动手学强化学习第八章(DQN改进算法)
文章目录
-
-
- 第八章:DQN改进算法
-
- 1.理论部分
-
- 1.1 Double DQN
- 1.2 Dueling DQN
- 2.实践部分
-
第八章:DQN改进算法
文章转载自《动手学强化学习》https://hrl.boyuai.com/chapter/intro
1.理论部分
本部分主要是double DQN与Dueling DQN
1.1 Double DQN
回顾:
首先回顾一下普通的DQN是如何更新参数的
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ ∈ A Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a)+\alpha\left[r+\gamma \max _{a^{\prime} \in \mathcal{A}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right] Q(s,a)←Q(s,a)+α[r+γa′∈AmaxQ(s′,a′)−Q(s,a)]
我们的目标是使Q(s, a)接近
r + γ max a ′ ∈ A Q ( s ′ , a ′ ) r+\gamma \max _{a^{\prime} \in \mathcal{A}} Q\left(s^{\prime}, a^{\prime}\right) r+γa′∈AmaxQ(s′,a′)
于是我们可以如下定义我们的损失函数
ω ∗ = arg min ω 1 2 N ∑ i = 1 N [ Q ω ( s i , a i ) − ( r i + γ max a ′ Q ω ( s i ′ , a ′ ) ) ] 2 \omega^{*}=\arg \min _{\omega} \frac{1}{2 N} \sum_{i=1}^{N}\left[Q_{\omega}\left(s_{i}, a_{i}\right)-\left(r_{i}+\gamma \max _{a^{\prime}} Q_{\omega}\left(s_{i}^{\prime}, a^{\prime}\right)\right)\right]^{2} ω∗=argωmin2N1i=1∑N[Qω(si,ai)−(ri+γa′maxQω(si′,a′))]2
为了使得训练更加稳定,用上target network的话就是
1 2 [ Q ω ( s , a ) − ( r + γ max a ′ Q ω − ( s ′ , a ′ ) ) ] 2 \frac{1}{2}\left[Q_{\omega}(s, a)-\left(r+\gamma \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right)\right)\right]^{2} 21[Qω(s,a)−(r+γa′maxQω−(s′,a′))]2
也就是用训练网络估计t时刻的Q值,用目标网络估计t+1时刻的Q值。
本节内容:
原来得TD误差目标如下式:
r + γ max a ′ Q ω − ( s ′ , a ′ ) r+\gamma \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right) r+γa′maxQω−(s′,a′)
其中
max a ′ Q ω − ( s ′ , a ′ ) \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right) a′maxQω−(s′,a′)
还可以写成
Q ω − ( s ′ , arg max a ′ Q ω − ( s ′ , a ′ ) ) Q_{\omega^{-}}\left(s^{\prime}, \arg \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right)\right) Qω−(s′,arga′maxQω−(s′,a′))
也就是说选择最优动作和评估动作使用一个网络进行,考虑到通过神经网络估算的值本身在某些时候会产生正向或负向的误差,在 DQN 的更新方式下神经网络会将正向误差累积。由此出现高估的问题。
怎么解决呢?其他部分不变,在选择最优动作时用评估t时刻Q值的网络,也就是训练网络
Q ω Q_{\omega} Qω
因此对比DQN与Double DQN的话

1.2 Dueling DQN
(这部分不是很懂)
在Dueling DQN中Q的定义如下:
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) Q_{\eta, \alpha, \beta}(s, a)=V_{\eta, \alpha}(s)+A_{\eta, \beta}(s, a) Qη,α,β(s,a)=Vη,α(s)+Aη,β(s,a)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EXUdQKdU-1651300768360)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220430123537163.png)]](http://img.e-com-net.com/image/info8/d8cf8224592f4f56b55323f7c38e171d.jpg)
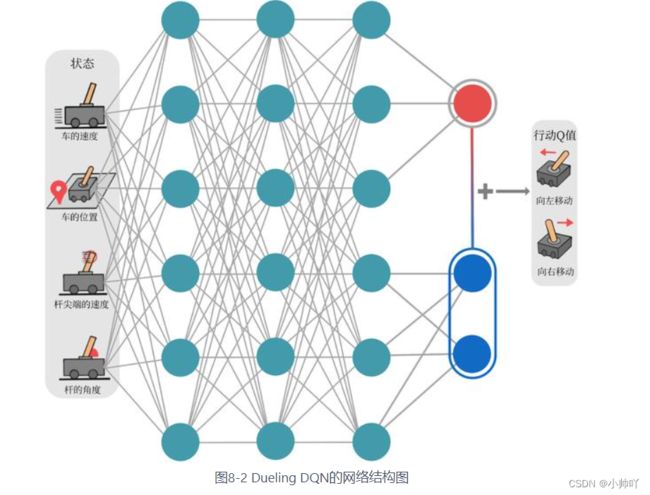
将状态价值函数和优势函数分别建模的好处在于:某些情境下智能体只会关注状态的价值,而并不关心不同动作导致的差异,此时将二者分开建模能够使智能体更好地处理与动作关联较小的状态。

为什么Dueling network比DQN好:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
这部分我记得李宏毅的课上讲的还不错,之后看一下再更新本部分
2.实践部分
import random
import gym
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
from tqdm import tqdm
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class DQN:
''' DQN算法,包括Double DQN '''
def __init__(self,
state_dim,
hidden_dim,
action_dim,
learning_rate,
gamma,
epsilon,
target_update,
device,
dqn_type='VanillaDQN'):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.dqn_type = dqn_type
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(1, max_action)
else: # DQN的情况
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
lr = 1e-2
lr = 1e-2
num_episodes = 200
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 50
buffer_size = 5000
minimal_size = 1000
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'Pendulum-v0'
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 11 # 将连续动作分成11个离散动作
def dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数
action_lowbound = env.action_space.low[0] # 连续动作的最小值
action_upbound = env.action_space.high[0] # 连续动作的最大值
return action_lowbound + (discrete_action /
(action_dim - 1)) * (action_upbound -
action_lowbound)
def train_DQN(agent, env, num_episodes, replay_buffer, minimal_size,
batch_size):
return_list = []
max_q_value_list = []
max_q_value = 0
for i in range(10):
with tqdm(total=int(num_episodes / 10),
desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
max_q_value = agent.max_q_value(
state) * 0.005 + max_q_value * 0.995 # 平滑处理
max_q_value_list.append(max_q_value) # 保存每个状态的最大Q值
action_continuous = dis_to_con(action, env,
agent.action_dim)
next_state, reward, done, _ = env.step([action_continuous])
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(
batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
return return_list, max_q_value_list
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device)
return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
replay_buffer, minimal_size,
batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
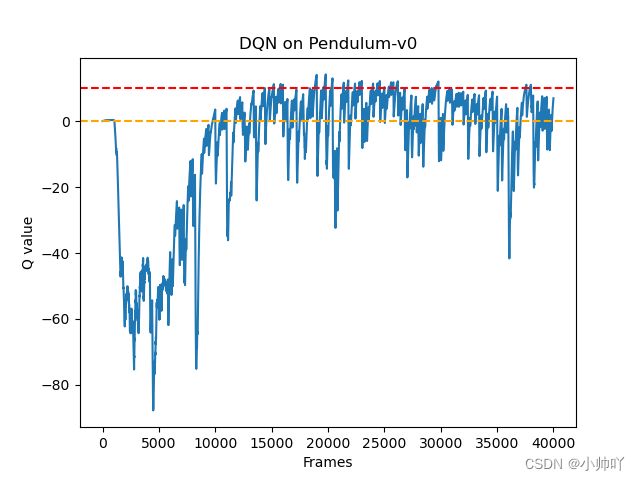
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('DQN on {}'.format(env_name))
plt.show()
#### Double DQN
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device, 'DoubleDQN')
return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
replay_buffer, minimal_size,
batch_size)
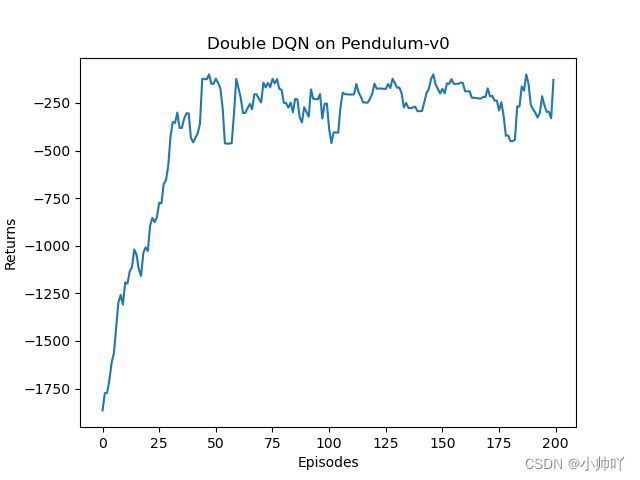
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
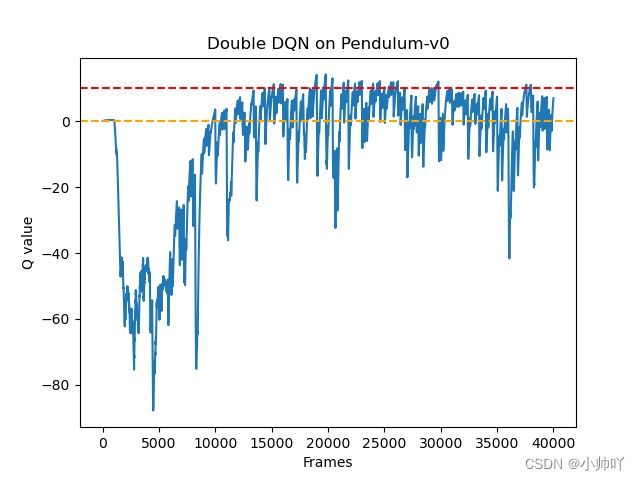
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
###### Dueiling DQN
class VAnet(torch.nn.Module):
''' 只有一层隐藏层的A网络和V网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(VAnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 共享网络部分
self.fc_A = torch.nn.Linear(hidden_dim, action_dim)
self.fc_V = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
A = self.fc_A(F.relu(self.fc1(x)))
V = self.fc_V(F.relu(self.fc1(x)))
Q = V + A - A.mean(1).view(-1, 1) # Q值由V值和A值计算得到
return Q
class DQN:
''' DQN算法,包括Double DQN和Dueling DQN '''
def __init__(self,
state_dim,
hidden_dim,
action_dim,
learning_rate,
gamma,
epsilon,
target_update,
device,
dqn_type='VanillaDQN'):
self.action_dim = action_dim
if dqn_type == 'DuelingDQN': # Dueling DQN采取不一样的网络框架
self.q_net = VAnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.target_q_net = VAnet(state_dim, hidden_dim,
self.action_dim).to(device)
else:
self.q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.dqn_type = dqn_type
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions)
if self.dqn_type == 'DoubleDQN':
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(
1, max_action)
else:
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))
self.optimizer.zero_grad()
dqn_loss.backward()
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.count += 1
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device, 'DuelingDQN')
return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
replay_buffer, minimal_size,
batch_size)
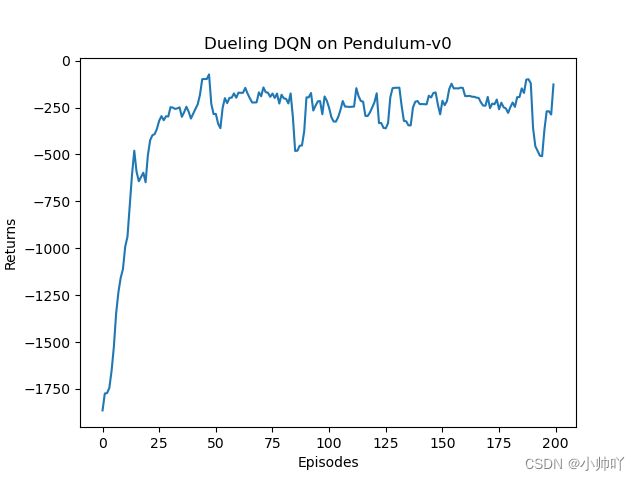
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Dueling DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Dueling DQN on {}'.format(env_name))
plt.show()