【知识图谱】BERT meet KG 第二弹:新训练方式,新问题视角
点击上方,选择星标,每天给你送干货!
作者|周昆(RUC AI Box)
机构|中国人民大学信息学院
方向 | 预训练模型、会话推荐系统

去年10月笔者梳理了已有的尝试在BERT中加入知识图谱的8篇相关工作(详细内容点击下方图片)。

由于该方向的迅速发展,这半年的时间里又浮现了一大批相关的研究工作。他们引入了更新的模型结构和训练方法,也有新的视角,这篇将对其中有代表性的7篇进行分析。我们的文章也同步发布在AI Box知乎专栏(知乎搜索 「AI Box专栏」),欢迎大家在知乎专栏的文章下方评论留言,欢迎大家批评和交流!

01
Coarse-to-Fine Pre-training for Named Entity Recognition
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.514.pdf
这篇论文是中科院的柳厅文老师和西湖大学的张岳老师一起发表于EMNLP2020上的一篇文章,其考虑一种特殊的预训练方式来得到专用于NER(命名实体识别)的预训练模型。
这篇论文考虑一种coarse-to-fine的预训练方式,即学习的知识粒度由粗到细。这篇文章沿用了前人的基于阅读理解中span预测的NER框架,然后提出了三步走的策略。第一步,利用维基百科给出的锚点来识别出若干实体,并训练模型区别实体词和非实体词;第二步,利用每个实体对应的类型,训练一个实体类型匹配模型,来帮助模型学习如何初步确定实体的类别;第三步,对于每个类别下的实体,模型将其对应的表示进行聚类,从而得到更加细粒度的类别标签,并给予模型来学习。该流程图如下所示,且最终得到的模型还需要在NER任务上进行fine-tune:
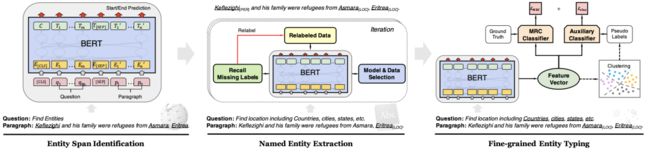
以上coarse-to-fine的训练方式使得模型能够逐步的获取NER任务相关的信息,并逐步的更新模型参数,使其能够取得比直接训练更适合于NER的表示。这篇论文采用的训练方式较其他论文更加novel,值得参考。
02
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.523.pdf
这篇论文来自于日本和华盛顿大学的研究机构,并发表于EMNLP2020。其也关注于如何更充分利用实体信息以增强预训练语言模型。
这篇论文认为现有的预训练模型的一个瓶颈在于模型并未区别考虑实体和普通单词。为解决该问题,本文提出了一个在标注entity的大规模语料库上预训练的Transformer模型,通过一个entity-aware的自注意力机制和针对entity的预训练任务,以增强该部分entity信息,其模型结构如下图所示:

从图中可以看出,该模型在embedding层添加了一个entity type embedding layer,其通过直接指出word与entity来增强模型对其的理解。不同于传统的Transformer层,本文在entity-aware层区别word与entity,分别采用不同的矩阵变换以计算其对应的attention权重,该方法简单明确的增强了这两种信息的建模。此外,本文还采用MLM的改进版本,即针对entity的mask与还原。该模型在多个知识相关任务和QA任务上均取得了SOTA的效果。
03
Entity Enhanced BERT Pre-training for Chinese NER
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.518.pdf
这篇论文是由西湖大学的张岳老师发表于EMNLP2020。其关注于如何更充分利用实体信息以增强预训练语言模型在中文NER上的表现。
中文NER任务相比较于其他任务来说,lexicon知识能够在其上取得较大的增益。该部分信息在真实世界中容易获取,且已经在很多模型中展示其优势。但是在预训练模型上还未有人进行过尝试。这篇论文首先采用一个新词发现策略来识别文档中的entity,其基于互信息以识别文档中的实体;然后采用特殊的cahr-entity自注意力机制来捕捉中文字与实体之间的关系,最终采用特殊的任务来进行模型预训练。其结构如下图所示:
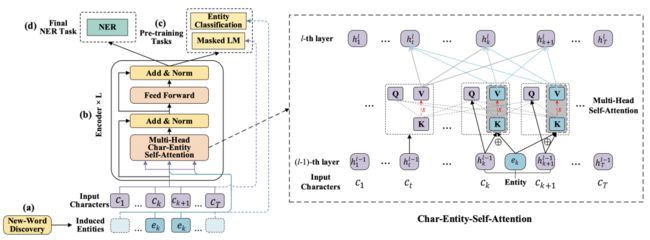
由图中可以看出,由于文档中的若干char可能会属于同一个entity,本文将其一起输入给自注意力层。通过改变char和entity作为自注意力层的QKV输入方式,以实现将entity信息融入到Transformer层中。其中对于有对应entity的char,其表示变成原始的char和entity表示的加权求和。此外,为训练以上模型,本文除MLM以外,还采用一个实体分类任务,即识别当前char属于哪一个实体,以此将char和entity映射到同一个空间。本文的模型在NER任务fine-tune后,取得了在多个中文NER数据集上的SOTA效果。
04
Pre-training Entity Relation Encoder with Intra-span and Inter-span Information
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.132.pdf
这篇论文是由上交的严骏驰老师与华东师范大学,平安科技发表于EMNLP2020。其关注于对Span-level信息的建模,并对entity和relation这部分信息以加强。
在传统的BERT的Transformer层的基础上,这篇论文引入了一个Span Encoder来对句子中的entity和relation进行建模,其采用一个基于CNN+maxpooling的方法,在BERT得到的表示的基础上进行建模。之后本文提出了三种特殊的预训练策略,分别从token-level,span-level和span pair level进行建模。如下图所示:
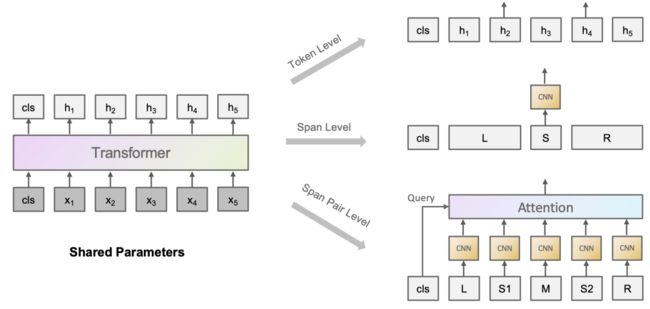
其中token-level的训练目标关注于将一个token包含的多个sub-token中除first sub-token均进行mask,然后利用这个first sub-token以还原整个token。而span-level的目标则关注于首先对一个span内部的token进行shuffle,然后由模型识别这些token属于哪一种shuffle后的顺序类型。span pair level则考虑对给出的一个句子,首先挖去其中的部分span,然后将残缺的句子和仅包含该span的句子互相进行匹配,采用对比学习的损失函数进行训练。以上三个预训练任务使得模型可以学习到许多span相关的信息,进而提升对entity/relation的理解。
05
ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
论文链接:https://arxiv.org/pdf/2012.15022.pdf
这篇论文是由清华的黄民烈老师与微信合作的论文。其关注于利用对比学习技术对实体和关系信息进行增强,以提升预训练模型表现。
这篇文章认为以后的知识驱动的预训练语言模型过于关注于对Entity和Relation单独的建模,并未考虑两者之间的复杂交互,故而无法较好的理解文本中真正的知识信息。为解决这一问题,本文提出两个基于对比学习的任务,即Entity Discrimination和Relation Discrimination。如下图所示:
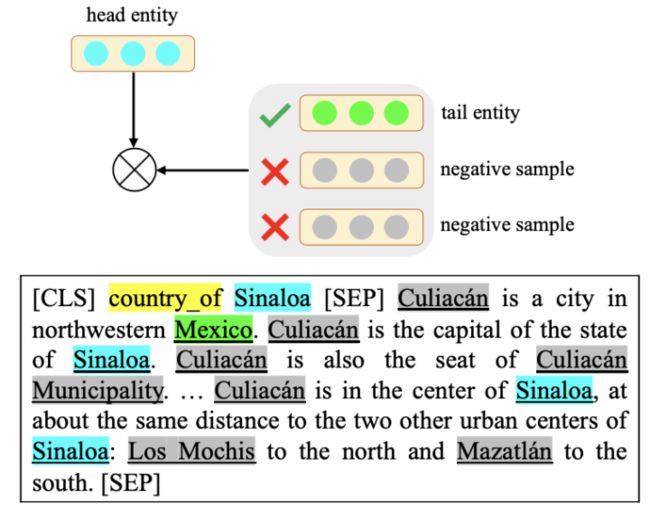
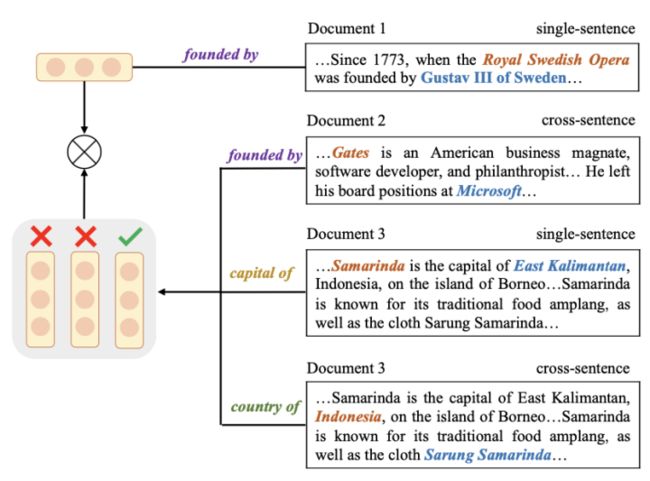
对于entity discrimination任务,模型将头实体和关系拼接到一起,并和包含尾实体的文档相拼接,以输入给BERT。对于这个输入,尾实体作为正例,而文档中的其他实体则作为负例,可以进行对比学习。对于relation discrimination任务,模型考虑不同文档中相同relation对应的entity直接的关系,这里我们把包含同样relation的triple所在的两个文档作为正例,而不同relation的作为负例,也采用对比学习进行训练。最终本文采用一个多任务学习的框架,加入MLM来进一步增强整个模型的效果。该方法在许多文档理解任务上均取得了很好的效果。
06
KgPLM: Knowledge-guided Language Model Pre-training via Generative and Discriminative Learning
论文链接:https://arxiv.org/pdf/2012.03551v1.pdf
这篇论文是由华为诺亚方舟实验室发表的论文。其关注于结合已有的生成式和判别式的预训练任务,以得到更好的知识引导的语言模型。
这篇文章关注于如何训练更好的知识引导的预训练语言模型,其考虑知识补全任务和知识验证任务。其具体实现则是一个生成式模型和一个判别性模型。其中生成式模型基于MLM来对被mask的一段进行补全;判别性模型则基于一个二分类模型判断其中是否有部分被替换成错误的token。如下图所示:

除此之外,这篇文章还考虑了将这两个任务做成pipeline还是双塔模型的形式,实验表明这两种方式各有优劣,且在许多QA任务上均有提升。
07
Language Models Are Open Knowledge Graphs
论文链接:https://arxiv.org/pdf/2010.11967.pdf
这篇论文是由清华大学和UCB投稿于ICLR的论文。其从一个非常新颖的角度,即能否利用预训练模型来构造知识图谱。
这篇论文认为预训练语言模型本身就拥有许多知识信息,可以直接将这部分信息抽取出来构成新的知识图谱并用于各类下游任务。这篇论文使用预训练模型中的attention机制来进行知识的搜索,其设置了start,yield和stop这几个action,以实现从文本中识别对应的candidate fact,如下图所示:
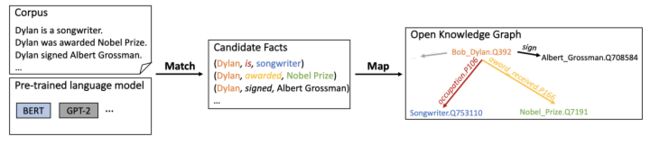
基于图中的策略,模型基于beam search选择得分最高的结果作为candidate fact;然后采用一系列预定义的过滤机制以去除噪声。之后,这篇文章将这些candidate中的entity和relation匹配到已有的KG中;同时对部分无法匹配的entity和relation进行保留,最终得到整个知识图谱。本文还对比了得到的知识图谱相比较于其他知识图谱的优劣,并对其进行相关分析。这篇论文提出了很有趣的角度,可以供大家继续挖掘。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!