ADNet学习笔记
Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning学习笔记
1.基本原理
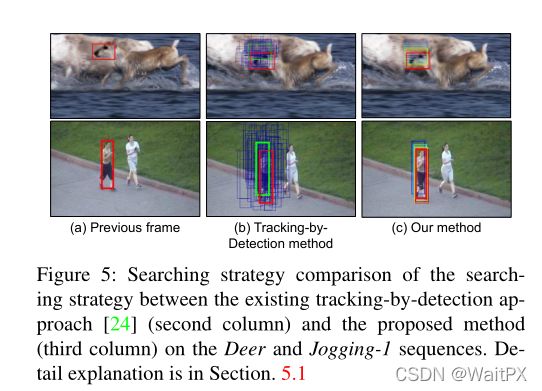
本文模型叫做ADNet。该模型通过强化学习产生动作序列(对bbox进行移动或者尺度变换)来进行跟踪。原理如下图(第一列代表初始帧,第二列和第三列代表通过RL产生的动作序列对object进行tracking):

2.算法详解
2.1 网络结构

ADNet是通过监督学习和强化学习来进行预训练,并在实际跟踪过程中使用在线自适应。
2.2 强化学习部分
(1)状态
状态 s t s_t st分为 p t 和 d t p_t和d_t pt和dt两部分。其中 p t p_t pt代表正在跟踪bbox(当前图片信息), d t d_t dt则是一个11×10=110维的向量,存储的是前10个动作,11代表的是11种不同的动作,使用独热编码表示。
(2)动作
动作分为3类共11种。第一类是move,包括上下左右和快速上下左右;第二类是scale,包括放大和缩小;第三类是stop,即终止操作。

(3)状态转移
离散的运动量定义如下:
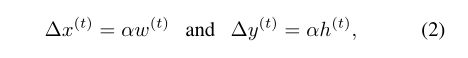
在实验中 α = 0.03 \alpha=0.03 α=0.03。
对于上下左右action(以此类推):

对于快速上下左右action(以此类推):
![]()
对于尺度变换action(以此类推):
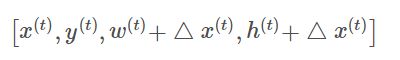
(4)奖励函数
假设action sequence的长度为T,则reward定义如下(即:中间的那些action都不产生reward,只有动作终止了才有reward):

动作的终止有两种触发情况:①.选择了stop action;②.action sequence产生了波动(eg: {left, right, left})。
2.3 ADNet的训练部分
2.3.1 基于监督学习的ADNet训练
每个训练样本中包含图像块 p j p_j pj,动作标签 o j a c t o_j^{act} ojact和类别标签 o j c l s o_j^{cls} ojcls,其中图像块 p j p_j pj是在真实图像块上加入高斯噪声得到,动作标签 o j a c t o_j^{act} ojact是通过下式得到:
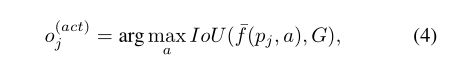
f ‾ ( p j , a ) \overline f(p_j,a) f(pj,a)指的是在原图像块 p j p_j pj上执行动作a后得到一个新的图像块。
类别标签通过下式得到:
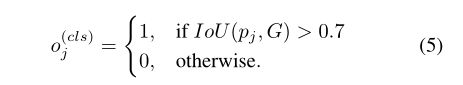
损失函数如下式所示:

2.3.2 基于强化学习的ADNet训练
在监督学习中,网络参数都会被训练,而在强化学习中,fc7层的参数是不会被训练的,首先我们随机挑选一些随机序列 ( F l ) l = 1 L (F_l)_{l=1}^L (Fl)l=1L和对应的ground truth ( G l ) l = 1 L (G_l)_{l=1}^L (Gl)l=1L,强化学习中执行一次跟踪模拟会产生一系列连续状态 s t , l s_{t,l} st,l、对应的动作 a t , l a_{t,l} at,l和奖励 r ( s t , l ) r(s_{t,l}) r(st,l),动作 a t , l a_{t,l} at,l由下式求得:
![]()
跟踪分数 z t , l = r ( s T l , l , ) z_{t,l}=r(s_{T_l,l},) zt,l=r(sTl,l,),每一帧中的每一个step的跟踪分数都是相同的。
由于采用的策略梯度来训练网络,给出改进的策略梯度如下式所示,
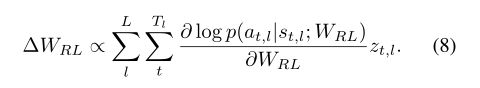
作者提到这部分训练可以采用半监督训练,由于未标记序列的跟踪分数无法确定,作者采用如下图所示的方式来获取未标记序列的跟踪分数,

上图的3帧都是标记的,从160帧处使用本文的方法做跟踪模拟,将190帧处的跟踪分数分别赋予160-190之间所有的未标记序列。
2.3.3 在线自适应跟踪
在线更新的时候,由于卷积层中具有通用的跟踪信息,而全连接层中具有特定于视频的真实,因此固定 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3层的参数,对 w 4 , . . . , w 7 w_4,...,w_7 w4,...,w7层的参数进行微调。文中将网络预测的的图像块作为ground truth,然后采用和监督训练相仿的方式进行训练,区别的是它每过I帧使用前面J帧中置信分数大于0.5的样本进行微调。
如果当前的置信分数小于-0.5,说明“跟丢了”,需要进行re-detection。然而re-detection后的目标位置是从带有高斯噪声的当前位置组成的候选目标位置集合中选取最高置信度的目标位置,公式如下所示:
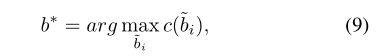
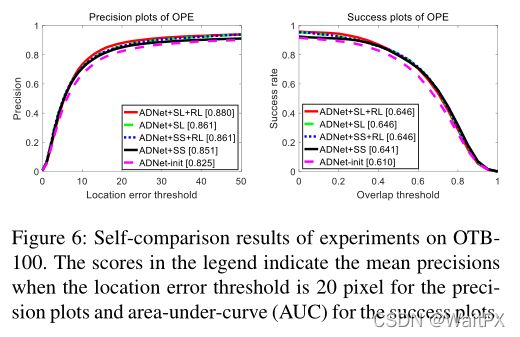
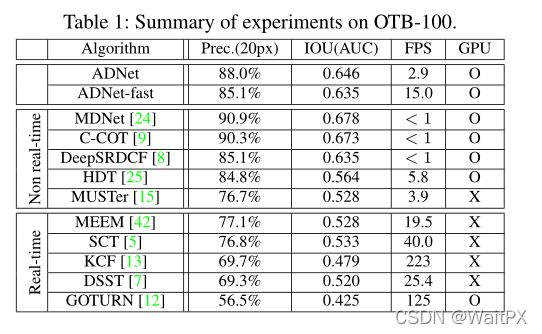
3.实验结果