Java8流式编程
文章目录
- 流式编程
- 流(Stream)
-
- Stream特点
- Stream运行机制
- 迭代类型
-
- 外部迭代
- 内部迭代
- 二者区别
- 流的创建
-
- 数组创建
- 集合创建
- 值创建
- 函数创建
- 流的中间操作
-
- distinct(去重)
- filter(过滤)
- sorted(排序)
- limit(截断)
- skip(跳过)
- map(转换流)
- flatMap(转换流并合并)
- peek(打印或修改)
- parallel(转为并行流)
- sequential(转为串行流)
- 流的终止操作
-
- forEach(遍历)
- forEachOrdered(顺序遍历)
- toArray(转为数组)
- findFirst(取第一个元素)
- findAny(取任意一个元素)
- allMatch(全都匹配)
- anyMatch(任意匹配)
- noneMatch(都不匹配)
- reduce(组合流元素)
- max(元素最大值)
- min(元素最小值)
- count(元素个数)
- sum(元素求和)
- average(元素平均值)
- collect(收集)
- 流的其他方法
-
- concat(合并流)
- 流相关函数式接口
- 其他相关类
-
- Collectors
- Optional
流式编程
对于Java语言,我们最常用的面向对象编程都属于命令式编程。在Java8的时候,引入了函数式编程。
Java8前,对集合进行处理、排序、对集合多次操作、对集合进行处理后,返回一些符合要求的特定的集合等,都比较麻烦。我们通常需要对集合进行遍历处理,写许多冗余代码。所以Java8引入了基于流式编程的Stream对集合进行一系列的操作。
Stream不是集合元素,也不是数据结构,它相当于一个高级版本的Iterator,不可以重复遍历里面的数据,像水一样,流过了就一去不复返。它和普通的Iterator不同的是,它可以并行遍历,普通的Iterator只能是串行,在一个线程中执行。
流(Stream)
Stream它并不是一个容器,它只是对容器的功能进行了增强,添加了很多便利的操作,例如查找、过滤、分组、排序等一系列的操作。并且有串行、并行两种执行模式,并行模式充分的利用了多核处理器的优势,使用fork/join框架进行了任务拆分,同时提高了执行速度。简而言之,Stream就是提供了一种高效且易于使用的处理数据的方式。
- 串行流操作在一个线程中依次完成;
- 并行流在多个线程中完成。
Stream特点
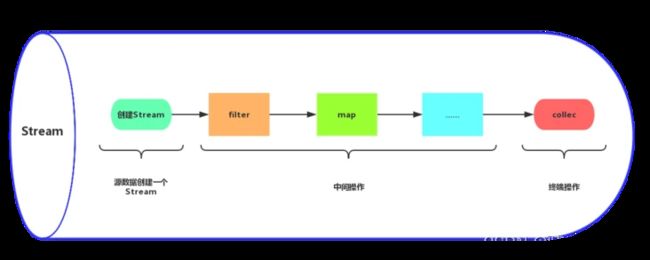
- Stream自己不会存储元素。
- Stream的操作不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream操作是延迟执行的。它会等到需要结果的时候才执行。也就是执行终端操作的时候。
Stream运行机制
-
所有的操作都是链式调用,一个元素只迭代一次;
-
每一个中间操作返回一个新的流;
-
每个流里面有一个属性sourceStage指向同一个地方-链表的头Head。
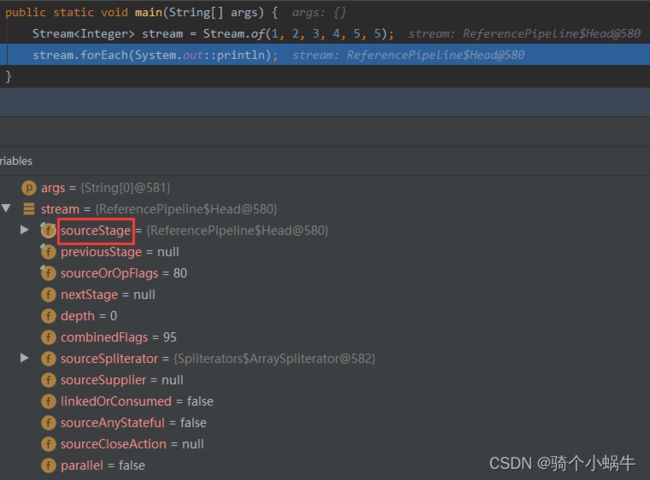
-
在Head里面就会指向nextStage,head->nextStage->nextStage->…->null
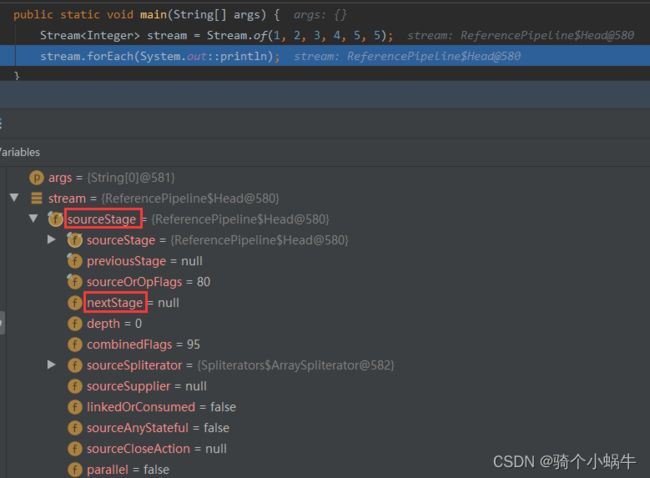
-
有状态操作会把无状态操作截断,单独处理。
-
当没有状态操作时
Stream<Integer> stream = Stream.of(1, 2, 3); long count = stream.filter(integer -> true) .peek(integer -> System.out.println(integer + ":第一个无状态操作")) // .sorted() // .peek(integer -> System.out.println(integer + ":有状态操作")) .filter(integer -> true) .peek(integer -> System.out.println(integer + ":第二个无状态操作")) .count(); -
当中间加一个状态操作时
Stream<Integer> stream = Stream.of(1, 2, 3); long count = stream.filter(integer -> true) .peek(integer -> System.out.println(integer + ":第一个无状态操作")) .sorted() .peek(integer -> System.out.println(integer + ":有状态操作")) .filter(integer -> true) .peek(integer -> System.out.println(integer + ":第二个无状态操作")) .count();

-
-
并行环节下,有状态的中间操作不一定能并行操作,并且,被有状态操作隔断的之前的无状态操作也不一定能并行操作。
-
parallel/sequetial这两个操作也是中间操作,但是他们不创建流,他们只修改流中Head的并行标志。
迭代类型
Stream其实就是一个高级的迭代器,它不是一个数据结构,不是一个集合,不会存放数据。它只关注怎么高效处理数据,把数据放入一个流水线中处理。
迭代类型可以分为外部迭代和内部迭代。
外部迭代
外部迭代就是我们所使用的的对集合、数组的遍历操作。
内部迭代
利用Stream流编程或者lambda表达式来进行迭代。
相对于外部迭代,我们不需要关注它怎么样去处理数据,我们只需要给它数据,然后告诉它我们想要的结果就可以了。
二者区别
- 外部迭代是一个串行的操作,如果数据量过大,性能可能会受影响。
- 内部迭代相对来说比较简短,不用关注那么多细节。可以用并行流,达到并行操作,开发人员不用去考虑线程问题。
流的创建
数组创建
Arrays.stream
Arrays的静态方法stream() 可以获取数组流
String[] arr = { "a", "b", "c", "d", "e", "f", "g" };
Stream<String> stream1 = Arrays.stream(arr);
集合创建
Collection接口提供了两个默认方法创建流:stream()、parallelStream()
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
Stream<String> stream = list.stream();
值创建
Stream.of
使用静态方法 Stream.of(), 通过显示值创建一个流。它可以接收任意数量的参数。
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
函数创建
Stream.iterate
Stream.generate
使用静态方法 Stream.iterate() 和 Stream.generate()创建无限流。
Stream<Double> stream = Stream.generate(Math::random).limit(5);
Stream<Integer> stream1 = Stream.iterate(0, i -> i + 1).limit(5);
注意:使用无限流一定要配合limit截断,不然会无限制创建下去。
流的中间操作
如果Stream只有中间操作是不会执行的,当执行终端操作的时候才会执行中间操作,这种方式称为延迟加载或惰性求值。多个中间操作组成一个中间操作链,只有当执行终端操作的时候才会执行一遍中间操作链。
-
无状态操作
所谓无状态就是一次操作,不能保存数据,线程安全。filter、map、flatMap、peek 、unordered属于无状态操作。
这些操作只是从输入流中获取每一个元素,并且在输出流中得到一个结果,元素和元素之间没有依赖关系,不需要存储数据。
-
有状态操作
所谓有状态就是有数据存储功能,线程不安全。distinct、sorted、limit、skip属于有状态操作。
这些操作需要先知道先前的历史数据,而且需要存储一些数据,元素之间有依赖关系。
| 方法 | 描述 |
|---|---|
| distinct | 去重:返回一个去重后的Stream |
| filter | 过滤:按指定的Predicate进行过滤,返回未被过滤的元素的Stream |
| sorted | 排序:返回排序后的Stream |
| limit | 截断:使其元素不超过指定数量,得到新的Stream |
| skip | 跳过:返回一个扔掉了前 n指定个数元素的Stream。若元素不足指定个数,则返回一个空Stream |
| map | 转换:接收一个Function函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素得到一个新的 |
| flatMap | 转换合并:接收一个Function函数作为参数,将原Stream中的每个元素都转换成另一个Stream,然后把所有Stream连接成一个新的Stream |
| peek | 消费:使用传入的Consumer对象对所有元素进行消费后,返回一个新的包含所有原来元素的Stream,常用于调试时打印元素信息 |
| parallel | 转为并行流:转为一个并行Stream |
| sequential | 转为串行流:转为一个串行Stream |
distinct(去重)
Stream distinct()
去重,通过流所生成元素的 hashCode() 和 equals() 去除重复元素。
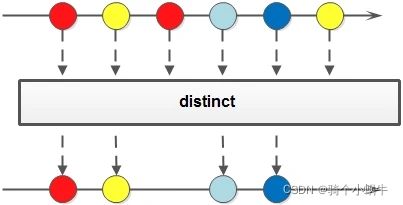
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5);
Stream<Integer> stream1 = stream.distinct();
filter(过滤)
Stream filter(Predicate predicate)
过滤,对Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素。
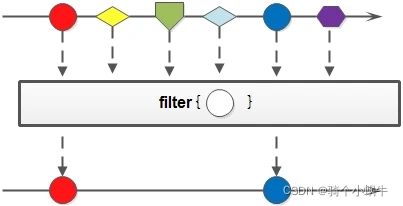
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5);
Stream<Integer> stream1 = stream.filter(integer -> integer == 1);
sorted(排序)
Stream sorted(Comparator comparator)
排序,指定比较规则进行排序。
List<User> list = new ArrayList<>();
User user = new User();
user.setId("2");
list.add(user);
User user1 = new User();
user1.setId("1");
list.add(user1);
Stream<User> stream = list.stream().sorted(Comparator.comparing(User::getId));
Comparator comparator
指定排序字段,默认升序排列
Comparator.reversed()
排序反转,如果是升序排序,反转后就变成降序排序
limit(截断)
Stream limit(long maxSize)
截断流,使其元素不超过给定数量。如果元素的个数小于maxSize,那就获取所有元素。
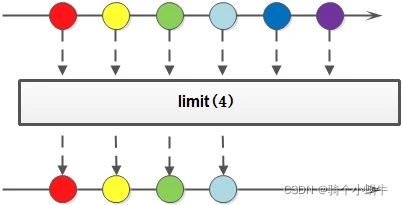
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5);
Stream<Integer> stream1 = stream.limit(2);
skip(跳过)
Stream skip(long n)
跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补。
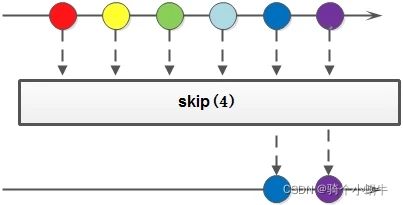
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5);
Stream<Integer> stream1 = stream.limit(3).skip(1);
取前3个元素并跳过1个元素。
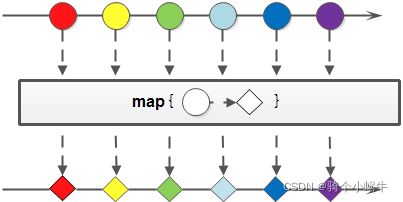
map(转换流)
Stream map(Function mapper)
转换流,将原Stream转换成一个新的Stream。接收一个Function函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
注意:这里的map的含义是映射(全称mapping),不是我们常理解的Map对象。
map方法有3个扩展方法:
- mapToInt:转换成IntStream
- mapToLong:转换成LongStream
- mapToDouble:转换成DoubleStream
List<User> list = new ArrayList<>();
User user = new User();
user.setRoles(Arrays.asList("admin","test"));
list.add(user);
User user1 = new User();
user1.setRoles(Arrays.asList("admin"));
list.add(user1);
Stream<List<String>> stream = list.stream().map(User::getRoles);
flatMap(转换流并合并)
Stream flatMap(Function> mapper)
转换流,将原Stream中的每个元素都转换成另一个Stream,然后把所有Stream连接成一个新的Stream。接收一个Function函数作为参数。

List<User> list = new ArrayList<>();
User user = new User();
user.setRoles(Arrays.asList("admin","test"));
list.add(user);
User user1 = new User();
user1.setRoles(Arrays.asList("admin"));
list.add(user1);
Stream<String> roleStream = list.stream().flatMap(u -> u.getRoles().stream());
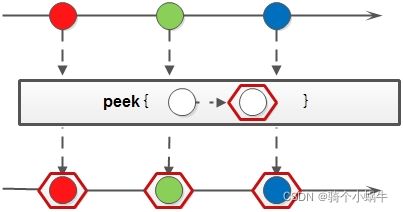
peek(打印或修改)
Stream peek(Consumer action)
生成一个包含源stream所有元素的新stream,同时会提供一个消费函数(consumer实例),新stream每个元素被消费的时候都会执行给定的消费函数。
peek主要被用在debug用途。可用于打印某中间操作后得到的元素信息。
Stream<Integer> stream = Stream.of(5, 2, 1, 4, 5, 5);
List<Integer> list = stream
.filter(integer -> integer > 2)
.peek(integer -> System.out.println(integer + "大于2"))
.filter(integer -> integer > 4)
.peek(integer -> System.out.println(integer + "大于4"))
.collect(Collectors.toList());
打印结果
5大于2
5大于4
4大于2
5大于2
5大于4
5大于2
5大于4
这里可以看出,操作顺序是:每个元素完成所有中间操作后,下一个元素才开始完成所有中间操作。简单来说就是处理元素是一个一个的来的,上个元素完成后,下个元素才继续。
parallel(转为并行流)
S parallel()
将流转化为并行流。
流的并行操作的线程数默认是机器的CPU个数。默认使用的线程池是ForkJoinPool.commonPool线程池。
sequential(转为串行流)
S sequential()
将流转化为串行流。
多次调用parallel()和sequential(),以最后一次为准。
流的终止操作
| 方法 | 描述 |
|---|---|
| forEach | 遍历:串行流的forEach会按顺序执行,但并行流的时候,并不会按顺序执行 |
| forEachOrdered | 顺序遍历:确保按照原始流的顺序执行(即使是并行流) |
| toArray | 转为数组:将流转化为合适类型的数组 |
| findFirst | 取第一个元素:返回一个含有第一个流元素的Optional类型的对象,如果流为空返回Optional.empty。无论并行流还是串行流,总是会选择流中的第一个元素(有顺序的) |
| findAny | 取任意一个元素:返回含有任意一个流元素的Optional类型的对象,如果流为空返回Optional.empty。串行流去第一个元素,并行流可能取任意一个元素 |
| allMatch | 全都匹配:Stream中全部元素符合传入的Predicate,返回 true,只要有一个不满足就返回false。 |
| anyMatch | 任意匹配:Stream中只要有一个元素符合传入的 Predicate,返回 true。否则返回false |
| noneMatch | 都不匹配:Stream中没有一个元素符合传入的 Predicate,返回 true。只要有一个满足就返回false |
| reduce | 组合流元素:它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。字符串拼接、sum、min、max、average 都是特殊的reduce |
| max | 元素的最大值:如果流为空返回Optional.empty |
| min | 元素的最小值:如果流为空返回Optional.empty |
| count | 元素个数:流中的元素个数,返回long类型 |
| sum | 元素求和:所有流元素进行求和 |
| average | 元素平均值:求取流元素平均值 |
| collect | 收集:集流元素到结果集中 |
forEach(遍历)
遍历
forEach(Consumer)
接受一个Consumer函数。
串行流的forEach会按顺序执行,但并行流的时候,并不会按顺序执行
Stream.of(1, 2, 3, 4, 5, 6).parallel().forEach(a -> System.out.print(a));
打印日志
426135
并行流的时候并没有按顺序遍历(串行流的时候是顺序遍历的)
forEachOrdered(顺序遍历)
forEachOrdered(Consumer)
确保按照原始流的顺序执行(即使是并行流)
Stream.of(1, 2, 3, 4, 5, 6).parallel().forEachOrdered(a -> System.out.println(a));
打印日志
123456
并行流的时候也是按顺序遍历的
toArray(转为数组)
转化为数组
- toArray()
将流转换成适当类型的数组。 - toArray(generator)
在特殊情况下,生成器用于分配自定义的数组存储。
Object[] array = Stream.of(1, 2, 3, 4, 5, 6).toArray();
Integer[] array1 = Stream.of(1, 2, 3, 4, 5, 6).toArray(Integer[]::new);
findFirst(取第一个元素)
findFirst()
返回一个含有第一个流元素的Optional类型的对象,如果流为空返回 Optional.empty。
findFirst() 无论流是串行流还是并行流,总是会选择流中的第一个元素(有顺序的)。
Optional<Integer> first = Stream.of(1, 2, 3, 4, 5, 6).findFirst();
Optional<Integer> first1 = Stream.of(1, 2, 3, 4, 5, 6).parallel().findFirst();
System.out.println(first.get());
System.out.println(first1.get());
1
1
findAny(取任意一个元素)
返回含有任意一个流元素的Optional类型的对象,如果流为空返回 Optional.empty。
对于串行流,findAny()和findFirst() 效果相同,选择流中的第一个元素。
对于并行流,findAny()也会选择流中的第一个元素(但因为是并行流,从定义上来看是选择任意元素)。
Optional<Integer> any = Stream.of(1, 2, 3, 4, 5, 6).findAny();
Optional<Integer> any1 = Stream.of(1, 2, 3, 4, 5, 6).parallel().findAny();
System.out.println(any.get());
System.out.println(any1.get());
1
4
allMatch(全都匹配)
allMatch(Predicate)
全都匹配
Stream中全部元素符合传入的Predicate,返回 true,只要有一个不满足就返回false。
boolean b = Stream.of(1, 2, 3, 4, 5, 6).allMatch(a -> a <= 6);
anyMatch(任意匹配)
anyMatch(Predicate)
任意匹配
Stream中只要有一个元素符合传入的 Predicate,返回 true。否则返回false
boolean b1 = Stream.of(1, 2, 3, 4, 5, 6).anyMatch(a -> a == 6);
boolean b2 = Stream.of(1, 2, 3, 4, 5, 6).anyMatch(a -> a > 6);
System.out.println(b1);
System.out.println(b2);
true
false
noneMatch(都不匹配)
noneMatch(Predicate)
都不匹配
Stream中没有一个元素符合传入的 Predicate,返回 true。只要有一个满足就返回false。
boolean b1 = Stream.of(1, 2, 3, 4, 5, 6).noneMatch(a -> a == 6);
boolean b2 = Stream.of(1, 2, 3, 4, 5, 6).noneMatch(a -> a > 6);
System.out.println(b1);
System.out.println(b2);
false
true
reduce(组合流元素)
把Stream 元素组合起来。
它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。
字符串拼接、sum、min、max、average 都是特殊的reduce。
方法格式:
-
Optional reduce(BinaryOperator accumulator)
Optional<Integer> sum = Stream.of(1, 2, 3, 4, 5, 6).reduce((a1, a2) -> a1 + a2);求和
-
T reduce(T identity, BinaryOperator accumulator)
T identity 提供一个跟Stream中数据同类型的初始值identityInteger sum1 = Stream.of(1, 2, 3, 4, 5, 6).reduce(1, (a1, a2) -> a1 + a2); Integer sum2 = Stream.of(1, 2, 3, 4, 5, 6).parallel().reduce(1, (a1, a2) -> a1 + a2); System.out.println(sum1); System.out.println(sum2);22 27求和,初始值0。
该方法在并行流的情况时统计的数据会有问题,以求和为例: 初始值为a,流元素个数为b,并行流求和的时候是每个元素都和初始值求一次和,再把这些结果求和,所以最终求得的和会比正确值大(b-1)*a -
U reduce(U identity, BiFunction
BinaryOperator combiner 该参数英文翻译为“合路器”,只有在并行流的时候才有效,串行流中使用并不起作用。主要作用是将第二个参数accumulator(累加器)处理后个结果再进行合并。
Integer reduce1 = Stream.of(1, 2, 3, 4).reduce(1, (sum, a) -> { Integer aa = sum + a; System.out.println(sum+"+"+a+"="+aa+"-----accumulator"); return aa; }, (sum1, sum2) -> { Integer sumsum = sum1 + sum2; System.out.println(sum1+"+"+sum2+"="+sumsum+"-----combiner"); return sumsum; }); System.out.println(reduce1); System.out.println("============================"); Integer reduce2 = Stream.of(1, 2, 3, 4).parallel().reduce(1, (sum, a) -> { Integer aa = sum + a; System.out.println(sum+"+"+a+"="+aa+"-----accumulator"); return aa; }, (sum1, sum2) -> { Integer sumsum = sum1 + sum2; System.out.println(sum1+"+"+sum2+"="+sumsum+"-----combiner"); return sumsum; }); System.out.println(reduce2);显然正确求和结果应该为11,串行流时结果正确。但并行流时,结果为17,是错误的。且和发现并行流时才第三个参数combiner才生效了。
错误原因(个人理解,没仔细研究):
- 串行流求和:初始值+值1+值2+值3…
- 并行流求和:(初始值+值1)+(初始值+值2)+(初始值+值3)…
该方法在并行流的情况时统计的数据会有问题,以求和为例: 初始值为a,流元素个数为b,并行流求和的时候是每个元素都和初始值求一次和,再把这些结果求和,所以最终求得的和会比正确值大(b-1)*a
max(元素最大值)
求元素的最大值,如果流为空返回Optional.empty。
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5, 6).max((a1,a2) -> a1.compareTo(a2));
min(元素最小值)
求元素的最小值,如果流为空返回Optional.empty。
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5, 6).min((a1,a2) -> a1.compareTo(a2));
count(元素个数)
流中的元素个数。
long count = Stream.of(1, 2, 3, 4, 5, 6).count();
sum(元素求和)
对所有流元素进行求和。
average(元素平均值)
求取流元素平均值。
collect(收集)
收集,收集流元素转换成最后需要的结果。
collect(Collector)
使用Collector 收集流元素到结果集中,主要是使用 Collectors(java.util.stream.Collectors)。
Collectors的方法如下:
| 方法名 | 描述 |
|---|---|
| toList | 将流中的元素放置到一个列表集合中。这个列表默认为ArrayList。 |
| toSet | 将流中的元素放置到一个无序集set中。默认为HashSet。 |
| toCollection | 将流中的元素全部放置到一个集合中,这里使用Collection,泛指多种集合。 |
| toMap | 根据给定的键生成器和值生成器生成的键和值保存到一个map中返回,键和值的生成都依赖于元素,可以指定出现重复键时的处理方案和保存结果的map。 |
| toConcurrentMap | 与toMap基本一致,只是它最后使用的map是并发Map:ConcurrentHashMap |
| joining | 将流中的元素全部以字符序列的方式连接到一起,可以指定连接符,甚至是结果的前后缀。 内部拼接使用的Java8的新类StringJoiner,可定义连接符和前缀后缀 |
| mapping | 先对流中的每个元素进行映射,即类型转换,然后再将新元素以给定的Collector进行归纳。类似Stream.toMap。 |
| collectingAndThen | 在归纳动作结束之后,对归纳的结果进行再处理。 |
| counting | 元素计数 |
| minBy | 最小值的Optional |
| maxBy | 最大值的Optional |
| summingInt | 求和,结果类型为int |
| summingLong | 求和,结果类型为long |
| summingDouble | 求和,结果类型为double |
| averagingInt | 平均值,结果类型int |
| averagingLong | 平均值,结果类型long |
| averagingDouble | 平均值,结果类型double |
| summarizingInt | 汇总,结果包含元素个数、最大值、最小值、求和值、平均值,值类型都为int |
| summarizingLong | 汇总,结果包含元素个数、最大值、最小值、求和值、平均值,值类型都为long |
| summarizingDouble | 汇总,结果包含元素个数、最大值、最小值、求和值、平均值,值类型都为 |
| reducing | 统计,reducing方法有三个重载方法,其实是和Stream里的三个reduce方法对应的,二者是可以替换使用的,作用完全一致,也是对流中的元素做统计归纳作用。求和、平均值、最大值、最小值等其实就属于一种特殊的统计 |
| groupingBy | 分组,得到一个HashMap |
| groupingByConcurrent | 分组,得到一个ConcurrentHashMap |
| partitioningBy | 将流中的元素按照给定的校验规则的结果分为两个部分,放到一个map中返回,map的键是Boolean类型,值为元素的列表List |
-
toList
List<Integer> list = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toList()); -
toSet
Set<Integer> set = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toSet()); -
toCollection
ArrayList<Integer> list = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toCollection(ArrayList::new)); -
toMap
Map<Integer, Integer> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toMap(i -> i, i -> i)); Map<Integer, Integer> map2 = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toMap(i -> i, i -> i, (k1, k2) -> k1)); HashMap<Integer, Integer> map3 = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toMap(i -> i, i -> i, (k1, k2) -> k1, HashMap::new)); -
toConcurrentMap
ConcurrentMap<Integer, Integer> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i)); ConcurrentMap<Integer, Integer> map2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i, (k1, k2) -> k1)); ConcurrentReferenceHashMap<Integer, Integer> map3 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i, (k1, k2) -> k1, ConcurrentReferenceHashMap::new)); -
joining
String s = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.joining("\",\"", "[\"", "\"]")); List<String> list = JSON.parseArray(s, String.class); -
mapping
List<Integer> list = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.mapping(Integer::valueOf, Collectors.toList())); -
collectingAndThen
Integer size = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); -
counting
Long size = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.counting()); -
minBy
Optional<String> max = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.maxBy((a, b) -> a.compareTo(b))); -
maxBy
Optional<String> min= Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.minBy((a, b) -> a.compareTo(b))); -
summingInt
Integer sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingInt(Integer::valueOf)); -
summingLong
Long sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingLong(Long::valueOf)); -
summingDouble
Double sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingDouble(Double::valueOf)); -
averagingInt
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingInt(Integer::valueOf)); -
averagingLong
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingLong(Long::valueOf)); -
averagingDouble
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingDouble(Double::valueOf)); -
summarizingInt
IntSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingInt(a -> a)); -
summarizingLong
LongSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingLong(a -> a)); -
summarizingDouble
DoubleSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingDouble(a -> a)); -
reducing
Optional<Integer> sum1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(Integer::sum)); Integer sum2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(0, Integer::sum)); Integer sum3 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(0, Function.identity(), Integer::sum));注意:2、3两种方法在并行流的情况下统计的数据会有问题,以求和为例: 初始值为a,流元素个数为b,并行流求和的时候是每个元素都和初始值求一次和,再把这些结果求和,所以最终求得的和会比正确值大(b-1)*a -
groupingBy
Map<Integer, List<String>> map1 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf)); Map<Integer, Set<String>> map2 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf, Collectors.toSet())); ConcurrentHashMap<Integer, Set<String>> map3 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf, ConcurrentHashMap::new, Collectors.toSet())); -
groupingByConcurrent
ConcurrentMap<Integer, List<String>> map1 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf)); ConcurrentMap<Integer, Set<String>> map2 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf, Collectors.toSet())); ConcurrentHashMap<Integer, Set<String>> map3 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf, ConcurrentHashMap::new, Collectors.toSet())) -
partitioningBy
Map<Boolean, List<Integer>> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.partitioningBy(a -> a > 3)); Map<Boolean, Set<Integer>> map2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.partitioningBy(a -> a > 3, Collectors.toSet()));
collect(Supplier, BiConsumer, BiConsumer)
收集流元素到结果集合中。
第一个参数用于创建一个新的结果集合,第二个参数用于将下一个元素加入到现有结果合集中,第三个参数用于将两个结果合集合并,第三个参数是有在并行流时才有效。
// 方法1
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5, 6);
ArrayList<Integer> list3 = stream1.collect(ArrayList::new, (list, a) -> list.add(a), (list1, list2) -> list1.addAll(list2));
// 方法2
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5, 6);
ArrayList<Integer> list4 = stream2.parallel().collect(ArrayList::new, (list, a) -> list.add(a), (list1, list2) -> list1.addAll(list2));
- 方法1的第三个参数并没有生效。
- 方法2的第三个参数主要作用是将第二个参数accumulator处理后个结果再进行合并。
流的其他方法
concat(合并流)
合并两个流成一个新的流
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream = Stream.concat(stream1, stream2);
流相关函数式接口
流相关函数式接口可参考文章:Java函数式编程
其他相关类
Collectors
Collectors类在上面有详细讲解到,这里就不在多提。
Optional
暂略。
相关参考文章:「java8系列」流式编程Stream