基于强化学习的多智能体框架在路由和调度问题中的应用
《A reinforcement learning-based multi-agent framework applied for solving routing and scheduling problems》
Expert System with Applications/2019
A reinforcement learning-based multi-agent framework applied for solving routing and scheduling problems - ScienceDirect https://www.sciencedirect.com/science/article/pii/S0957417419302866?via%3Dihub
https://www.sciencedirect.com/science/article/pii/S0957417419302866?via%3Dihub
1 摘要
本文提出了一个使用元启发式算法进行优化的多智能体框架,称为AMAM(a multi-agent framework for optimization using metaheuristics)。在该方案中,每个智能体在组合优化问题的搜索空间中独立行动。Agent通过环境共享信息并相互协作。目标是使Agent能够根据与其他Agent和环境交互时获得的经验,使用强化学习的概念来修改他们的动作。为了更好地介绍和验证AMAM框架,本文使用了带时间窗的车辆路径问题(VRPTW)和带顺序调整时间的并行机调度问题(UPMSP-ST)这两个经典的组合优化问题。实验的主要目的是评估所提出的自适应Agent的性能。实验证实,无论是从个人的角度还是从团队的角度来看,归因于Agent的学习能力都直接影响解决方案的质量。通过这种方式,相对于文献中关于适应问题特定方面的其他框架,这里提出的框架向前迈进了一步。此外,还证实了智能体之间的合作以及它们影响参与解搜索的智能体解的质量的能力。这些结果还加强了框架的可扩展性问题,因为随着新Agent的加入,所获得的解决方案有了改进。
2 介绍
本文的主要目的是将AMAM框架作为一种使用元启发式算法解决组合优化问题的统一软件工具,包括Agent的自主性等重要特性,而不需要它们之间的任何显式协调。同时,据我们所知,该框架首次将强化学习引入到专门解决组合优化问题的框架中。这种内置的自适应能力允许代理根据特定的问题进行调整,从而在框架中提供最佳的性能。
总括而言,本文的主要贡献包括:
(1)利用强化学习的概念,特别是Q-学习算法,提高Agent的自适应能力,使Agent能够更好地适应框架要解决的问题的具体参数;
(2)通过将新解决方案纳入合作结构的标准,寻求解决方案的更大多样性,改善Agent之间的合作;
(3)说明个体Agent技能的提高如何直接影响Agent的合作绩效。
3 案例研究
为了进行案例研究,这里考虑的问题是带时间窗口的车辆路径问题(VRPTW)和带顺序相关设置时间的不相关并行机器调度问题(UPMSP-ST)。
3.1 VRPTW
在这个问题中,集合K={k:k=1,2,.。。。,|K|}个车辆停放在单个车辆段,并且必须服务集合C={i:i=1,2,.。。。,N}个地理位置分散的客户。车队是同质的,即所有车辆都是相等的,并且具有相同的容量Q。每个客户i具有给定的需求qi,并且必须在指定的时间窗口[ai,bi]内被服务(参见图1(a))。图1(b)为一个解,可用x表示为:
x=[0,2,1,12,0,3,4,5,6,0,10,7,8,9,11,0]
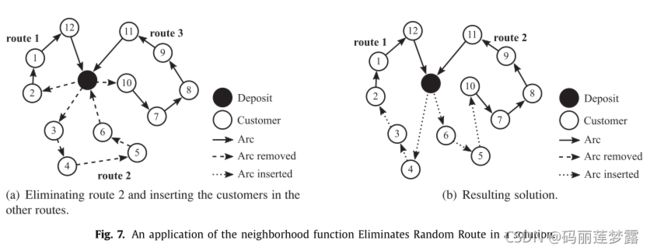
其中,索引0表示车辆段,此解决方案的三条路线分别是路线1=[0,2,1,12,0],路线2=[0,3,4,5,6,0]和路线3=[0,10,7,8,9,11,0]。因此,解x也被描述为x=[路由1,路2,路3]。
VRPTW的目标是确定一组路线,以便将此操作涉及的总成本降至最低。每条路线都与一辆车相关联。路线必须以车辆段为起点和终点。在我们的例子中,解决方案x的成本是根据以下公式计算的:


以下为6个领域结构:
(1)路由内交换

(2)路由间交换

(3) 路由内转移:

(4) 路线间转移:

(5) 两个路由内交换:

(6) 两个路由内转移:
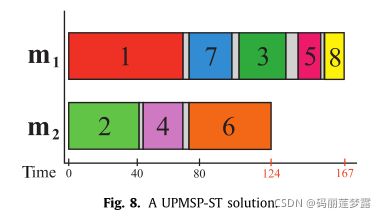
3.2 UPMSP-ST
在这个问题中,集合N={n:n=1,2,.。。。,|N|}个作业应分配给集合M={m:m=1,.。。。,|M|}台机器,每个作业j∈N必须分配给一台机器i∈M。在这里考虑的UPMSP-ST版本中,我们还定义了加工时间pij,它表示在机器I∈M上加工工件j∈N所需的时间;以及准备时间Sijk,它表示在机器I∈M上的工件j∈N之后准备工件k∈N所需的时间。
以下为4个领域结构:
(1)在不同机器中多次插入:

(2) 在同一台机器中插入:

(3)在不同机器之间交换:
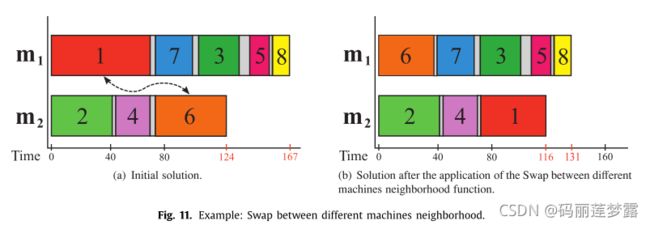
(4)同一机器之间交换:

4 多智能体元启发式优化框架

在求解的搜索过程中,框架中的Agent要经历多Agent系统环境。在这种情况下,多智能体环境由所解决问题的搜索空间定义。如图13所示,在该环境中,Agent的感知和动作能力被定义为:
(1)对环境的感知:Agent获取有关其所需问题的信息的能力;
(2)定位:Agent通过构建新解或选择已有的解来确定其在环境中的位置的能力;
(3)移动:Agent在环境中从一个解移动到另一个解的能力。这里的移动包括各种解的修改(邻域结构,算子),允许Agent从一个解移动到另一个解;
(4)合作:Agent共享并为系统的其他Agent提供解的能力。
每个Agent可用的算子定义了它对环境的看法。因此,它对环境的表现是片面的。目标是通过Agent的合作同时应用每个元启发式算法的优点。AMAM体系结构的可伸缩性由添加新Agent的简易性保证,对体系结构的其余部分影响最小。这些Agent与环境和其他Agent协作交互,交换和共享有关其状况和环境的信息。
本文的AMAM框架的结构由三个主要要素组成:
(1)环境(Environment):主要由解空间定义。因此,它提供了解所需的所有信息,即VRPTW的客户数量、客户之间的距离、车辆数量等;
(2)可行解池(Pool of Solution):负责维护所有Agent的共享解;
(3)元启发式Agent(Metaheuristic Agents):负责指导可行解的搜索。
该框架的优点是通过使用协作和并行的概念,通过多智能体方法的元启发式的杂交能力。此外,AMAM还提供了并行执行的可能性,其中每个代理都在单独的线程上运行。
需要将一个解插入到可行解池中且该池中没有可用空间时,将根据函数对现有解决方案进行评估:

其中P是池中解的个数,λij是解i和j之间的距离。评价函数g (φi)定义为一个解i到池中所有其它解的距离之和,其中φ(λij)定义为:

因子pr是池半径,控制着解的分散程度,是问题的一个参数。
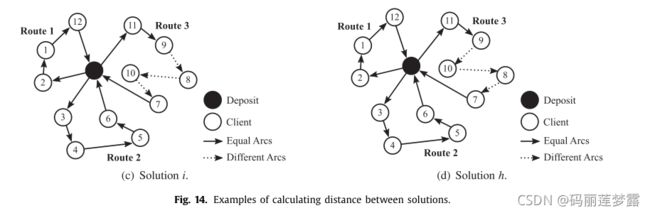
λij值衡量的是解i和j的相似程度,这从根本上取决于所处理的问题。在VRPTW中指的是非共用弧的个数,如 λij=12:
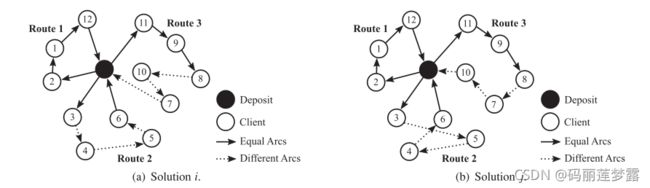
λij=6:
因此,在评估池中每个解的值g(·)之后,如果评估最差的解满足两个标准:(I)它还不在池中;(Ii)它比最差的池解具有更好的目标函数值,则排除评估最差的解,以便在池中插入新的解。(I)如果新的解满足两个标准:(I)它还不在池中;(Ii)它具有比最差的池解更好的目标函数值。这些插入新解决方案的准则是在本文中提出的,是本文的原创贡献。
此评估函数的主要目标是保持池的多样性,避免保持非常相似甚至相等的解。同时,池中现有的最优解始终存储在环境的特定属性中,并在每次插入时更新,从而防止删除找到的最优解。
5 基于RL的自适应Agent
本节展示基于RL的自适应Agent。适应能力通过基于变邻域搜索(和强化学习概念的自适应局部搜索(ALS-QLearning)分配给Agent。
VND是一种启发式的改进方法,它通过系统地交换邻域来利用优化空间。算法2给出了标准的VND结构。可以看出,对于标准VND选择的每个邻域N (k),都对当前解进行局部搜索,以找到其最佳邻域。该方法采用确定性邻域排序方法,作为邻域排序方案的参数.

在该方案中,基于Q-Learning算法,通过强化学习来定义邻域的应用顺序。主要目标是评估应用两个邻域序列所获得的增益,并从那里奖励最好的序列并最大化累积奖励。在本文中,搜索方法要使用的每个邻域都被视为一种学习状态。
5.1 马尔可夫过程
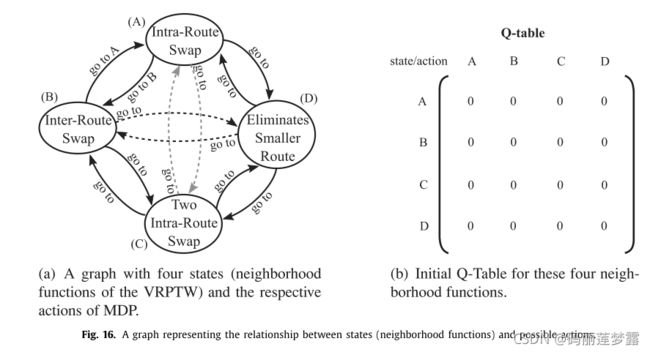
(1)状态:领域函数,于是对VRPTW为上文的8个领域结构,UPMSP-ST是4个领域结构
(2)动作:动作集可以由一个完整的图表示,其中每个动作由连接两个状态(图的节点)的弧表示。
(3)奖励函数:当前邻域函数N(X)获得的解x的适应度函数值。
自适应局部搜索算法如下:
