实战Kaggle比赛(二)——房价预测
比赛网址 https://www.kaggle.com/c/house-prices-advanced-regression-techniques
下载数据集
读取数据集
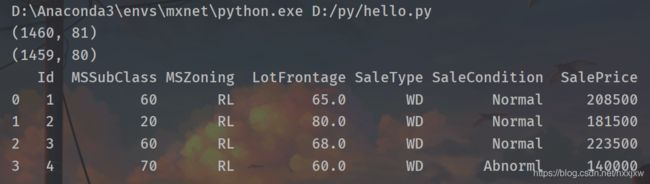
import d2lzh as d2l from mxnet import autograd, gluon, init, nd from mxnet.gluon import data as gdata, loss as gloss, nn import numpy as np import pandas as pd train_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/train.csv') test_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/test.csv') print(train_data.shape) print(test_data.shape) #查看前4个样本的前4个特征、后2个特征和标签 print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) #将所有的训练数据和测试数据的79个特征按样本连结。 all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
预处理数据集
import d2lzh as d2l from mxnet import autograd, gluon, init, nd from mxnet.gluon import data as gdata, loss as gloss, nn import numpy as np import pandas as pd train_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/train.csv') test_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/test.csv') print(train_data.shape) print(test_data.shape) #查看前4个样本的前4个特征、后2个特征和标签 print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) #将所有的训练数据和测试数据的79个特征按样本连结。 all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) ##预处理数据集 #对连续数值的特征做标准化(standardization):设该特征在整个数据集上的均值为 μ ,标准差为 σ 。那么,我们可以将该特征的每个值先减去 μ 再除以 σ 得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。 numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index all_features[numeric_features] = all_features[numeric_features].apply( lambda x: (x - x.mean()) / (x.std())) # 标准化后,每个特征的均值变为0,所以可以直接用0来替换缺失值 all_features[numeric_features] = all_features[numeric_features].fillna(0) #将离散数值转成指示特征。举个例子,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。 # dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征 all_features = pd.get_dummies(all_features, dummy_na=True) print(all_features.shape) #通过values属性得到NumPy格式的数据,并转成NDArray方便后面的训练。 n_train = train_data.shape[0] train_features = nd.array(all_features[:n_train].values) test_features = nd.array(all_features[n_train:].values) train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1))
训练模型
import d2lzh as d2l from mxnet import autograd, gluon, init, nd from mxnet.gluon import data as gdata, loss as gloss, nn import numpy as np import pandas as pd train_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/train.csv') test_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/test.csv') print(train_data.shape) print(test_data.shape) #查看前4个样本的前4个特征、后2个特征和标签 print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) #将所有的训练数据和测试数据的79个特征按样本连结。 all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) ##预处理数据集 #对连续数值的特征做标准化(standardization):设该特征在整个数据集上的均值为 μ ,标准差为 σ 。那么,我们可以将该特征的每个值先减去 μ 再除以 σ 得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。 numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index all_features[numeric_features] = all_features[numeric_features].apply( lambda x: (x - x.mean()) / (x.std())) # 标准化后,每个特征的均值变为0,所以可以直接用0来替换缺失值 all_features[numeric_features] = all_features[numeric_features].fillna(0) #将离散数值转成指示特征。举个例子,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。 # dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征 all_features = pd.get_dummies(all_features, dummy_na=True) print(all_features.shape) #通过values属性得到NumPy格式的数据,并转成NDArray方便后面的训练。 n_train = train_data.shape[0] train_features = nd.array(all_features[:n_train].values) test_features = nd.array(all_features[n_train:].values) train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1)) ##训练模型 #使用一个基本的线性回归模型和平方损失函数来训练模型。 loss = gloss.L2Loss() def get_net(): net = nn.Sequential() net.add(nn.Dense(1)) net.initialize() return net #下面定义比赛用来评价模型的对数均方根误差。给定预测值 y^1,…,y^n 和对应的真实标签 y1,…,yn def log_rmse(net, features, labels): # 将小于1的值设成1,使得取对数时数值更稳定 clipped_preds = nd.clip(net(features), 1, float('inf')) rmse = nd.sqrt(2 * loss(clipped_preds.log(), labels.log()).mean()) return rmse.asscalar() def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size): train_ls, test_ls = [], [] train_iter = gdata.DataLoader(gdata.ArrayDataset( train_features, train_labels), batch_size, shuffle=True) # 这里使用了Adam优化算法 trainer = gluon.Trainer(net.collect_params(), 'adam', { 'learning_rate': learning_rate, 'wd': weight_decay}) for epoch in range(num_epochs): for X, y in train_iter: with autograd.record(): l = loss(net(X), y) l.backward() trainer.step(batch_size) train_ls.append(log_rmse(net, train_features, train_labels)) if test_labels is not None: test_ls.append(log_rmse(net, test_features, test_labels)) return train_ls, test_ls #k折交叉验证 def get_k_fold_data(k, i, X, y): assert k > 1 fold_size = X.shape[0] // k X_train, y_train = None, None for j in range(k): idx = slice(j * fold_size, (j + 1) * fold_size) X_part, y_part = X[idx, :], y[idx] if j == i: X_valid, y_valid = X_part, y_part elif X_train is None: X_train, y_train = X_part, y_part else: X_train = nd.concat(X_train, X_part, dim=0) y_train = nd.concat(y_train, y_part, dim=0) return X_train, y_train, X_valid, y_valid #我们训练k次并返回训练和验证的平均误差 def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size): train_l_sum, valid_l_sum = 0, 0 for i in range(k): data = get_k_fold_data(k, i, X_train, y_train) net = get_net() train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size) train_l_sum += train_ls[-1] valid_l_sum += valid_ls[-1] if i == 0: d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse', range(1, num_epochs + 1), valid_ls, ['train', 'valid']) print('fold %d, train rmse %f, valid rmse %f' % (i, train_ls[-1], valid_ls[-1])) return train_l_sum / k, valid_l_sum / k
模型选择
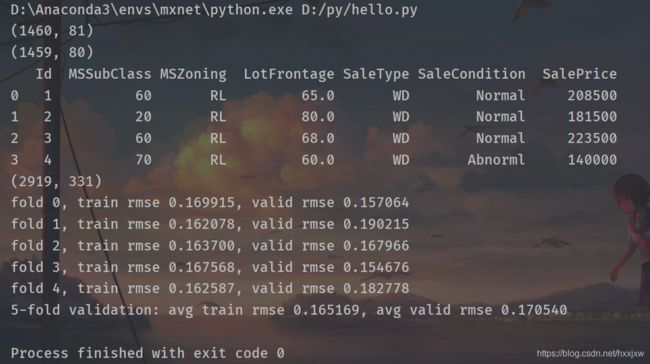
import d2lzh as d2l from mxnet import autograd, gluon, init, nd from mxnet.gluon import data as gdata, loss as gloss, nn import numpy as np import pandas as pd train_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/train.csv') test_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/test.csv') print(train_data.shape) print(test_data.shape) #查看前4个样本的前4个特征、后2个特征和标签 print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) #将所有的训练数据和测试数据的79个特征按样本连结。 all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) ##预处理数据集 #对连续数值的特征做标准化(standardization):设该特征在整个数据集上的均值为 μ ,标准差为 σ 。那么,我们可以将该特征的每个值先减去 μ 再除以 σ 得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。 numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index all_features[numeric_features] = all_features[numeric_features].apply( lambda x: (x - x.mean()) / (x.std())) # 标准化后,每个特征的均值变为0,所以可以直接用0来替换缺失值 all_features[numeric_features] = all_features[numeric_features].fillna(0) #将离散数值转成指示特征。举个例子,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。 # dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征 all_features = pd.get_dummies(all_features, dummy_na=True) print(all_features.shape) #通过values属性得到NumPy格式的数据,并转成NDArray方便后面的训练。 n_train = train_data.shape[0] train_features = nd.array(all_features[:n_train].values) test_features = nd.array(all_features[n_train:].values) train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1)) ##训练模型 #使用一个基本的线性回归模型和平方损失函数来训练模型。 loss = gloss.L2Loss() def get_net(): net = nn.Sequential() net.add(nn.Dense(1)) net.initialize() return net #下面定义比赛用来评价模型的对数均方根误差。给定预测值 y^1,…,y^n 和对应的真实标签 y1,…,yn def log_rmse(net, features, labels): # 将小于1的值设成1,使得取对数时数值更稳定 clipped_preds = nd.clip(net(features), 1, float('inf')) rmse = nd.sqrt(2 * loss(clipped_preds.log(), labels.log()).mean()) return rmse.asscalar() def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size): train_ls, test_ls = [], [] train_iter = gdata.DataLoader(gdata.ArrayDataset( train_features, train_labels), batch_size, shuffle=True) # 这里使用了Adam优化算法 trainer = gluon.Trainer(net.collect_params(), 'adam', { 'learning_rate': learning_rate, 'wd': weight_decay}) for epoch in range(num_epochs): for X, y in train_iter: with autograd.record(): l = loss(net(X), y) l.backward() trainer.step(batch_size) train_ls.append(log_rmse(net, train_features, train_labels)) if test_labels is not None: test_ls.append(log_rmse(net, test_features, test_labels)) return train_ls, test_ls #k折交叉验证 def get_k_fold_data(k, i, X, y): assert k > 1 fold_size = X.shape[0] // k X_train, y_train = None, None for j in range(k): idx = slice(j * fold_size, (j + 1) * fold_size) X_part, y_part = X[idx, :], y[idx] if j == i: X_valid, y_valid = X_part, y_part elif X_train is None: X_train, y_train = X_part, y_part else: X_train = nd.concat(X_train, X_part, dim=0) y_train = nd.concat(y_train, y_part, dim=0) return X_train, y_train, X_valid, y_valid #我们训练k次并返回训练和验证的平均误差 def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size): train_l_sum, valid_l_sum = 0, 0 for i in range(k): data = get_k_fold_data(k, i, X_train, y_train) net = get_net() train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size) train_l_sum += train_ls[-1] valid_l_sum += valid_ls[-1] if i == 0: d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse', range(1, num_epochs + 1), valid_ls, ['train', 'valid']) print('fold %d, train rmse %f, valid rmse %f' % (i, train_ls[-1], valid_ls[-1])) return train_l_sum / k, valid_l_sum / k #我们使用一组未经调优的超参数并计算交叉验证误差。可以改动这些超参数来尽可能减小平均测试误差。 k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64 train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size) print('%d-fold validation: avg train rmse %f, avg valid rmse %f' % (k, train_l, valid_l))
预测并在Kaggle提交结果
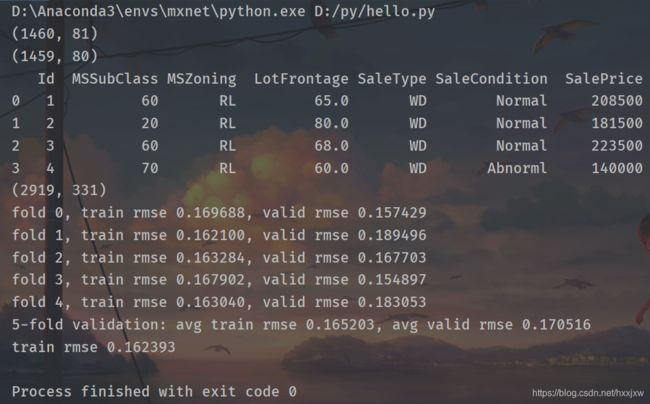
import d2lzh as d2l from mxnet import autograd, gluon, init, nd from mxnet.gluon import data as gdata, loss as gloss, nn import numpy as np import pandas as pd train_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/train.csv') test_data = pd.read_csv('kaggle/house-prices-advanced-regression-techniques/test.csv') print(train_data.shape) print(test_data.shape) #查看前4个样本的前4个特征、后2个特征和标签 print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) #将所有的训练数据和测试数据的79个特征按样本连结。 all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) ##预处理数据集 #对连续数值的特征做标准化(standardization):设该特征在整个数据集上的均值为 μ ,标准差为 σ 。那么,我们可以将该特征的每个值先减去 μ 再除以 σ 得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。 numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index all_features[numeric_features] = all_features[numeric_features].apply( lambda x: (x - x.mean()) / (x.std())) # 标准化后,每个特征的均值变为0,所以可以直接用0来替换缺失值 all_features[numeric_features] = all_features[numeric_features].fillna(0) #将离散数值转成指示特征。举个例子,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。 # dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征 all_features = pd.get_dummies(all_features, dummy_na=True) print(all_features.shape) #通过values属性得到NumPy格式的数据,并转成NDArray方便后面的训练。 n_train = train_data.shape[0] train_features = nd.array(all_features[:n_train].values) test_features = nd.array(all_features[n_train:].values) train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1)) ##训练模型 #使用一个基本的线性回归模型和平方损失函数来训练模型。 loss = gloss.L2Loss() def get_net(): net = nn.Sequential() net.add(nn.Dense(1)) net.initialize() return net #下面定义比赛用来评价模型的对数均方根误差。给定预测值 y^1,…,y^n 和对应的真实标签 y1,…,yn def log_rmse(net, features, labels): # 将小于1的值设成1,使得取对数时数值更稳定 clipped_preds = nd.clip(net(features), 1, float('inf')) rmse = nd.sqrt(2 * loss(clipped_preds.log(), labels.log()).mean()) return rmse.asscalar() def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size): train_ls, test_ls = [], [] train_iter = gdata.DataLoader(gdata.ArrayDataset( train_features, train_labels), batch_size, shuffle=True) # 这里使用了Adam优化算法 trainer = gluon.Trainer(net.collect_params(), 'adam', { 'learning_rate': learning_rate, 'wd': weight_decay}) for epoch in range(num_epochs): for X, y in train_iter: with autograd.record(): l = loss(net(X), y) l.backward() trainer.step(batch_size) train_ls.append(log_rmse(net, train_features, train_labels)) if test_labels is not None: test_ls.append(log_rmse(net, test_features, test_labels)) return train_ls, test_ls #k折交叉验证 def get_k_fold_data(k, i, X, y): assert k > 1 fold_size = X.shape[0] // k X_train, y_train = None, None for j in range(k): idx = slice(j * fold_size, (j + 1) * fold_size) X_part, y_part = X[idx, :], y[idx] if j == i: X_valid, y_valid = X_part, y_part elif X_train is None: X_train, y_train = X_part, y_part else: X_train = nd.concat(X_train, X_part, dim=0) y_train = nd.concat(y_train, y_part, dim=0) return X_train, y_train, X_valid, y_valid #我们训练k次并返回训练和验证的平均误差 def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size): train_l_sum, valid_l_sum = 0, 0 for i in range(k): data = get_k_fold_data(k, i, X_train, y_train) net = get_net() train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size) train_l_sum += train_ls[-1] valid_l_sum += valid_ls[-1] if i == 0: d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse', range(1, num_epochs + 1), valid_ls, ['train', 'valid']) print('fold %d, train rmse %f, valid rmse %f' % (i, train_ls[-1], valid_ls[-1])) return train_l_sum / k, valid_l_sum / k #我们使用一组未经调优的超参数并计算交叉验证误差。可以改动这些超参数来尽可能减小平均测试误差。 k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64 train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size) print('%d-fold validation: avg train rmse %f, avg valid rmse %f' % (k, train_l, valid_l)) #预测并在Kaggle提交结果 def train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size): net = get_net() train_ls, _ = train(net, train_features, train_labels, None, None, num_epochs, lr, weight_decay, batch_size) d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse') print('train rmse %f' % train_ls[-1]) preds = net(test_features).asnumpy() test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0]) submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1) submission.to_csv('kaggle/house-prices-advanced-regression-techniques/submission.csv', index=False) train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size)
在kaggle上提交,查看结果




参考
http://zh.gluon.ai/chapter_deep-learning-basics/kaggle-house-price.html