Python-numpy使用及其常用函数介绍
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。某些numpy函数要比python内置函数或方法更加便捷和迅速,在数据科学和日常分析数据中起着十分重要的作用。下面将会以简洁的方式介绍numpy基本操作及其37个常用函数基本用法。
Numpy中花哨的索引(可以看作list切片,即可进行简单的操作)及广播等其他使用方法再次不再赘述,本文旨在能够快速使用numpy以及函数,
一、利用numpy创建数组
# 导入numpy
import numpy as np
np.array(object, dtype, copy, order, subok, ndmin)
常用参数解析:
object:任何具有数据接口方法的对象
ndim:指定生成数组的最小维数
dtype:数据类型
举例
ep:创建浮点型数组
np.array(list, dtype=float)
创建三维数组
np.array(data, ndmin=3)- np.empty(shape, dtype,order)
作用:创建a行b列未初始化数组
参数解析:
shape:指定数组的行数与列数,(注:shape可以设置为list或者tuple类型均可)
dtype:指定数据类型
order:可选参数(一般不使用)
import numpy as np
np.empty([3, 4])
# 输出结果为如下图

- np.zeros(shape, dtype,order)
作用:生成指定大小的全0数组
参数同上
import numpy as np
np.zeros([3, 2])
# 结果如下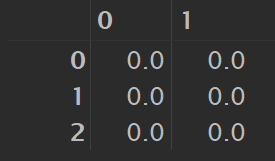
- np.one(shape, dtype,order)
作用:生成全1数组
参数同上
import numpy as np
np.ones([2, 3])
# 结果如下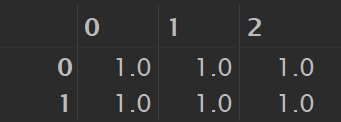
- np.random.randint(low,high, size,dtype)
补充:设置随机数种子:
法一:np.random.seed(number),可以保证在调用np.random函数时输出结果不变
法二:rng = np.random.RandomState(number)
rng.randint(),也可以产生同样的作用
作用:生成随机数指定大小的数组
参数解析:
low:起始数
high:终止数
size:数组大小
import numpy as np
np.random.randint(0, 10, size=(2, 3)) # 指定取值范围是(0, 10),在这个范围中随机取值,生成2行3列的二维数组
# 结果如下
- np.linspace(start,stop,num)
作用:在(start,stop)范围内生成num等分数
参数解析:
start:起始数
stop:终止数
num:将该范围几等分
import numpy as np
np.linspace(0, 10, 5)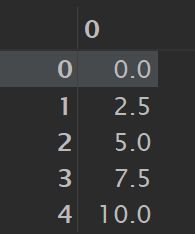
- Numpy常用方法
ndim: 返回int,表示ndarray的维度
shape:返回尺寸,几行几列
size:返回数组元素的个数
dtype:返回数组中元素的类型
rng = np.random.RandomState(0)
data = rng.randint(0, 10, size=(4, 3))
data.ndim
# 输出结果:2二、Numpy常用函数基本使用方法
1.np.corrcoef(x,y,rowvar)
作用:此函数在机器学习中使用的较多,通常计算相关性系数,绘制热图或作它用
参数解析:
x:数组
y:数组,x、y大小相同
rowvar:bool,如果' rowvar '为True(默认值),则每一行表示一个变量,列中有观察值。 否则,关系将被转置:每一列表示一个变量,而行包含观测值。
Array1 = [[1, 2, 3], [4, 5, 6]]
Array2 = [[11, 25, 346], [734, 48, 49]]
data = np.corrcoef(Array1, Array2 )
data
如果索引为0-3,那么对角线上的数字为两个相同元素的相关系数,为1。
2.np.unique(array)
作用:对于一维数据或列表,unique函数去除其中重复的元素 ,并按照元素由小到大返回一个新的无元素重复的元组或者列表
np.random.seed(0)
data = np.random.randint(0, 10, 100)
data # 分别对应两个不同的结果,便于参考对比
np.unique(data)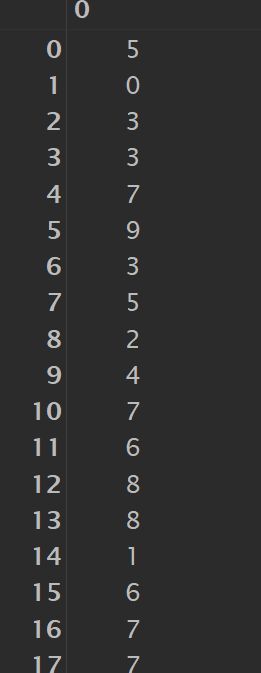
上图为未降重之前

上图为降重之后,结果清晰可见
3.np.where(condition,x,y)
作用及参数解析:
np.where(condition,x,y) 当where内有三个参数时,第一个参数表示条件,当条件成立时where方法返回x,当条件不成立时where返回y
np.where(condition) 当where内只有一个参数时,那个参数表示条件,当条件成立时,where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式,在索引后加了一个[0],这也是非常常见的用法,其作用是把返回的1维tuple转换(取出来)成numpy。
多条件时condition,&表示与,|表示或。如a = np.where((0
a = np.arange(10)
np.where(a < 5, a*5, a)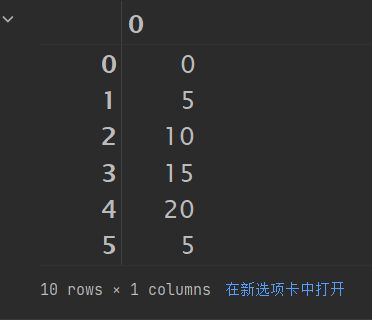
4.np.argsort(a,axis)
作用:对于一个一维或多维数组,返回数组中数据对应的索引,由小到大
参数解析:
a:需要整理大小的数组
axis:按照x轴或者y轴进行排序
rng = np.random.RandomState(0)
data = rng.randint(0, 10, 10)
print(data)
print(np.argsort(data))
data1 = np.random.randint(0, 10, size=(3, 4))
print(data1)
print(np.argsort(data1, axis=0))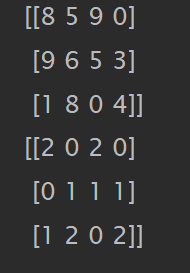
5.np.dot(a,b)
作用:
Numpy中dot()函数主要功能有两个:向量点积和矩阵乘法
x.dot(y) 等价于 np.dot(x,y) ———x是m*n 矩阵 ,y是n*m矩阵,则x.dot(y) 得到m*m矩阵。
如果处理的是一维数组,则得到的是两数组的內积。
如果处理的是二维数组(矩阵),则得到的是矩阵积
np.dot(x, y), 当x为二维矩阵,y为一维向量,这时y会转换一维矩阵进行计算
np.dot(x, y)中,x、y都是二维矩阵,进行矩阵积计算
np.random.seed(0)
a = np.random.randint(0, 10, 5)
b = np.random.randint(0, 10, 5)
print(a)
print(b)
np.dot(a, b)
6.np.bincount(array)
作用:依次返回列表中索引出现的次数,不允许有负值
参数解析:
array:待排序数组
np.random.seed(0)
a = np.random.randint(0, 10, 10)
print(a)
print(np.bincount(a))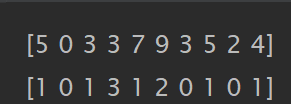
7.np.arange(start,end)
作用:生成end-start个整数,左闭右开,也可以设置步长
np.arange(0, 5)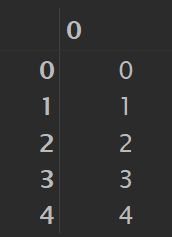
8.data.ndim
作用:求数据的维度
np.random.randint(0, 10, size=(2, 3)).ndim9.data.size
作用:求数据中的元素个数
np.random.randint(0, 10, size=(2, 3)).size
10.data.ravel()
作用:将高维数组拉伸为一个一维矩阵,常用于机器学习对于图片的处理中
np.random.seed(0)
data = np.random.randint(0, 10, size=(2, 3))
print(data)
print(data.ravel())
11.矩阵拼接
np.hstack((a,b))
作用:横向拼接两个数组
>>> a = np.array((1,2,3))
>>> b = np.array((4,5,6))
>>> np.hstack((a,b))
array([1, 2, 3, 4, 5, 6])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[4],[5],[6]])
>>> np.hstack((a,b))
array([[1, 4],
[2, 5],
[3, 6]])np.vstack()
作用:纵向拼接两个数组
12.分离矩阵
np.hsplit(data,n)
作用:将数组横向分解为n份
np.random.seed(0)
a = np.random.randint(0, 10, size=(4, 4))
print(np.hsplit(a, 4))输出结果为:
[array([[5],
[7],
[2],
[8]]), array([[0],
[9],
[4],
[8]]), array([[3],
[3],
[7],
[1]]), array([[3],
[5],
[6],
[6]])]13.np.digitize(data,bins)
作用:根据bins的分箱区间,将data与bins中的区间对比,返回data在bins中索引,常用于机器学习
参数解析:
data:输入的数据
bins:分箱区间,一维数组
np.random.seed(0)
bins = np.linspace(-3, 3, 11)
which_bin = np.digitize(data, bins=bins)
print(bins)
print(which_bin)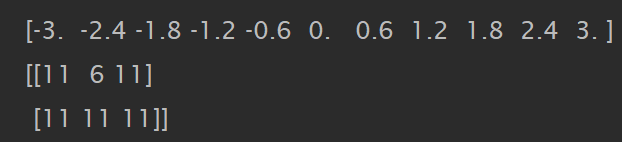
14.numpy.random.normal(loc=0.0,scale=1.0, size=None)
作用:生成高斯分布(正太)样本
15.np.exp(x)
作用:e的x次方
16.random.poisson(lam=1.0,size=None)
作用:从泊松分布绘制样本
参数解析:
lam:float,间隔期望
size:int 或者 tuple
17.np.argmin()
np.argmin()函数用于返回一维列表最小值索引或多维列表展平之后的最小值索引
即找到最小值的索引;同理可得获得最大值的索引:np.argmax()
np.random.seed(0)
data = np.random.randint(0, 15, 10)
print(data)
print(np.argmin(data))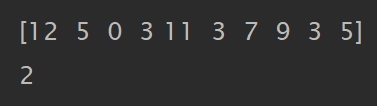
在此不在赘述np.argmax的使用方法
18.np.iinfo()
作用:查看每一个int型子类型的最值
np.iinfo(np.int16) # 查看每一个int型子类型的最小值和最大值
# 输出结果为:iinfo(min=-32768, max=32767, dtype=int16)19.np.inf()
np.inf 表示+∞,是没有确切的数值的,类型为浮点型
20.np.c_/np.r_
简单的合并方法,具体结果参照以下程序示例
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[7, 8, 9], [4, 5, 6]])
print(a)
print(b)
print(np.r_[a, b])
print(np.c_[a, b])
# [[1 2 3]
[4 5 6]]
[[7 8 9]
[4 5 6]]
[[1 2 3]
[4 5 6]
[7 8 9]
[4 5 6]]
[[1 2 3 7 8 9]
[4 5 6 4 5 6]]
21.np.sum(a,axis=1, keepdims=True)
作用:求和数组
参数解析:
a:待求和数组
axis:以数轴为基准,同行相加
keepdims:主要保持矩阵的二维特性
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a)
print(np.sum(a))
#结果如下所示
[[1 2 3]
[4 5 6]]
21
#设置参数axis=1
print(np.sum(a,axis=1))
#结果如下所示
[ 6 15]22.np.fill_diagonal
作用:设置对角线上的元素为自己的设定值
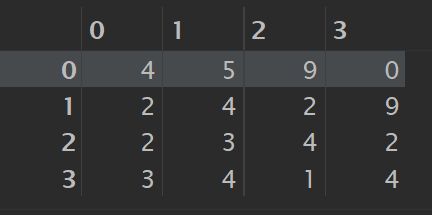
a = np.random.randint(0, 10, size=(4, 4))
np.fill_diagonal(a, 4)
a
# 结果如下
23.np.transpose(matrix)
作用:转置矩阵
通过如下代码做对比,即可了解该函数的使用方法
np.random.seed(0)
a = np.random.randint(0, 10, size=(4, 4))
print(a, '\n')
print(np.transpose(a))
#结果如下
[[5 0 3 3]
[7 9 3 5]
[2 4 7 6]
[8 8 1 6]]
[[5 7 2 8]
[0 9 4 8]
[3 3 7 1]
[3 5 6 6]]24.np.tile()
作用:实现数据重复
a = np.arange(5)
print("原始数组:\n",a)
b = np.tile(a, 3)
print("重复数据处理:\n", b)
# 结果如下
原始数组:
[0 1 2 3 4]
重复数据处理:
[0 1 2 3 4 0 1 2 3 4 0 1 2 3 4]25.np.repeat(repeats,axis)
作用:实现数据重复
参数解析:
repeats:重复次数
axis:沿着x轴或者y轴重复
np.random.seed(0)
a = np.random.randint(0, 10, size=(2, 2))
print(a)
print("重复数据处理:", a.repeat(2, axis=1))
# 结果如下
[[5 0]
[3 3]]
重复数据处理: [[5 5 0 0]
[3 3 3 3]]26.np.random.normal((x, y))
作用:生成正态分布的随机数
(使用方法较为简单,再次不在赘述)
27.np.eye(N)
作用:创建一个N维单位矩阵
np.eye(3)
# 结果如下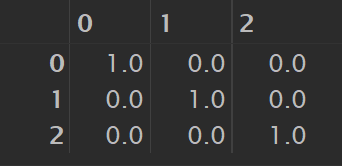
28.np.full(参数1:指定数组形状,参数2:指定数组数值)
np.full(shape=5, fill_value=5)
29.np.sort(array, axis)
作用:对数组进行排序,返回排序好的数组
参数解析:
array:待排序数组
axis:可以设置按照x或者y轴进行排序
np.random.seed(0)
a = np.random.randint(0, 10, size=(3, 4))
print(a)
print(np.sort(a))
# 结果如下
[[5 0 3 3]
[7 9 3 5]
[2 4 7 6]]
[[0 3 3 5]
[3 5 7 9]
[2 4 6 7]]30.np.partition(array,k)
作用:寻找数组中的第K小的数,同时也适用于二维数组(设置axis即可使用)
返回一个数组的分区副本。
创建一个数组的副本,其中元素重新排列,使第k个位置的元素的值处于它在排序数组中的位置。所有小于第k个元素的元素被移动到该元素之前,所有等于或大于该元素的元素被移动到该元素之后。两个分区中元素的顺序是未定义的
np.random.seed(0)
a = np.random.randint(0, 10, 10)
print(a)
print(np.partition(a, 5))
# 结果如下
[5 0 3 3 7 9 3 5 2 4]
[0 2 3 3 3 4 5 5 9 7]31.np.nan()
作用:numpy中的缺失值标签
NaN是一种特殊的浮点数,不是整数、字符串以及其他类型的数据
可以看作是一个数据病毒,任何数与之计算都会被同化为nan
32.特殊累计函数
np.nansum(), np.nanmin(), np.nanmax()可以忽略缺失值的影响
使用方法较为简单,与以上函数使用雷同,因此不再赘述。