python读取excel进行数据处理并保存为新的excel结果
一般需要数据处理时我们会使用excel表格,并可使用其自带的求和、排序等功能对数据进行处理,但对于某些复杂的处理,我们可以使用python工具来读取excel数据,并通过python编程,来实现自己所需要的数据处理结果和数据保存方式。
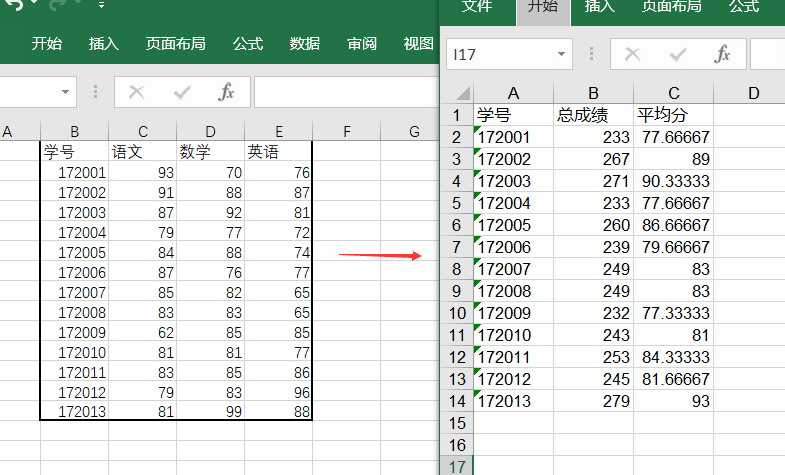
下面以一组学生成绩数据为例,计算每行的总分和平均分,并将最终结果连同学号保存到新的excel中,最终效果如下,左边是原始数据excel文件,右边为数据处理后生成的excel结果文件:
代码
代码如下,已经加了详细注释,需要注意的是,程序中data = ori.iloc[0:,1:5]这句中:
0:指定行的范围:表示行数据从0到最后一行,这样就不需要具体指定最后一行是多少行,另外,这里的0实际是excel中的第2行,可能是因为默认把excel的第1行当作是数据的表头,就跳过了吧1:5指定列的范围:这里其实是左闭右开,即1到4,即excel中的第2列到5列(注意0才是第1列)
为了确定读取的是否正确,可以先打印出部分读取的数据确认一下,如先读取5行。
import numpy as np
import pandas as pd
import xlwt
#原始excel文件名
file = 'data1'
#读取excel中所有数据
ori = pd.read_excel(io=file+'.xlsx')
#选取数据中需要的部分,先是列,后是行
data = ori.iloc[0:,1:5]
#给选取的数据列起个名字,方便后面使用
data.columns=["ID","chinese","math","english"]
#打印5行看看数据对不对
print(data[0:5])
print(data.index)
print("-------------------------")
#新建一个excle文件用于存放结果
workbook = xlwt.Workbook(encoding='utf-8')
booksheet=workbook.add_sheet('Sheet 1',cell_overwrite_ok=True)
#先加个表头
booksheet.write(0,0,'学号') #0行0列
booksheet.write(0,1,'总成绩') #0行1列
booksheet.write(0,2,'平均分') #0行2列
cnt_row = 0
#遍历每一行
for index,row in data.iterrows():
cnt_row = cnt_row+1
#计算总成绩
total = int(row['chinese']+row['math']+row['math'])
#将学号和总成绩存入新的excel文件中
booksheet.write(cnt_row,0,str(row['ID'])) #第0列为学号
booksheet.write(cnt_row,1,total) #第1列为总成绩
booksheet.write(cnt_row,2,float(total/3)) #第2列为平均分
#保存结果文件
workbook.save(file+'-result.xls')
运行
准备自己需要的excel原始文件,我的是data1.xlsx,其它文件名可自行修改python程序中的文件名即可。
运行效果如下:
Python 3.6.8 (tags/v3.6.8:3c6b436a57, Dec 24 2018, 00:16:47) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license()" for more information.
>>>
===== RESTART: G:\python读取excel\calc.py =====
ID chinese math english
0 172001 93 70 76
1 172002 91 88 87
2 172003 87 92 81
3 172004 79 77 72
4 172005 84 88 74
RangeIndex(start=0, stop=13, step=1)
-------------------------
>>>
运行后自动生成一个以"原文件名-result"的excel结果文件,如下图:
