多层感知机预测算法—以二手车预测为例(MLP)
前言
MLP是一种人工神经网络(ANN)。最简单的MLP至少由三层节点组成:输入层,隐藏层和输出层。本文将通过构建二手车预测价格的方式,讨论scikit-learn和keras两种深度学习库搭建MLP预测模型的差别以及所展现的不同效果。
案例分析—基于二手车平台教育数据集
1. 数据预处理
该数据基于2022年MotherCup()(点击该文字可下载数据集)大数据竞赛提供的二手车交易样本数据集,里面包含内容36列变量信息,其中15列为匿名变量。我们首先加载数据集观察整个数据结构和详细的数据内容。数据集的包含内容附件一:评估训练数据集.txt和附件二:估价验证数据.txt。附件一共30000组交易数据,每辆车都有carid(车辆 id)、tradeTime(展销时间)、brand(品 第 4 页 共 32 页 牌 id)、serial(车系 id)、model(车型 id)、mileage(里程)、color(车辆颜色)、 cityId(车辆所在城市 id)、carCode(国标码)、transferCount(过户次数)、seatings (载客人数)、registerDate(注册日期)、licenseDate(上牌日期)、country(国别)、 maketype(厂商类型)、modelyear(年款)、displacement(排量)、gearbox(变速箱)、 oiltype(燃油类型)、newprice(新车价)、anonymousFeature1 至 anonymousFeature15 (匿名特征 1 至匿名特征 15)、price(二手车交易价格(预测目标))共 36列特征。该数据无重复值和异常值问题,存在一些特征的确实数量所以为减少数据浪费和结果偏差,需要对缺失 值进行填补,填补方法一般有固定值填充、均值填充、中位数填充、众数填充、多重插 补、随机插补和临近插补(前值插补、后值插补)等。缺失数据处理表如下图所示:


其中匿名特征11是由“数字 符号 数字”组成的特殊字符串,我们将其分为新的两组变量(使用方法与体积分离变量相似)。
2.特征挖掘与处理
首先对附件 1 和 2 数据集的特征进行挖掘,主要挖掘时间特征和特殊特征,由于所 给数据集大部分为分类特征,因此可以对相似特征进行融合,特征挖掘方法如下:
-
时间特征
1)将 tradeTime、registerDate、licenseDate、anonymousFeature7 数据类型转换为 datetime64[ns],产生新的 Feature:TransferAge(过户年长)。根据假设 4,不考虑具体 日 期 带 来 的 影 响 , 所 以 分 别 产 生 对 应 的 年 、 月 , 同 时 删 除 原Feature ; 将 anonymousFeature13 也拆分成年月,同时删除原 Feature;
∗ ∗ T r a n s f e r A g e = ( t r a d e T i m e − l i c e n s e D a t e ) / 3652 ) ∗ ∗ **TransferAge =(tradeTime -licenseDate)/365 2)** ∗∗TransferAge=(tradeTime−licenseDate)/3652)∗∗
2)将产生的时间特征与 price 进行相关分析,结果都小于 0.02,说明时间特征与 price 的相关性极低,因此,不保留时间特征数据。 -
特殊特征 将 anonymousFeature12 拆分 3 列,即 anonymousFeature12_1、anonymousFeature12_2 和 anonymousFeature12_3。
-
特征融合 将含义相近的特征融合,即将 brand(品牌 id)、carCode(国标码)、maketype(厂 商类型)融合成 brand_carCode_maketype 特征,将 serial(车系 id)、model(车型 id)、 modelyear(年款)融合成 serial_model_modelyear 特征,融合方法如下:
b r a n d c a r C o d e m a k e t y p e = b r a n d ∗ 100 + c a r C o d e ∗ 10 + m a k e t y p e brand_carCode_maketype = brand *100 + carCode*10 + maketype brandcarCodemaketype=brand∗100+carCode∗10+maketypes e r i a l m o d e l m o d e l y e a r = s e r i a l ∗ 10000000 + m o d e l ∗ 100 + ( m o d e l y e a r − 2000 ) serial_model_modelyear = serial*10000000 + model*100 + (modelyear- 2000) serialmodelmodelyear=serial∗10000000+model∗100+(modelyear−2000)
## 需要使用的库
## 基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
from tqdm import tqdm
import itertools
warnings.filterwarnings('ignore')
%matplotlib inline
## 模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
## 数据降维处理的
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
import scipy.signal as signal
train_data = pd.read_csv('估价训练数据.csv')
train_data.head()
train_data.columns
train_data.info()

根据数据和指标的含义可以了解到指标的结构特性为数值型的高基数分类变量,对于这类问题,引用了TargetEncoder(目标编码)方法对分类变量赋值然后再将其标准化。
#目标编码,te为编码后X
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from category_encoders.target_encoder import TargetEncoder
import numpy as np
import pandas as pd
X_encoder = train_data.drop(['carid', 'price'], axis=1)
y_encoder = train_data['carid']
enc = TargetEncoder(cols=[ 'color', 'cityId', 'transferCount', 'country', 'displacement', 'gearbox',
'oiltype' ])
te = enc.fit_transform(X_encoder, y_encoder)
此时我们展示编码后与编码前数据对比;

特征归一化:
from sklearn.preprocessing import MinMaxScaler
#特征归一化
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(pd.concat([te]).values)
all_data = min_max_scaler.transform(pd.concat([te]).values)
因为存在匿名变量,我们无法通过分析指标含义来确定它对价格的影响,可以使用主成分分析与灰色关联分析分析融合加权的定量模型方法对指标进行一个排序(不在此文过多叙述)。影响销售速度的影响因子综合得分表如下图所示;

根据两种方法计算出综合得分:
W = 0.463 x 1 + 0.461 x 2 + 0.377 x 3 + … … + 0.404 x 32 + 0.467 x 33 \mathrm{W}=0.463 x_{1}+0.461 x_{2}+0.377 x_{3}+\ldots \ldots+0.404 x_{32}+0.467 x_{33} W=0.463x1+0.461x2+0.377x3+……+0.404x32+0.467x33
为了尽可能保留数据集的原始信息,我们可以使用PCA保留20组件进行转化;
from sklearn.decomposition import PCA
from sklearn.decomposition import PCA as RandomizedPCA
pca = RandomizedPCA(20)
pca.fit(all_data)
X = all_data
y = train_data['price'] .values
可视化组件图;
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
import numpy as np
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance');

3. MLP预测二手车价格模型(with scikit-learn and )
为了展示模型的训练效果,使用了python的两种库进行模型构建,分别对处理好的数据进行训练。整个模型训练流程如下图所示;

3.1 Scikit-learn 中多层感知器(MLP)的特点
- 输出层没有激活函数。
- 对于回归场景,平方误差是损失函数,交叉熵是分类的损失函数
- 它可以与单个以及多个目标值回归一起使用。
- 与其他流行的软件包不同,像 Keras 一样,Scikit 中的 MLP 实现不支持 GPU。
- 我们无法为每一层微调参数,如不同的激活函数、权重初始化器等。
3.2 案例分析(scikit-learn)
在scikit-learn库种,MLPRegressor在神经网络模块中实现。我们需要执行的操作包括通过train_test_split拆分数据集为训练集和测试集。fetch_california_housing获取数据,以及StandardScaler将数据缩放为不同的特征(自变量)具有广泛的价值范围尺度(在上述代码已经实现)。缩放用于训练模型的数据非常重要。
在下面的代码中,将会对4个隐藏层进行建模,每层有分别有(1000,1000,300,100)。考虑到输入和输出层,我们在模型中总共有6层。使用默认Adam优化器,即随机梯度优化器更适用于较大数据集。其中优化器还包括{‘lbfgs:拟牛顿算法,’sgd‘:随机梯度下降,’adam‘:由 Kingma、Diederik 和 Jimmy Ba 提出的基于随机梯度的优化器}。对于小型数据集’lbfgs‘可以更快地收敛并表现良好。因为预测算法激活函数选择了relu。拟合数据进行输出,观察
# # 6.MLP导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.font_manager import FontProperties
fonts = FontProperties(fname = "/Library/Fonts/华文细黑.ttf",size=14)
from sklearn import metrics
from sklearn.model_selection import train_test_split
## 忽略提醒
import warnings
warnings.filterwarnings("ignore")
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
#PCA
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.decomposition import PCA as RandomizedPCA
## 定义含有4个隐藏层的MLP网络
mlpr = MLPRegressor(hidden_layer_sizes=(1000,1000,300,100), ## 隐藏层的神经元个数
activation='relu',
solver='adam',
alpha=0.0001, ## L2惩罚参数
max_iter=100,
random_state=123,
# early_stopping=True, ## 是否提前停止训练
# validation_fraction=0.2, ## 20%作为验证集
# tol=1e-8,
)
## 拟合训练数据集
mlpr.fit(X_train,y_train)
## 可视化损失函数
plt.figure()
plt.plot(mlpr.loss_curve_)
plt.xlabel("iters")
plt.ylabel(mlpr.loss)
plt.show()

计算相对误差,在测试集上进行预测;
## 对测试集上进行预测
pre_y_mlp = mlpr.predict(X_test)
print("mean absolute error:", metrics.mean_absolute_error(y_test,pre_y_mlp))
print("mean squared error:", metrics.mean_squared_error(y_test,pre_y_mlp))
## 输出在测试集上的R^2
print("在训练集上的R^2:",mlpr.score(X_train,y_train))
print("在测试集上的R^2:",mlpr.score(X_test,y_test))
3.3 基于keras的MLP预测
本设计使用keras搭建神经网络模型方法是对Sequential类使用model.add()添加层对象。
#基于keras的MLP分析
from keras.models import Sequential
from keras.layers import Dense,Dropout
model = Sequential()
model.add(Dense(units=1000, input_dim=X_train.shape[1],
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=1000,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=300,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=300,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=100,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=1,
kernel_initializer='uniform',
activation='linear'))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
model.summary()
网络结构如下所示;
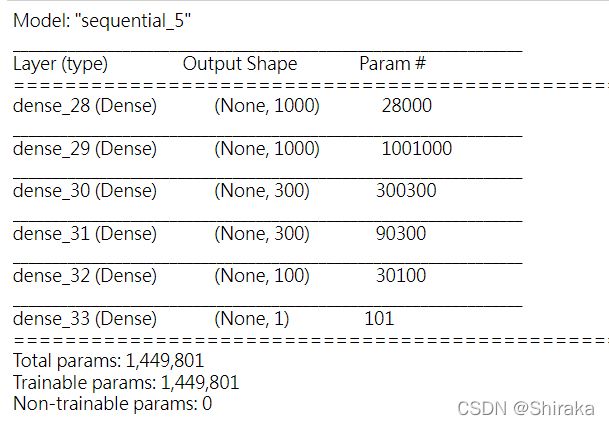
网络最后一层只有一个单元,没有激活,是一个线性层。这是标量回归(标量回归是预测单一连续值的回归)的典型设置。添加激活函数将会限制输出范围。最后一层设置纯线性,所以网络可以学会预测任意范围内的值。注意,编译网络使用的mse损失函数,即均方误差(MSE,mean squared error),预测值与 目标值之差的平方。这是回归问题常用的损失函数。 在训练过程中还监控一个新指标:平均绝对误差(MAE,mean absolute error)。它是预测值 与目标值之差的绝对值。
因为数据量共三万条,变量多为高维分类变量,难以估计验证分数的波动。最佳的使用方法是使用K折交叉验证这种方法将可用数据划分为 K 个分区(K 通常取 4 或 5),实例化 K 个相同的模型,将每个模型在 **K-1 **个分区上训练,并在剩下的一个分区上进行评估。模型的验证分数等于 K 个验证分数的平均值。实现代码如下;
# k折验证
k = 4
num_val_samples = len(X_train) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = X_train[i * num_val_samples: (i + 1) * num_val_samples] # 准备验证数据:第k个分区的数据
val_targets = y_train[i * num_val_samples:(i + 1) * num_val_samples]
# 准备训练数据:其他所有分区的数据
partial_train_data = np.concatenate(
[X_train[:i * num_val_samples],
X_train[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[y_train[:i * num_val_samples],
y_train[(i + 1) * num_val_samples:]],
axis=0)
model = model
model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=1,
verbose=0) # 训练模型(静默模式,vervose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0) # 在验证数据上评估模型
all_scores.append(val_mae)
print(np.mean(all_scores))
# 保存每折的验证结果
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = X_train[i * num_val_samples: (i + 1) * num_val_samples] # 准备验证数据:第k个分区的数据
val_targets = y_train[i * num_val_samples:(i + 1) * num_val_samples]
# 准备训练数据:其他所有分区的数据
partial_train_data = np.concatenate(
[X_train[:i * num_val_samples],
X_train[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[y_train[:i * num_val_samples],
y_train[(i + 1) * num_val_samples:]],
axis=0)
model = model
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
# 绘制验证分数(验证)
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
完成模型调参,我们可以使用最佳参数在所有训练数据上训练最终的生产模型,然后观察模型在测试集上的性能。
from keras.callbacks import EarlyStopping
## 提前停止条件
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
model.compile(loss='mean_squared_error', optimizer='adam')
model_fit = model.fit(X_train, y_train,batch_size=16,
epochs=200, verbose=0,
validation_split=0.2,
callbacks=[early_stopping])
3.4 结果分析
采用 MLP 回归分析模型时,使用 sklearn 构建网络时,其平均绝对误差约为 11.072, 均方误差约为 340.721;使用 Keras 搭建网络时,使用 **sklearn **构建网络时,其平均绝对 误差约为 5.041,均方误差约为 157.275。
经过对比,二手车价格预测模型最终采用 Keras 搭建网络的 7 层 MLP 回归分析模 型,训练附件 1 的二手车数据集进行预测,可知二手车预测的价格还是和实际价格相差 约 5041 元。
参考文献
- scikit-learn官方教程
- Deep Neural Multilayer Perceptron (MLP) with Scikit-learn
- MothorCup大数据竞赛
推荐阅读
-
微分算子法
-
使用PyTorch构建神经网络模型进行手写识别
-
使用PyTorch构建神经网络模型以及反向传播计算
-
如何优化模型参数,集成模型
-
TORCHVISION目标检测微调教程
-
神经网络开发食谱
-
主成分分析(PCA)方法步骤以及代码详解
-
神经网络编码分类变量—categorical_embdedder