【nlp论文笔记】 Glyce: Glyph-vectors for Chinese Character Representations
Abstract
本文贡献:
- 我们使用中国历史文字(如青铜器文字、篆书、繁体字等)来丰富文字的象形证据;
- 设计适合中文字符图像处理的CNN结构(称为天泽-CNN);
- 将图像分类作为多任务学习的辅助任务,以提高模型的泛化能力。
作者表明,基于符号的模型能够在广泛的中文NLP任务中始终优于基于字/字符的模型。我们能够为各种中文NLP任务设置最新的结果,包括标记(NER、CWS、POS)、句子对分类、单句分类任务、依赖解析和语义角色标记。例如,所提出的模型在NER的OntoNotes数据集上的F1得分为80.6,相比BERT的得分+1.5;在复旦文本分类的语料库中的表现出了99.8%的准确率。
Introduction
汉语是一种符号语言。汉字的符号编码了丰富的意义信息。因此,汉字的NLP任务应该从字形信息的使用中受益,这是很直观的。考虑符号信息应该有助于语义建模。最近的研究间接支持了这一观点:原子级表征在广泛的语言理解任务中被证明是有用的[Shi et al., 2015, Li et al., 2015, Yin et al., 2016, Sun et al., 2014, Shao et al., 2017]。五笔方案(一种中文编码方法,模仿在计算机键盘上输入一个字符的偏旁序列的顺序)可以提高汉英机器翻译的性能[Tan等人,2018]。Cao等人[2018]提出了更细粒度的单位,并提出了stroke n-grams 用于字符建模的。
对于有的论文提出的基于CNN的表示不能为语言建模提供额外有用的信息,甚至会降低模型性能。文章对这个现象给出几个解释:
- 他们没有使用正确的文字版本:汉字系统有一个漫长的演变历史,汉字从容易画开始,慢慢地转变为容易写。而且,随着时间的推移,它们变得不那么象形,也不那么具体。到目前为止,最广泛使用的脚本版本是简体中文,它是最容易书写的脚本,但不可避免地丢失了大量的象形信息。例如,在简体字中,一些意义无关的词在形状上非常相似,但在青铜器文字等历史语言中却有很大的不同,如 “人”、“入”。
- 没有使用合适的CNN结构:与ImageNet图像[Deng et al., 2009]不同,ImageNet图像的大小大多在800*600的尺度上,字符logo明显较小(通常为12*12)。抓取人物图像的局部图形特征需要不同的CNN架构;
- 在之前的工作中没有使用regulatory functions (应该是明确的loss函数指导训练):与包含数千万数据点的imageNet数据集上的分类任务不同imageNet包含数千万个数据点,但汉字只有大约1万个汉字。因此,辅助训练目标对于防止过拟合和提高模型的泛化能力至关重要。
解决上述的问题,本文提出了三个方法:
- 将历史和现代文字(如青铜器文字、隶书、篆书、繁体字等)与不同书写风格的文字(如草书)结合在一起,从文字形象中丰富象形信息。
- 使用田字格结构来建模。
- 我们使用多任务学习方法,通过增加图像分类loss函数提高模型的泛化能力。
论文在广泛的中文NLP任务上获得SOTA性能,这些任务包括标记(NER、CWS、POS)、句对分类(BQ, LCQMC, XNLI, NLPCC-DBQA )、单句分类任务(ChnSentiCorp, the Fudan corpus, iFeng )、句法依赖解析和语义角色标记。
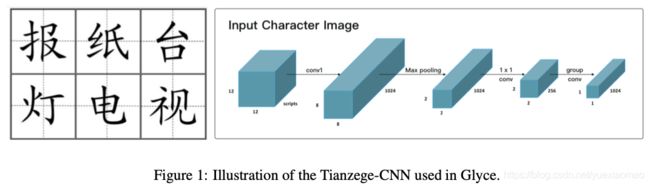
正如上述讨论的,象形信息在简体字中严重丢失。因此,作者使用了历史上不同时期和不同书写风格的文字。收集的历史的字体,其详细信息在table1中。不同历史时期的文字,通常在形状上长得不一样,这有助于模型融合不同字体的特征;不同写作风格的脚本有助于提高模型的泛化能力。田字格和历史字体都使用了计算机视觉中广泛使用的数据增强策略。
田字格CNN
输入图像(Ximage)首先通过核大小为5的卷积层,输出通道为1024,来捕获较低级的图形特征。
然后对feature map应用kernel size为4的max-pooling,将分辨率从8×8降低到2×2,这种2×2的田格结构既表现了汉字部首的排列方式,也表现了汉字的书写顺序。
使用group convolutions [Krizhevsky et al., 2012, Zhang et al., 2017] ,而不是卷积操作,将田字格映射为最终的输出。group convolutions滤波器比普通滤波器小得多,因此不太容易发生过拟合。从单一脚本到多个脚本的建模也很简单,可以通过简单地将2D(如dfont × dfont)输入改变 到3D(即dfont×dfont×Nscript), dfont表示字体大小和Nscript脚本我们使用的数量。
辅助目标用于图片分类
假设图片x的label是z,训练目标是:
![]()
让L(task)表示我们需要处理的任务的特定任务目标,例如,语言建模,分词等。我们将L(task)与L(cl)线性结合,得到最终的目标训练函数如下:
![]()
λ (t)在任务特定目标和辅助图像分类目标之间进行权衡。λ 是epoch t的函数 : λ(t) = λ0λt1, 其中λ0 ∈ [0, 1],λ0 标志起始值,λ1∈[0,1]表示衰减值。这意味着随着训练的进行,图像分类目标的影响逐渐减小,直观的解释是在训练的早期,我们需要从图像分类任务中获得更多的规则。将图像分类作为训练目标,模仿了多任务学习的思想。
将象形信息和bert结合

该模型由四层组成:BERT层、glyph层、Glyce-BERT层和特定于任务的输出层。
BERT Layer :对于句子S,使用来自BERT最后一层的输出来表示S中的token。
Glyph Layer :句子S的田字格CNN输出。
Glyce-BERT layer :Position embeddings 首先和glyph embeddings 相加。然后,与BERT concate,以获得完整的Glyce表示。
Task-specific output layer : multi-layer transformers [Vaswani et al., 2017] ,其输出给预测层。值得一提的是cls、sep这些特殊字符是在最后特定任务的embedding层维护的。
模型用于不同的任务
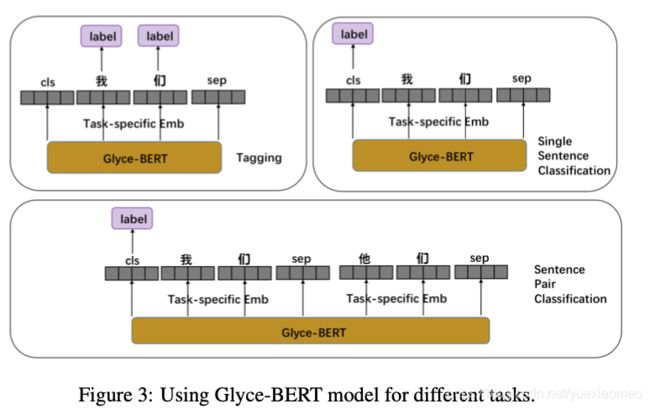
不同的任务中glyph embeddings 可以直接当做字符embedding来做,直接送入rnn cnn等。如果和bert联系起来,需要特殊处理其和bert的embedding的concat方式:
Sequence Labeling Tasks
许多中文自然语言处理任务,如名称实体识别(NER)、中文分词(CWS)和词性标注(POS),都可以形式化为字符级序列标注任务,其中我们需要为每个字符预测一个标签。对于glyce-BERT模型,来自特定于任务的层的embedding会被输入到CRF模型以进行标签预测。
Single Sentence Classification
对于文本分类任务,需要为整个句子预测单个标签。在BERT模型中,将最后一层的CLS令牌表示输出到softmax层进行预测。我们采用了类似的策略,其中任务特定层的CLS令牌的表示被反馈给softmax层来预测标签。
Sentence Pair Classification
对于SNIS这样的句子对分类任务[Bowman et al., 2015],模型需要处理两个句子之间的交互,并输出一对句子的label。在BERT设置中,一个句子对(s1, s2)由一个CLS和两个SEP标记连接,用[CLS, s1, SEP, s2, SEP]表示。然后将得到的CLS表示送入softmax层进行标签预测。我们对Glyce-BERT采用了类似的策略,[CLS, s1, SEP, s2, SEP]随后经过BERT层、Glyph层、Glyce-BERT层和特定任务的输出层。特定于任务的输出层的CLS表示被提供给softmax函数,
用于最终的标签预测。
实验效果
- 实验很多,贴了一个感兴趣的

- Dependency Parsing and Semantic Role Labeling
BERT在这两个任务中没有竞争力,因此结果被省略。(这个有点尴尬。。你的模型是靠bert来提升效果的吧。。。)
发现一个开源的 srl:https://github.com/bcmi220/srl_syn_pruning
- 将文章的模型输出层前面的transformers模型换为其他模型的实验。使用LCQMC 的sentence-pair prediction 任务
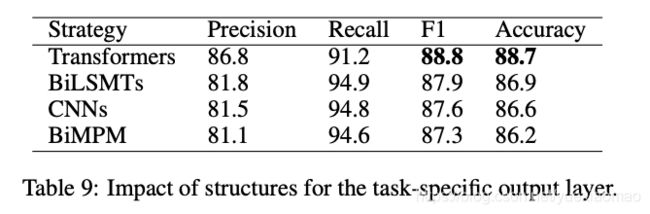
- cnn换为其他的cnn:

读后感:
1、本文思想挺有启发性的,虽然做了在其他模型上加田字格cnn的实验,效果略有提升(论文实验部分,博客未贴)。但是总感觉整体模型效果提升是因为bert带来的。并没有做去掉bert的模型试验,如将bert换为bilstm看看效果。
2、cnn部分将8*8变为2*2在做个group卷积就是田字格cnn了么?值得商榷。