《Focal and Global Knowledge Distillation for Detector》论文解读
论文地址:
Focal and Global Knowledge Distillation for Detectors
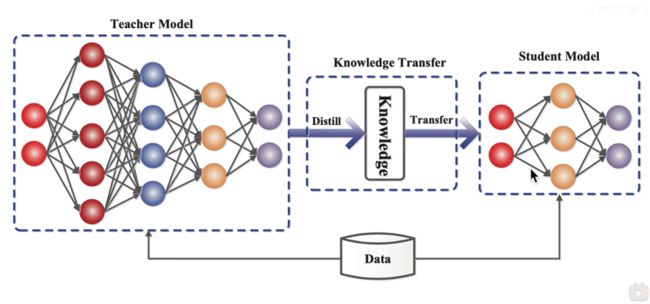
一、什么是知识蒸馏
首次提出知识蒸馏的概念由Hinton于2015年提出:
知识蒸馏开山之作
中文知识蒸馏研究综述:
知识蒸馏研究综述
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
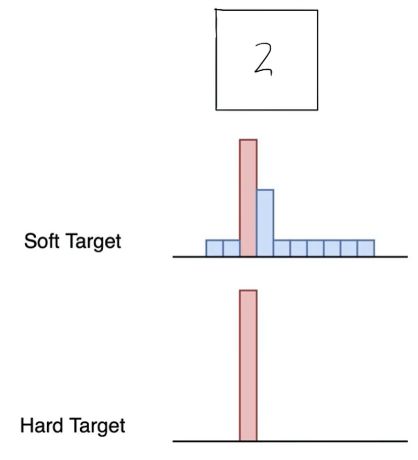
- 软硬标签
| 类别 |
Soft Target |
Hard Target |
| 马 |
0.7 |
1 |
| 狗 |
0.05 |
0 |
| 驴 |
0.1 |
0 |
| 牛 |
0.1 |
0 |
| 汽车 |
0.05 |
0 |
传统目标检测训练任务,通过Hard targets的标签进行训练,之后将图片出入模型进行识别,可以得到一个Soft Target。从上图可以看出,Soft Target比Hard Target传递出更多的信息,因此可以通过Soft Target作为学生模型的输入进行训练。
- 蒸馏温度T
Soft Target的输出还不足够“Soft“,因此在对其进行处理,新增一个蒸馏温度T,T使用在softmax函数中,修正输出标签的soft度,公式如下:
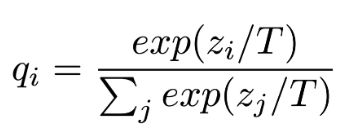
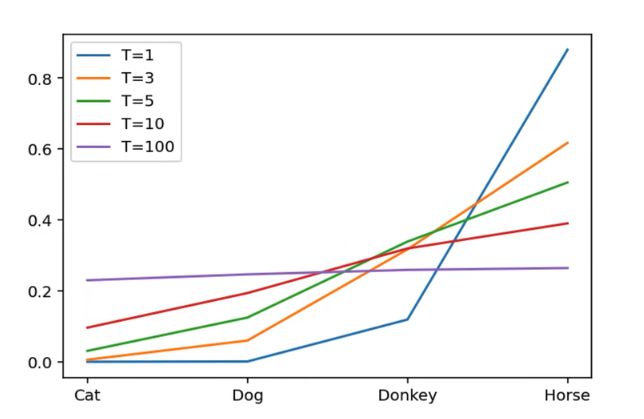
随T变化各概率分布如下,当T变大,每个分类所获得的相似度就越平均(越soft),太大的话每个分类的相似度就会相同,越小会发现每个类别的差异会很大。
T的变化程度决定了学生模型关注负类别的程度,当温度很低时,模型就不会太关注负类别,特别是那些小于均值的负类别。当温度很高时,模型就会更多的关注负类别。
在训练时,从有部分信息量的负样本中学习,则温度设定高些。
防止受负样本中标签噪声的影响,温度设定低些。
- 蒸馏过程
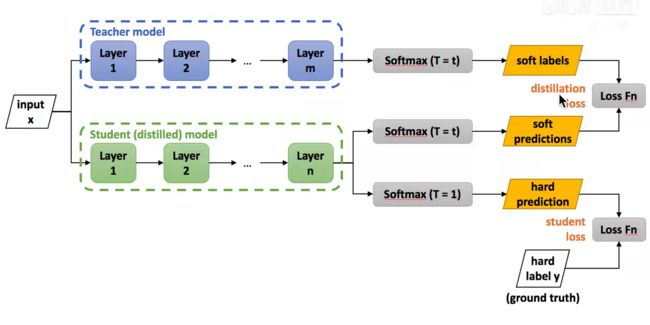
- 训练老师模型
- 使用较高的温度去构建Soft Labels
- 同时使用较高的Soft Labels和T=1的Soft Labels去训练学生模型
- 把T改为1在学生模型上做预估
损失函数:
disiliation loss(soft)和student loss(hard)的加权求和
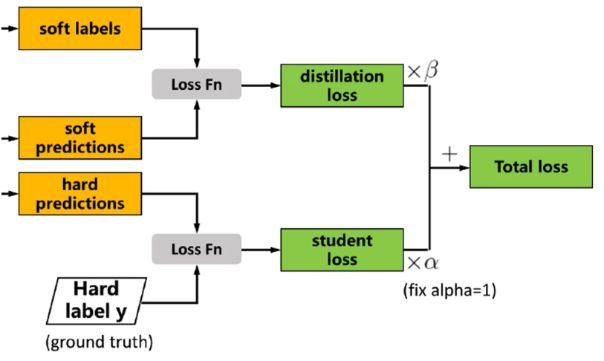
总损失:

soft Loss:

hard Loss:
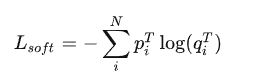
其中:
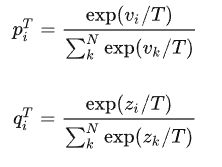
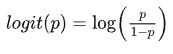
piT 指Teacher模型在温度等于T的条件下softmax输出在第 i 类上的值。qiT 指Student的在温度等于T的条件下softmax输出在第 i 类上的值。vi指Teacher模型的logits, zi 指Student模型的logits, N 指总标签数量。
二、目标检测知识蒸馏的难点
1. 前背景的不平衡对于目标检测而言是一个重要的问题,这个问题同样影响着知识蒸馏。
2. 不同像素之间的关系难以提取。
3. 目标检测相比于图像分类的复杂性使得大部分蒸馏都失败。
三、本论文主要思想
- 提出重点蒸馏区分像素和通道注意力。
- 提出全局蒸馏,弥补重点蒸馏的全局信息丢失。
四、论文介绍
针对前背景不平衡的问题,在空间和通道注意力上对教师网络和学生网络进行特征的可视化,其中在空间注意力上,二者在前景中的差异较大,在背景中的差异较小。这对蒸馏中的学生模型带来不同的学习难度。因此,本文选择分离出前背景进行蒸馏实验,发现当全图特征混在一起蒸馏时,为学生模型带来的提升最小,而将前景与背景分开,赋予不同的权重时,学生模型能够获得更好的表现。
针对上述结论,本文首先提出了“重点蒸馏(Focal Distillation)”:分离前背景,赋予不同的权重,并利用教师的空间与通道注意力作为权重,共同指导学生模型进行学习,计算重点蒸馏损失。由于重点蒸馏将前景与背景分开进行蒸馏,切断了前背景的联系,为此,团队提出了“全局蒸馏(Global Distillation)”解决方案:利用全局语义信息模块(Global Context Block,GcBlock)分别提取学生与教师的全局信息,并计算全局蒸馏损失。结合二者,团队最终提出了“重点与全局知识蒸馏(Focal and Global Distillation,FGD)。
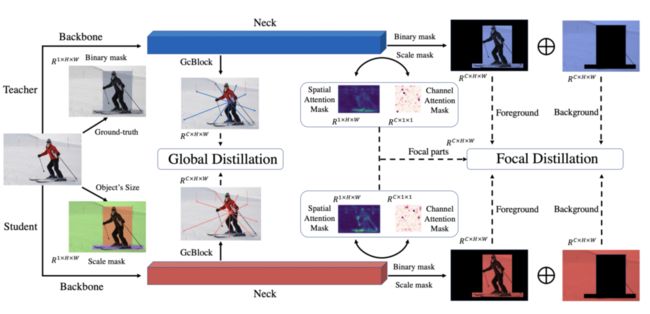
- 重点蒸馏(Focal Distillation)
由于前背景之间的不均衡,提出重点蒸馏来分类图像并引导学生聚焦于关键像素和通道。
1.1 二进制掩码——用以区分前景和背景

通过二进制掩码将图片的前景信息和背景信息进行分离,其中,r为ground truth,i,j分别表示了特征图的水平和垂直坐标。如果(i,j)落在ground truth中,否则为0。
1.2 尺度掩码S——用以均衡背景和归一化
由于较大尺度的目标由于像素较多,会造成较大的损失,从而影响小目标的蒸馏。在不同的图像中,前景和背景的比例差异很大。因此,为了平等对待不同的目标,平衡前景和背景的损失,设置一个尺度mask S:
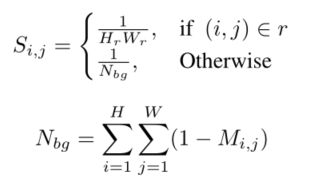
其中 Hr 和 Wr 表示 gt 框r的高和宽。如果一个像素属于不同目标,则选择最小的框作为gt。
1.3 空间和通道attention掩码AS和AC——用以区分关键像素和通道
通过借鉴SENet和CBAM的结论,关注关键像素和通道有助于基于CNN的模型获得更好的结果。在本文中,应用类似的方法来选择局部像素和通道,然后得到相应的注意力mask。分别计算不同像素和不同通道的绝对平均值:
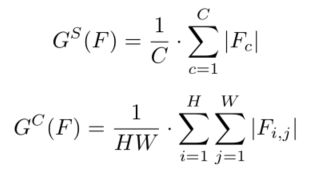
其中H、W、C表示特征的高度、宽度和通道。Gs和Gc是空间和通道注意力图。然后注意力mask可以被描述为:
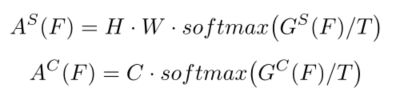
其中T是温度超参用于调整分布。
1.4 最终损失函数
学生和老师的mask之间存在显著差异。在训练过程中,采用教师的masks来指导学生。基于上述所得,计算重点损失的特征损失函数:
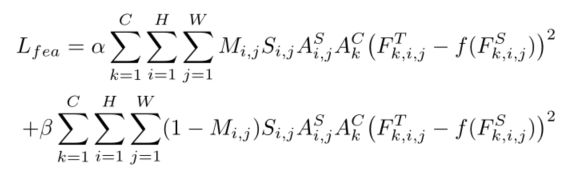
式中,As和Ac分别表示教师检测器的空间注意力mask和通道注意力mask。Ft和Fs分别表示教师检测器和学生检测器的特征图。α和β是平衡前景和背景之间损失的超参数。
此外,本文还使用注意力损失Lat来强制学生检测器模仿教师检测器的空间和通道注意力mask:
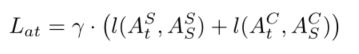
其中,t和s表示老师和学生,l()表示L1loss,γ是平衡loss的超参数。
最终重点损失如下:
![]()
- 全局蒸馏(Global Distillation)
在重点蒸馏中,通过局部蒸馏来分离图像,并迫使学生将注意力集中在关键部位。然而,这种蒸馏切断了前景和背景之间的关系。因此,本文又提出了全局提取,其目的是从特征图中提取不同像素之间的全局关系,弥补重点蒸馏的全局信息丢失。
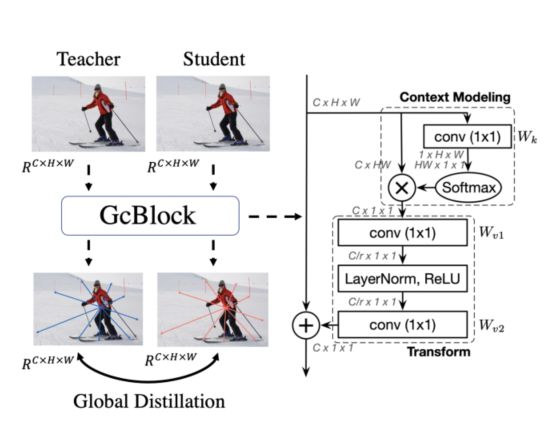
全局蒸馏用于提取不同像素之间的关系,增强前背景之间联系。利用上图中的GcBlock捕获单个图像中的全局关系信息,并强制学生检测器从老师检测器那里学习这些关系。全局损失Lgloabl如下:
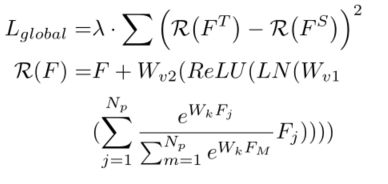
其中,输入分别是教师网络和学生网络的neck层,Wk、Wv1和Wv2表示卷积层,LN表示层归一化,Np表示特征中的像素数,λ是平衡损失的超参数。
本论文的最终损失分别由目标检测原始损失、重点损失、全局损失三部分组成,如下:
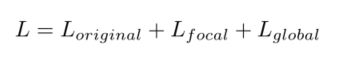
由于本论文中蒸馏损失仅在特征图(neck层输出的)上计算得到,所以它可以很容易地被应用于各种不同的检测器。
五、实验部分
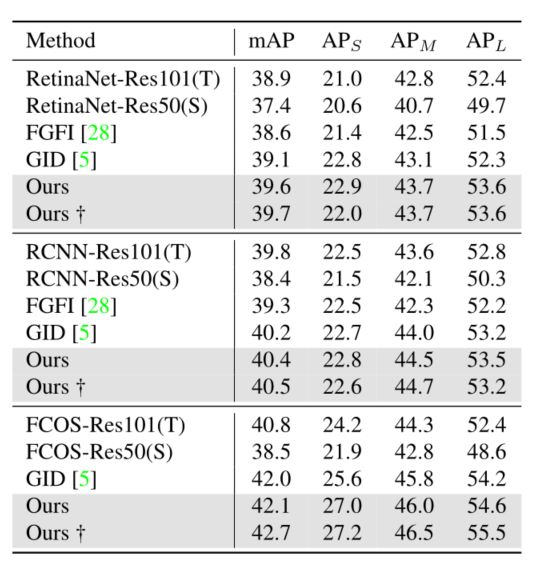
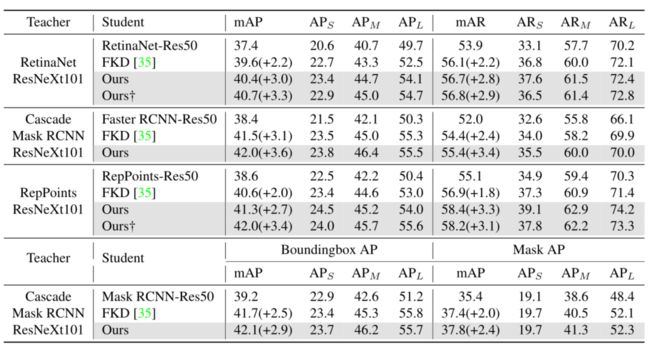
本文首先使用Res101-Res50配置在不同检测器(Faster RCNN、RetinaNet、FCOS)上对比了不同蒸馏方法(FGFI和GID),均取得最佳结果。
然后使用ResNeXt101-Res50配置在不同检测/分割网络(RetinaNet、Cascade Mask RCNN、RepPoints)上与FKD比较,体现更强主干和不同任务的效果。
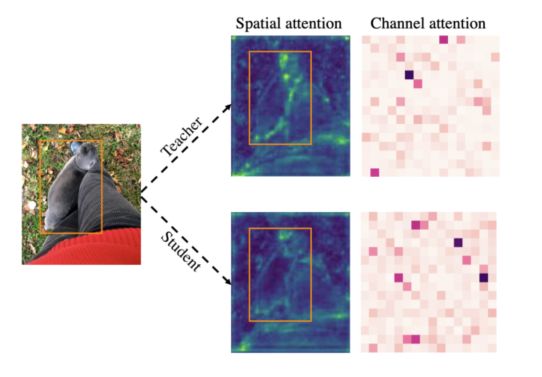
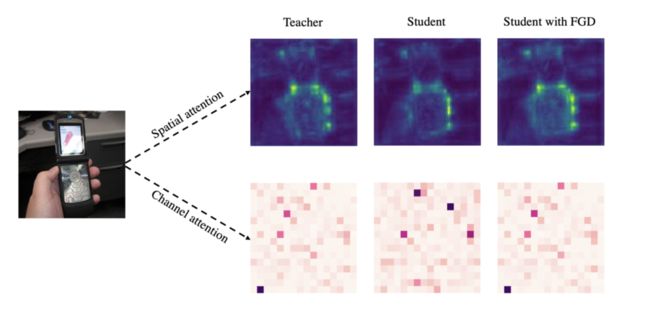
可视化对比教师和学生的空间和通道attention,可以证明使用FGD增强了学生与教师特征的一致性。
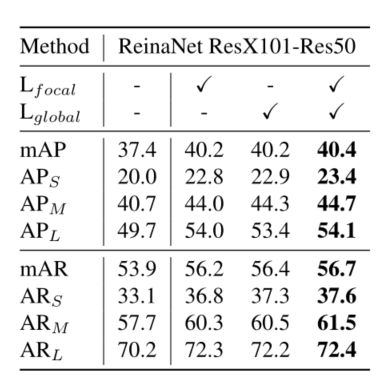
此外,分别做了焦点/全局蒸馏和空间/通道attention掩码的消融,可以看到单独使用某组件均有显著提升,叠加后效果最优。
六、总结
本文提出了重点蒸馏和全局蒸馏相结合,通过分离前景和背景的方法,使得学生模型更多关注空间和通道注意力,最终在目标检测知识蒸馏取得了较好的效果。
但本文中没有对超参α, β, γ, λ进行消融实验,缺乏一定的信服性。此外,个人感觉本文对整体框架图没有一个很好的解释,阅读起来稍许晦涩。最后,对于小目标检测性能仍然有很大的研究空间。