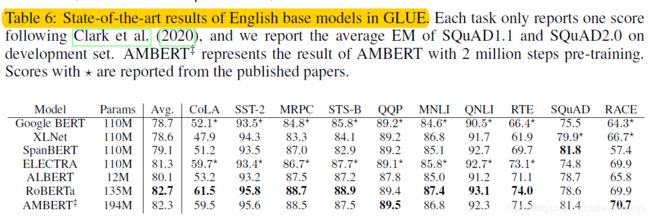
但是,我们发现,在英文任务当中,当前最优的模型依然是ROBERTA模型,AMBERT仅在RACE任务当中获得了sota的结果。
作者尝试对这一现象进行了解释,他认为:英文任务中性能不佳的原因在于分词结果中英文的“词汇”比例占比太少,仅占13.7%,且可能存在分词不佳的情况,而中文任务中两者占比差不多是1:1的,因此导致英文的粗颗粒度模型并没有贡献应有的作用,反而拖累了模型效果。
4. 实例分析
除了上述的指标分析,作者还给出了一些具体的实例来说明AMBERT较之单一颗粒度模型的优点,给出实例如下:
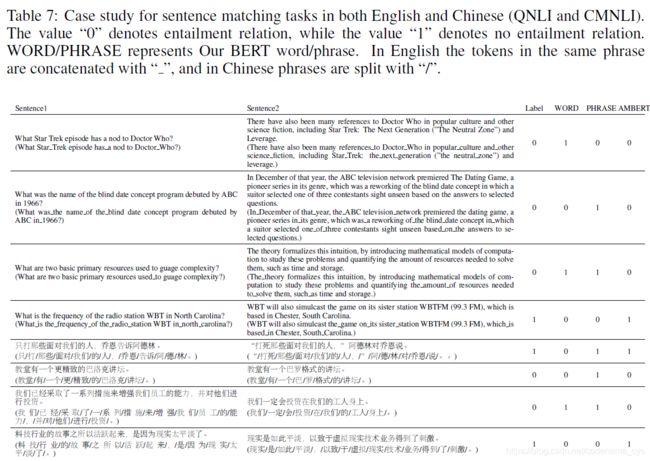
比较1、2以及5、6这些句子,可以看出作者的论点:
- 细颗粒模型对于词力度的词汇把握上存在不足;
- 而针对粗颗粒度分词模型,错误的分词方式会影响模型的效果。
5. 其他
1. encoder层是否学到不同粒度的信息
在上述实验中,我们注意到,在大多数的任务中,AMBERT模型的效果是优于AMBERT-Combo模型的,这里,作者尝试针对这一现象进行了解释。
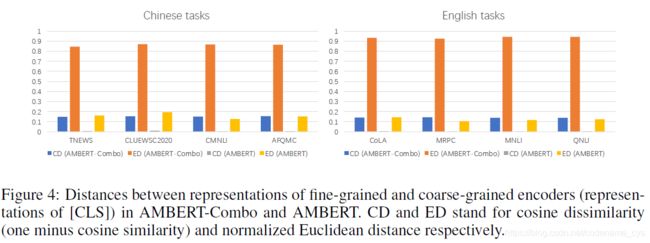
在embedding层之后,粗颗粒度以及细颗粒度的模型在self-attention层中事实上都被一步步处理成了抽象特征,而共享参数使得这些特征被整合在了一起,因此虽然是两个独立的处理过程,但是处理得到的结果在特征表达上将会更为相似。
因此,作者比较了两个模型在粗细颗粒度两个encoder之后得到的特征向量之间的相似度,发现与他的猜测相一致,共享参数之后特征向量的相似度明显更高,不过这个结论事实上也挺直觉的。
2. self-attention考察
除此之外,作者还考察了一下第一层self-attention层的attention分布,得到结果图如下:
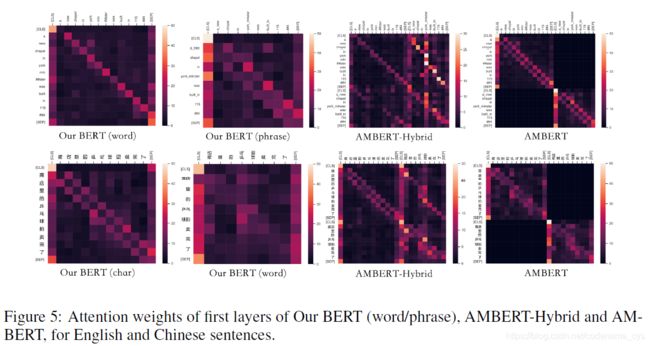
显然,可以看到:
- BERT以及AMBERT模型的attention结果更靠近前后关联的词,即更专注于词颗粒度的局域信息,而AMBERT-Hybrid由于同时输入了不同颗粒度的模型,导致模型在第一层的attention时出现了混乱。
4. 结论
本文的作者李航博士基于bert中文模型只是用了字颗粒度输入的问题提出了使用多种颗粒度信息的AMBERT模型,从而在大部分的中文分类以及阅读理解任务中取得了sota的效果。
毫无疑问,使用多种颗粒度信息输入的这个思路是非常有意思的,给了我很大的启发,不过他的结论坦率地说我保留一定的怀疑态度,因为本质上来说他这个模型使用了两个encoder,和ensemble模型是非常类似的,因此,我比较担心性能的提升是否真的单纯来源于不同颗粒度信息,而非来源于误差或者ensemble导致的性能提升。
更让人不安的是,模型仅仅在中文任务中取得了较好的表现,在英文任务中的表现是不如Roberta的,虽然李航博士在论文中给出了一种合理的解释,但是却无法排除其他的可能性。
因此,我暂时对这篇文章的结论持保留态度,不过这个思路确实可以借鉴到其他的nlp任务当中,应该能够对性能提升有所帮助。
5. 参考链接
- AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization