BP神经网络算法实现 C++
BP神经网络基本原理:
误差逆传播(back propagation, BP)算法是一种计算单个权值变化引起网络性能变化的较为简单的方法。由于BP算法过程包含从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正,所以称为“反向传播”。
BP神经网络是有教师指导训练方式的多层前馈网络,其基本思想是:从网络输入节点输入的样本信号向前传播,经隐含层节点和输出层节点处的非线性函数作用后,从输出节点获得输出。若在输出节点得不到样本的期望输出,则建立样本的网络输出与其期望输出的误差信号,并将此误差信号沿原连接路径逆向传播,去逐层修改网络的权值和节点处阈值,这种信号正向传播与误差信号逆向传播修改权值和阈值的过程反复进行,直训练样本集的网络输出误差满足一定精度要求为止。
以下是使用C/C++(大多数是C语言代码,只有数据读取部分是C++)完成的一个实际案例。
要求:
将Iris(鸢尾花)数据集分为训练集(Iris-train.txt)和测试集(Iris-test.txt),分别含75个样本,每个集合中每种花各有25个样本。为了方便训练,将3类花分别编号为1,2,3 。使用这些数据训练一个4输入(分别对应4个特征)、隐含层(10个神经元)、3输出(分别对应该样本属于某一品种的可能性大小)的神经网络(4103)。
#include 中伪随机数生成函数 rand 所能返回的最大数值。
//这意味着,任何一次对 rand 的调用,都将得到一个 0~RAND_MAX 之间的伪随机数。RAND_MAX=0x7fff
}
}
//BP训练函数
void train(double trainData[trainsample][innode], double label[trainsample][outnode])
{
double x[innode];//输入层的输入值
double yd[outnode];//期望的输出值
double o1[hidenode];//隐层结点激活值
double o2[hidenode];//输出层结点激活值
double x1[hidenode];//隐层向输出层的输入
double x2[outnode];//输出结点的输出
/*********************************************************************
o1: 隐层各结点的激活值等于与该结点相连的各路径上权值与该路径上的输入相乘后全部相加
**********************************************************************
x1: 隐层结点的输出,计算出o1后才能计算x1,等于 1.0/(1.0 + exp-(激活值+该结点的阈值))
***********************************************************************
o2: 输出层结点的激活值等于与该结点相连的各路径上的权值与该路径的输入相乘后全部相加
***********************************************************************
x2: 输出层结点的输出,计算出o2后才能计算x2,等于 1.0/(1.0 + exp-(激活值+该结点的阈值))
***********************************************************************/
/*从前往后——输出单元偏差qq计算方式: (期望输出 - 实际输出)乘上 实际输出 乘上 (1-实际输出) */
double qq[outnode];//期望的输出与实际输出的偏差
double pp[hidenode];//隐含结点校正误差
int issamp;
int i,j,k;
for(issamp=0; issamp<trainsample; issamp++)
{
for(i=0; i<innode; i++)
x[i] = trainData[issamp][i];
for(i=0; i<outnode; i++)
yd[i] = label[issamp][i];
//计算隐层各结点的激活值和隐层的输出值
for(i=0; i<hidenode; i++)
{
o1[i] = 0.0;
for(j=0; j<innode; j++)
o1[i] = o1[i]+w[j][i]*x[j]; //w[][]为输入层到隐含层的网络权重,o1是隐层结点激活值
x1[i] = 1.0/(1.0+exp(-o1[i]-b1[i])); //x1是隐含层的输出
}
//计算输出层各结点的激活值和输出值
for(i=0; i<outnode; i++)
{
o2[i] = 0.0;
for(j=0; j<hidenode; j++)
o2[i] = o2[i]+w1[j][i]*x1[j]; //w1[][]为隐层到输出层的权值,o2为输出层结点激活值
x2[i] = 1.0/(1.0+exp(-o2[i]-b2[i])); //x2为输出结点的输出
}
//得到了x2输出后接下来就要进行反向传播了
//计算实际输出与期望输出的偏差,反向调节隐层到输出层的路径上的权值
for(i=0; i<outnode; i++)
{
qq[i] = (yd[i]-x2[i]) * x2[i] * (1-x2[i]); //输出节点j的偏差
for(j=0; j<hidenode; j++)
w1[j][i] = w1[j][i]+rate_w1*qq[i]*x1[j]; //隐层到输出层的路径上的权值
}
//继续反向传播调整输出层到隐层的各路径上的权值
for(i=0; i<hidenode; i++)
{
pp[i] = 0.0;
for(j=0; j<outnode; j++)
pp[i] = pp[i]+qq[j]*w1[i][j];
pp[i] = pp[i]*x1[i]*(1.0-x1[i]); //隐含层节点i的偏差
for(k=0; k<innode; k++)
w[k][i] = w[k][i] + rate_w*pp[i]*x[k]; //输出层到隐层的各路径上的权值
}
//调整允许的最大误差
for(k=0; k<outnode; k++)
{
e+=fabs(yd[k]-x2[k])*fabs(yd[k]-x2[k]); //计算均方差
}
error=e/2.0;
//调整输出层各结点的阈值
for(k=0; k<outnode; k++)
b2[k]=b2[k]+rate_b2*qq[k];
//调整隐层各结点的阈值
for(j=0; j<hidenode; j++)
b1[j]=b1[j]+rate_b1*pp[j];
}
}
//Bp识别
double *recognize(double *p)
{
double x[innode];//输入层的个输入值
double o1[hidenode];//隐层结点激活值
double o2[hidenode];//输出层结点激活值
double x1[hidenode];//隐层向输出层的输入
double x2[outnode];//输出结点的输出
int i,j,k;
for(i=0;i<innode;i++)
x[i]=p[i];
for(j=0;j<hidenode;j++)
{
o1[j]=0.0;
for(i=0;i<innode;i++)
o1[j]=o1[j]+w[i][j]*x[i]; //隐含层各单元激活值
x1[j]=1.0/(1.0+exp(-o1[j]-b1[j])); //隐含层各单元输出
}
for(k=0;k<outnode;k++)
{
o2[k]=0.0;
for(j=0;j<hidenode;j++)
o2[k]=o2[k]+w1[j][k]*x1[j];//输出层各单元激活值
x2[k]=1.0/(1.0+exp(-o2[k]-b2[k]));//输出层各单元输出
}
for(k=0;k<outnode;k++)
{
result[k]=x2[k];
}
return result;
}
//从文件夹读取数据
void readData(std::string filename, double data[][innode], int x)
{
ifstream inData(filename, std::ios::in);
int i,j;
double dataLabel;
for(i=0; i<x; i++)
{
for(j=0; j<innode; j++)
{
inData >>data[i][j];
}
inData >>dataLabel;
}
inData.close();
}
//数据归一化处理——就是把数变为(0,1)之间的小数,主要是为了数据处理方便
void changeData(double data[][innode], int x)
{
//归一化公式:(x-min)/(max-min)
double minNum,maxNum;
int i,j;
minNum = data[0][0];
maxNum = data[0][0];
//找最大最小值
for(i=0; i<x; i++)
{
for(j=0; j<innode; j++)
{
if(minNum > data[i][j])
minNum = data[i][j];
if(maxNum < data[i][j])
maxNum = data[i][j];
}
}
//归一化
for(i=0; i<x; i++)
{
for(j=0; j<innode; j++)
data[i][j] = (data[i][j]-minNum)/(maxNum-minNum);
}
}
训练数据:Iris-train.txt
5.1 3.5 1.4 0.2 0
4.9 3.0 1.4 0.2 0
4.7 3.2 1.3 0.2 0
4.6 3.1 1.5 0.2 0
5.0 3.6 1.4 0.2 0
5.4 3.9 1.7 0.4 0
4.6 3.4 1.4 0.3 0
5.0 3.4 1.5 0.2 0
4.4 2.9 1.4 0.2 0
4.9 3.1 1.5 0.1 0
5.4 3.7 1.5 0.2 0
4.8 3.4 1.6 0.2 0
4.8 3.0 1.4 0.1 0
4.3 3.0 1.1 0.1 0
5.8 4.0 1.2 0.2 0
5.7 4.4 1.5 0.4 0
5.4 3.9 1.3 0.4 0
5.1 3.5 1.4 0.3 0
5.7 3.8 1.7 0.3 0
5.1 3.8 1.5 0.3 0
5.4 3.4 1.7 0.2 0
5.1 3.7 1.5 0.4 0
4.6 3.6 1.0 0.2 0
5.1 3.3 1.7 0.5 0
4.8 3.4 1.9 0.2 0
7.0 3.2 4.7 1.4 1
6.4 3.2 4.5 1.5 1
6.9 3.1 4.9 1.5 1
5.5 2.3 4.0 1.3 1
6.5 2.8 4.6 1.5 1
5.7 2.8 4.5 1.3 1
6.3 3.3 4.7 1.6 1
4.9 2.4 3.3 1.0 1
6.6 2.9 4.6 1.3 1
5.2 2.7 3.9 1.4 1
5.0 2.0 3.5 1.0 1
5.9 3.0 4.2 1.5 1
6.0 2.2 4.0 1.0 1
6.1 2.9 4.7 1.4 1
5.6 2.9 3.6 1.3 1
6.7 3.1 4.4 1.4 1
5.6 3.0 4.5 1.5 1
5.8 2.7 4.1 1.0 1
6.2 2.2 4.5 1.5 1
5.6 2.5 3.9 1.1 1
5.9 3.2 4.8 1.8 1
6.1 2.8 4.0 1.3 1
6.3 2.5 4.9 1.5 1
6.1 2.8 4.7 1.2 1
6.4 2.9 4.3 1.3 1
6.3 3.3 6.0 2.5 2
5.8 2.7 5.1 1.9 2
7.1 3.0 5.9 2.1 2
6.3 2.9 5.6 1.8 2
6.5 3.0 5.8 2.2 2
7.6 3.0 6.6 2.1 2
4.9 2.5 4.5 1.7 2
7.3 2.9 6.3 1.8 2
6.7 2.5 5.8 1.8 2
7.2 3.6 6.1 2.5 2
6.5 3.2 5.1 2.0 2
6.4 2.7 5.3 1.9 2
6.8 3.0 5.5 2.1 2
5.7 2.5 5.0 2.0 2
5.8 2.8 5.1 2.4 2
6.4 3.2 5.3 2.3 2
6.5 3.0 5.5 1.8 2
7.7 3.8 6.7 2.2 2
7.7 2.6 6.9 2.3 2
6.0 2.2 5.0 1.5 2
6.9 3.2 5.7 2.3 2
5.6 2.8 4.9 2.0 2
7.7 2.8 6.7 2.0 2
6.3 2.7 4.9 1.8 2
6.7 3.3 5.7 2.1 2
测试数据:Iris-test.txt
5.0 3.0 1.6 0.2 0
5.0 3.4 1.6 0.4 0
5.2 3.5 1.5 0.2 0
5.2 3.4 1.4 0.2 0
4.7 3.2 1.6 0.2 0
4.8 3.1 1.6 0.2 0
5.4 3.4 1.5 0.4 0
5.2 4.1 1.5 0.1 0
5.5 4.2 1.4 0.2 0
4.9 3.1 1.5 0.1 0
5.0 3.2 1.2 0.2 0
5.5 3.5 1.3 0.2 0
4.9 3.1 1.5 0.1 0
4.4 3.0 1.3 0.2 0
5.1 3.4 1.5 0.2 0
5.0 3.5 1.3 0.3 0
4.5 2.3 1.3 0.3 0
4.4 3.2 1.3 0.2 0
5.0 3.5 1.6 0.6 0
5.1 3.8 1.9 0.4 0
4.8 3.0 1.4 0.3 0
5.1 3.8 1.6 0.2 0
4.6 3.2 1.4 0.2 0
5.3 3.7 1.5 0.2 0
5.0 3.3 1.4 0.2 0
6.6 3.0 4.4 1.4 1
6.8 2.8 4.8 1.4 1
6.7 3.0 5.0 1.7 1
6.0 2.9 4.5 1.5 1
5.7 2.6 3.5 1.0 1
5.5 2.4 3.8 1.1 1
5.5 2.4 3.7 1.0 1
5.8 2.7 3.9 1.2 1
6.0 2.7 5.1 1.6 1
5.4 3.0 4.5 1.5 1
6.0 3.4 4.5 1.6 1
6.7 3.1 4.7 1.5 1
6.3 2.3 4.4 1.3 1
5.6 3.0 4.1 1.3 1
5.5 2.5 4.0 1.3 1
5.5 2.6 4.4 1.2 1
6.1 3.0 4.6 1.4 1
5.8 2.6 4.0 1.2 1
5.0 2.3 3.3 1.0 1
5.6 2.7 4.2 1.3 1
5.7 3.0 4.2 1.2 1
5.7 2.9 4.2 1.3 1
6.2 2.9 4.3 1.3 1
5.1 2.5 3.0 1.1 1
5.7 2.8 4.1 1.3 1
7.2 3.2 6.0 1.8 2
6.2 2.8 4.8 1.8 2
6.1 3.0 4.9 1.8 2
6.4 2.8 5.6 2.1 2
7.2 3.0 5.8 1.6 2
7.4 2.8 6.1 1.9 2
7.9 3.8 6.4 2.0 2
6.4 2.8 5.6 2.2 2
6.3 2.8 5.1 1.5 2
6.1 2.6 5.6 1.4 2
7.7 3.0 6.1 2.3 2
6.3 3.4 5.6 2.4 2
6.4 3.1 5.5 1.8 2
6.0 3.0 4.8 1.8 2
6.9 3.1 5.4 2.1 2
6.7 3.1 5.6 2.4 2
6.9 3.1 5.1 2.3 2
5.8 2.7 5.1 1.9 2
6.8 3.2 5.9 2.3 2
6.7 3.3 5.7 2.5 2
6.7 3.0 5.2 2.3 2
6.3 2.5 5.0 1.9 2
6.5 3.0 5.2 2.0 2
6.2 3.4 5.4 2.3 2
5.9 3.0 5.1 1.8 2
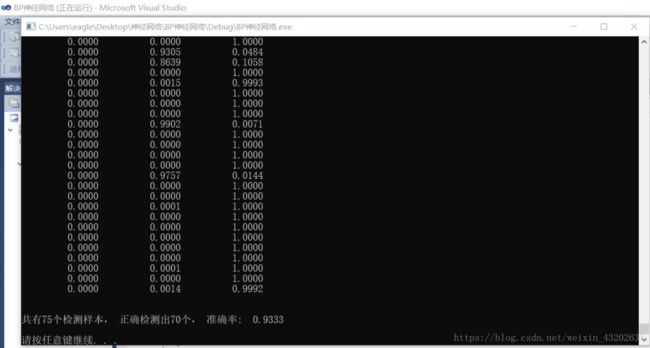
程序运行结果:
注意:1.训练数据和测试数据的文件命名为lris-train、lris-test,不要加上.txt;
2.两个txt文件要放在跟源文件同目录下。