图像分割的笔记
黄沛鑫的记录
-
- 什么叫output stride
- 什么叫Feature Map
- 关于DEEPLABV3+中inplanes和in channel 的区别
-
- 附torch.nn.Conv2d:
- 关于DEEPLABV3+中空洞卷积的膨胀率设置问题
- 关于DeeplabV3+的几种改进方法
-
- 1. 改进DeeplabV3+的火焰分割与火情分析方法 (doi:10.19665/j.issnl001-2400.2021.05.006)
- 2. 改进DeepLabv3+和XGBoost的羊骨架切割方法(doi:10.3778/j.issn.1002-8331.2005-0438)
-
-
- - TRICK1 : 为了使得特征提取网络满足羊骨架特征部位分割的需求,本研究对 ResNet 的 Conv4_x 模块分别增加、减少 6 层和 12 层,得到 ResNet-89、95、107 和 113,其结构分别如图所示
- - TRICK 2 :
-
- 3. 改进DeepLabv3+网络的肠道息肉分割方法(doi: 10.3778/j.issn.1673-9418.1907053 )
-
-
- - TRICK1:
- - TRICK2:
-
- 4. 采用双注意力机制Deeplabv3+算法的遥感影像语义分割(DOI:10.13284/j.cnki.rddl.003229)
- 5. 基于DeepLabv3+网络的电流互感器红外图像分割方法
-
-
- - TRICK
-
- 6. 基于 DeepLabV3+与超像素优化的语义分割
-
-
- - TRICK:
-
- 7. 基于MobileNetV2优化的DeeplabV3 + 目像分割方法研究
- 8. 基于改进 DeepLabv3+的无人车夜间红外图像语义分割
-
-
- - TRICK:
-
- 9. 基于改进 Deeplabv3 + 网络的线缆表面缺陷检测研究
什么叫output stride
input stride为我们正常进行卷积时候设置的stride值,
output stride为该矩阵经过多次卷积pooling操作后,尺寸缩小的值
例如:
input image为224 * 224,经过多次卷积pooling操作后,feature map为7*7,那么output stride为224/7 = 32.
什么叫Feature Map
在CNN的设定里,Feature Map是卷积核卷出来的,你用各种情况下的卷积核去乘以原图,会得到各种各样的feature map。
关于DEEPLABV3+中inplanes和in channel 的区别
在文件.\DeepLabV3Plus-Pytorch-origin\network\modeling.py中的一些函数有使用.\DeepLabV3Plus-Pytorch-origin\network\_deeplab.py 中的函数DeepLabHeadV3Plus,给入的参数的参数名有点改变,inplanes也就是in channel ,属于torch.nn.Conv2d的一个参数
附torch.nn.Conv2d:
def __init__(self,
in_channels: int, # 输入图像的通道数
out_channels: int, # 经过卷积后,输出特征映射的数量
kernel_size: Union[int, tuple[int, int]], # 卷积核大小
stride: Union[int, tuple[int, int]] = 1, # 做卷积时的步长
padding: Union[str, int, tuple[int, int]] = 0, # 填充大小,当是膨胀卷积时才不为0
dilation: Union[int, tuple[int, int]] = 1, # 卷积核之间的步幅,当是膨胀卷积时才不为1
groups: int = 1,
bias: bool = True,# 偏置,即可理解为y = kx+b中的b,当是膨胀卷积时为False
padding_mode: str = 'zeros', # 填充方式,一般就填0
device: Any = None,
dtype: Any = None) -> None
关于DEEPLABV3+中空洞卷积的膨胀率设置问题
在文件.\DeepLabV3Plus-Pytorch-origin\network\_deeplab.py 中的DeepLabHeadV3Plus类中,初始化参数aspp_dilate为[12, 24, 36],论文中所提到的空洞卷积膨胀率rate分别是6,12,18。经过探查,.\DeepLabV3Plus-Pytorch-origin\network\modeling.py中的函数有写到:
if output_stride == 8:
aspp_dilate = [12, 24, 36] # 代码作者另行给的值
else:
aspp_dilate = [6, 12, 18] # 论文的参数
如此便可知道,aspp_dilate在两种情况下:
.\DeepLabV3Plus-Pytorch-origin\network\modeling.py中的对于不同的backbone架构有着不同的默认output_stride,Deeplab V3+中,使用hrnetv2_48,hrnetv2_32时output stride为4,resnet50,resnet101,mobilenet的output stride为8
关于DeeplabV3+的几种改进方法
1. 改进DeeplabV3+的火焰分割与火情分析方法 (doi:10.19665/j.issnl001-2400.2021.05.006)
在原DeeplabV3-I-分割网络基础上,增加了高低层特征的融合信息,并采用两倍上采样逐步恢复图像尺寸,实现更为准确的火焰分割。
原DeeplabV3+网络就使用输出尺寸为原图像1/4大小的低层特征和编码器输出的高层特征相融合,再直接4倍上采样恢复到原始尺寸,得到最终的密集预测。但对于边缘非常不规则且尺度变化大的火焰目标,仅单次融合没有充分利用其他低层分支的有效信息,得到的分割边界较为粗糙。
针对上述问题,笔者借鉴FPN多尺度目标检测网络的思想,考虑对编码器所有尺度的输出特征图都进行融合,使低层的细粒度特征能够与高层的语义特征充分融合,保留更加丰富的边缘信息。首先,为了融合不同尺度上的特征,将原网络中的上采样倍数从4倍改为2倍,通过4次的2倍上采样来逐步恢复空问尺度,减少网络逐层的信息丢失,并形成解码器中“自上而下”的路径来对应编码器中“自下而上”路径,以便后续进行特征融合。其次,特征融合的方式目前广泛使用的有add和concat,区别在于 add融合方式是对每一维下的信息进行叠加,而concat是通道的叠加,即特征维度的增加。需要注意的是,以add方式进行特征融合时,两个特征的维度必须保持一致,即add方式认为叠加的各个特征贡献度是相同的。但对火焰分割结果来说,其语义性更为重要,因此在融合过程中需要考虑到高低层特征融合时的权重问题。低层特征一般具有较多的通道数,如256个或512个,而高层特征输出通道数为256个。使用通道压缩是较好的做法,文献中也已说明48是较好的通道压缩数,将低层特征的通道数进行压缩,使高层特征通道数永远大于低层特征通道数,之后再使用concat方式进行通道叠加,可以大大减小网络的训练难度。网络的具体融合步骤如下:
- (1) 利用1×1卷积调整编码器的输出通道数为256。
- (2) 选择Resnet的Conv 2_x,Conv 3_x和Conv 4_x这3个卷积层的输出作为特征融合输入,通过1×1卷积将通道数压缩为48。
- (3) 与FPN网络中的横向连接类似,从编码器的输出高层特征开始,先采用2倍上采样并将其结果与Conv 4_x通道压缩结果进行concat,再应用3×3卷积来细化特征,重新将特征数调整为256并作为下次融合的输入,继续使用该操作向下融合Conv 3_x层和Conv 2_x层特征。
- (4) 最后的一次的融合结果再经过2倍上采样后调整输出特征的通道数为2,输出结果。
更改后的网络结构:

2. 改进DeepLabv3+和XGBoost的羊骨架切割方法(doi:10.3778/j.issn.1002-8331.2005-0438)
该方法通过研究DeepLabV3+网络架构,基于ResNet-101搭建了4种基础网络,通过调整空洞卷积的扩张率和引入可形变卷积核的方法设计改进了2种ASPP结构。
- TRICK1 : 为了使得特征提取网络满足羊骨架特征部位分割的需求,本研究对 ResNet 的 Conv4_x 模块分别增加、减少 6 层和 12 层,得到 ResNet-89、95、107 和 113,其结构分别如图所示
不同ResNet的Conv4_x结构:
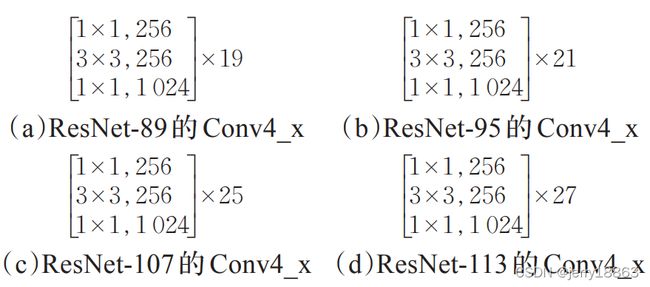
- TRICK 2 :
-ASPP模块有效提升了卷积核的感受野并提升了语义分割的精度,但较大的空洞扩张率也带来了信息丢失等问题。DeepLabv3+中的空洞扩张率分别为 1、6、12、18。
作者分别设置1、3、6、12和1、6、9、12两种尺度的扩张率
不同的ASPP结构:

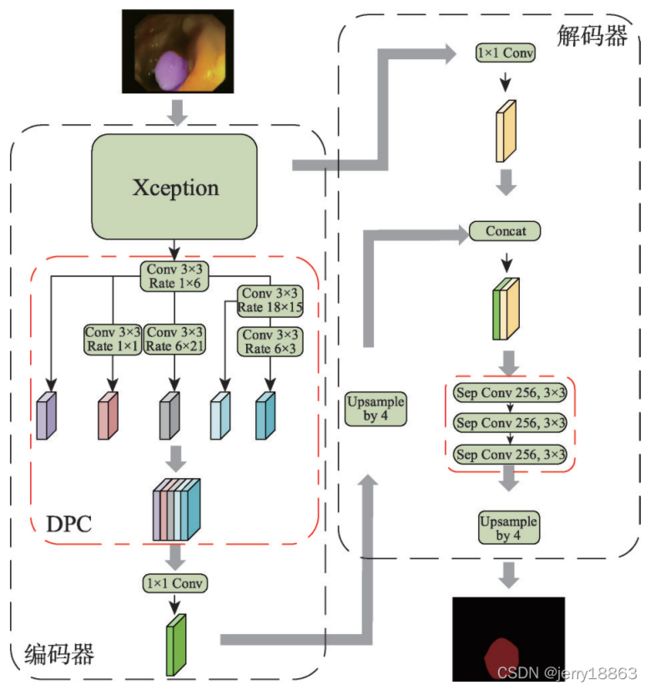
3. 改进DeepLabv3+网络的肠道息肉分割方法(doi: 10.3778/j.issn.1673-9418.1907053 )
- 在网络结构上,将通过神经架构搜索得到的最优密集预测单元引入DeepLabv3+网络,并在解码器部分采用3层深度可分离卷积逐步获取分割结果,减少分割过程中不完全分割的情况。
- TRICK1:
- 将基于神经架构搜索的密集预测单元引入 DeepLabv3+网络,在编码过程中通过最优DPC架构捕获多尺度特征信息;
作者搜索到的DPC架构为:
1 × 1卷积、采样率分别为 6 × 3、18 × 15、6 × 21、1 × 1、1 × 6 ,内核为 3 的卷积以及不同尺度的平均池化层。
- TRICK2:
- 在解码器中,将特征融合部分的 3 × 3 卷积改进为 3层深度可分离卷积,以实现对空间信息和深度信息的去耦,减少上采样过程中的信息丢失的问题。
本文在解码器部分采用 3 层深度可分离卷积对深度信息和空间信息去耦,以逐步获取精细的分割结果。深度可分离卷积将原始卷积在保持通道分离的情况下分为深度卷积和一个 1 × 1 的逐点卷积。深度卷积的一个卷积核只对一个通道操作,即每个通道独立进行卷积运算。逐点卷积将上一步得到的多个特征图在深度方向上加权组合。与传统卷积相比将深度信息和空间信息拆分处理,能够实现对空间信息和深度信息的去耦,有效减少上采样过程中的信息丢失。 - 改进的DeepLabv3+网络模型:
4. 采用双注意力机制Deeplabv3+算法的遥感影像语义分割(DOI:10.13284/j.cnki.rddl.003229)
- 在该网络中引入双注意力机制模块 (Dual Attention Mechanism Module,DAMM),设计并实现了将DAMM结构与ASPP (Atous Spatial Pyramid Pooling) 层串联或并联的2种不同连接方式网络模型 ,串联连接方式中先将特征图送入 DAMM 后,再经过 ASPP结构;并联连接方式中将双注意力机制层与 ASPP层并行连接,网络并行处理主干网提取特征图,再融合两层处理特征信息。
- 位置注意力模块
位置注意力模块能够模拟出丰富的全局特征间的上下文关系,从而使不同位置同类特征相互增强,提高语义分割能力,位置注意力模块结构如图所示。

- 通道注意力模块
语义分割模型提取的不同通道的高层语义特征图是某个特定类别的预测,且不同类别的语义之间具有特定的联系,通过利用不同通道特征图之间的相互联系,可以突出相互联系的特征图并且使特定的语义特征得到促进,因此探索不同通道的特征很有必要。通道注意力模块如图所示。
- 下图图为 DAMM 与 ASPP并联情况,使用主干网络先对图像进行特征提取,然后将模型分为2条支路网络分别对主干网提取的特征图进行处理,再将2条分路特征图融合。图中上支路是双注意力机制模块,由通道注意力模块和位置注意力模块组成,这2个模块在双注意力模块中并行操作,具体为:
首先,将骨干网提取所得特征图进行扩张率为 2 的3×3卷积操作,然后将其分别送入通道注意力模块和位置注意力模块中处理,并将处理特征图进行加操作。其中通道注意力模块利用不同通道的相关类别特征间的关联性进行不同类别特征强化,提升分类精度,位置注意力模块通过模拟出不同局部特征间的联系,可相互促进不同局部特征间的分类精度。图中下支路使用DeepLabv3+中ASPP操作,先将特征图送入ASPP处理,再将ASPP处理特征图与双注意力模块处理特征图融合,最终将融合特征图降维至256通道数。网络解码模块沿用DeepLabv3+解码模块操作,最终得出图像分割图。

下图为DAMM与ASPP串联情况,与并联不同,模型通过深度特征提取网络得到特征图后,先将特征图进行扩张率为 2的 3×3卷积操作,再将特征图送入 DAMM 中进行特征图的位置及通道间像素特征强化,然后将特征图输入ASPP模块中进行多尺度目标分割,最后按照原网络方法进行特征图的解码恢复工作。

5. 基于DeepLabv3+网络的电流互感器红外图像分割方法
对收集到的样本采用限制对比度自适应直方图均衡化方法实现图像轮廓增强
- TRICK
对于给定的输入图像,CLAHE算法将图像分割为互不重叠的图像块,对划分后的每一个子块计算其对应的直方图,使用预先设定的阈值三对每个子块直方图进行裁剪,同时统计整个直方图中超过上限阈值上的像素数,并将这些像素数重新分布到对应子块的直方图中。最后,通过使用双线性插值来消除边界伪影,在子矩阵上下文区域内实现像素的新灰度级分配的计算。
6. 基于 DeepLabV3+与超像素优化的语义分割
使用 SLIC 超像素分割算法将输入图像分割成超像素图像。
考虑到超像素具有可以保护物体边缘的特性 ,本文通过融合高层语义特征和超像素物体边缘信息来优化语义分割结果。
通常 ,超像素可以被认为是一组位置 、颜色 、纹理等相似的像素集合 。 本文使用 Achanta 等提出的 SLIC(Simple Linear Iterative Cluster )超像素分割算法[20]将输入图像分割成超像素图像 。首先 ,它将彩色图像转化为 CIE-Lab 颜色空间 ,对应每个像素的(L,a,b)颜色值和(x,y)坐标组成一个5维向量 ,然后对此构造距离度量标准 。最后通过迭代的方式对图像像素进行局部聚类 。其中,迭代计算聚类中心是本算法的关键 ,而迭代的核心就是计算距离 。
- TRICK:
首先得到由DeepLabV3+输出的粗糙语义分割结果,然后统计每个超像素内各语义类别所占像素总数,最后选择像素总数最多的语义类别并将其赋给该超像素 。具体算法如下:

7. 基于MobileNetV2优化的DeeplabV3 + 目像分割方法研究
垃圾文章,艹,换了个backbone也叫优化?qnm
8. 基于改进 DeepLabv3+的无人车夜间红外图像语义分割
该算法在 DeepLabv3+网络的基础上,通过引入密集连接的空洞卷积空间金字塔模块,使网络生成的多尺度特征能覆盖更大的尺度范围
- TRICK:
本文以 DeepLabv3+网络结构为基础,通过密集连接的方式重构了网络 ASPP 模块,同时借鉴 U-Net 等经典 Encode-Decode 结构,将 Encode 模块的多层结果特征图拼接到 Decode 模块中。整体网络结构图如图所示。
改进 DeepLabv3+网络结构图:

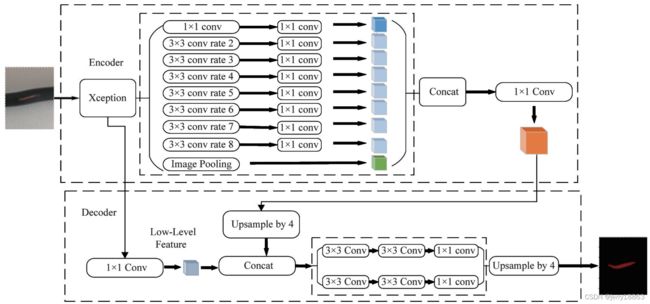
9. 基于改进 Deeplabv3 + 网络的线缆表面缺陷检测研究
将空间金字塔结构由 4 个空洞卷积改为 8 个空洞卷积并在其后增加 1 × 1 的卷积环节;同时在解码融合后用一个并联结构来减少整个网络传输过程的信息丢失
原网络:

改进的网络结构: