论文学习笔记-YOLACT++
『写在前面』
YOLACT升级版。
文章标题:《YOLACT++ Better Real-time Instance Segmentation》
作者机构:Daniel Bolya等, University of California, Davis.
原文链接:https://arxiv.org/abs/1912.06218
相关repo:https://github.com/dbolya/yolact
概述
在保证实时性(~30fps)的前提下,对原版YOLACT做出几点改进,大幅提升mAP。
主要优化方法:
1)引入可变形卷积到backbone中;
2)优化预测头结构;
3)添加fast mask re-scoring分支。
YOLACT回顾
关于原版YOLACT,请参阅:https://blog.csdn.net/sinat_37532065/article/details/89415374
补充1:为什么YOLACT使用Convs预测proto masks,而使用FC来预测mask系数?
因为mask天然存在空间相关性,Convs可以利用这种相关性,而FC不行,FC更适合做一些数值回归和概率预测等。因此,YOLACT中使用Convs来产生原型mask,而使用FC来预测对应的mask系数。
补充2:为什么增加protonet中产生的原型mask的数量(k)不一定有益于提高mAP?
因为一方面,预测一组系数向量本身是一个比较困难的问题;另一方面,在作mask合并时,即使只有一个系数预测的偏差较大,可能也会严重影响最终合成出的mask质量。所以,单方面增加k不一定奏效,考虑到分解研究中提到的各原型mask的作用可扩展,k的大小设置合理即可。
YOLACT++
1 Fast Mask Re-scoring
受MS R-CNN启发,高质量的mask并不一定就对应着高的分类置信度,换句话说,以包围框得分来评价mask好坏并不合理。
MS R-CNN在Mask R-CNN的基础上,添加了一个新的模块,用于回归预测出的mask与其对应的GT-mask的IoU。
YOLACT++借鉴其思想,添加了Mask Re-Scoring分支,该分支使用YOLACT生成的裁剪后的proto mask(未作阈值化)作为输入,输出对应每个类别的GT-mask的IoU。Fast Mask Re-Scoring分支的模型结构如下图所示,由6个Conv + 1个GAP操作组成。
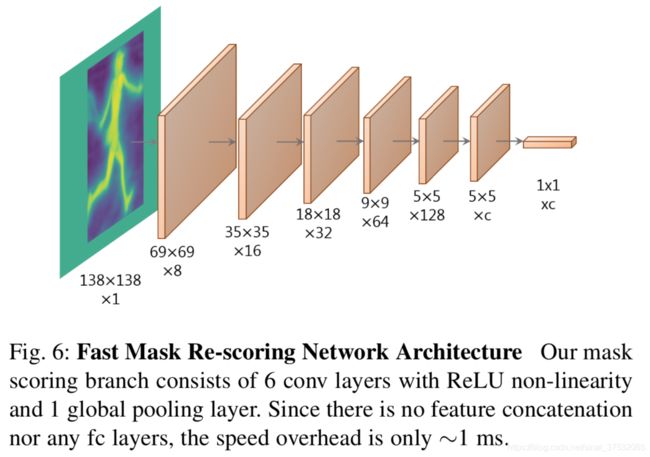
与MS R-CNN不同的地方在于:
1)YOLACT++直接使用全尺寸mask(bbox外的区域填0)作为scoring分支的输入,而MS R-CNN使用的是RPN->ROI Align后的特征再与其经过mask预测分支计算后的特征拼接后的组成的特征;
2)YOLACT++的scoring分支没有使用FC层,这使得速度极快。
作者做了实验对比,使用YOLACT++中提出的scoring分支单帧耗时只增加了1.2ms,而如果再YOLACT的基础上使用MS R-CNN中的scoring分支则会将单帧耗时提高28ms。这其中,ROI Align/ FC层/ concate操作都会带来较大的耗时。
2 有间隔地使用DCN(可变形卷积)
DCNs通过使用自由形式的采样代替了传统CNN中使用的刚性网格采样,而全面刷新了各检测模型的精度。在YOLACT++中,作者参考DCNv2的思路,将ResNet C3~C5中的各个标准3x3卷积替换成3x3可变形卷积,但没有使用modulated deformable模块,因为太高的延迟伤不起。
通过引入DCN到backbone中,YOLACT的mask mAP提高了1.8,而单帧耗时提高了8ms。作者认为,DCN之所以在YOLACT上表现良好,原因有二:
1)DCN通过与目标实例对齐,增强了网络处理具有不同比例,旋转和纵横比的实例的能力;
2)因为YOLACT是一种one-shot架构,相比于Mask R-CNN等two-stage模型,YOLACT缺乏一个重采样过程,也就没有办法恢复次优采样,而Mask R-CNN通过ROI Align操作,将各目标对齐到一定区域,可以在一定程度上缓解该问题。
尽管DCN实验证明很优秀,但是如果按照DCNv2的思路,在ResNet-101中需要替换30个卷积层,这会带来较高的延迟。作者做了三组实验,最后选择每隔3个卷积层,替换一个标准卷积为可变形卷积,这样取得了一些trade-off,而且相比全部替换仅-0.2mAP.
3 优化预测头
因为YOLACT是anchor-based的,所以可以优化anchor设计。
经过试验,选择了在每个FPN level上乘3种大小(1、![]() 、
、![]() ),这样相当于anchor数量较原版YOLACT增加了3倍。没理解为什么这么设计大小。。但的确是这么算的:
),这样相当于anchor数量较原版YOLACT增加了3倍。没理解为什么这么设计大小。。但的确是这么算的:
# https://github.com/dbolya/yolact/blob/master/data/config.py Line.801
>>> [[i * 2 ** (j / 3.0) for j in range(3)] for i in [24, 48, 96, 192, 384]]
>>> [[24.0, 30.238105197476955, 38.097625247236785],
[48.0, 60.47621039495391, 76.19525049447357],
[96.0, 120.95242078990782, 152.39050098894714],
[192.0, 241.90484157981564, 304.7810019778943],
[384.0, 483.8096831596313, 609.5620039557886]]讨论
Mask Re-Scoring分支的作用
YOLACT++中新加入的fast mask re-scoring branch使得模型可以结合框的质量和mask的质量对预测结果进行综合排序,与仅依赖分类置信度进行排序收效显著。下图显示了重新排序后的结果,可以真正按实例分割的质量进行排序。
理解mAP之间的差距
YOLACT和MASK R-CNN的mAP差距~6,而YOLACT本身的box和mask的mAP仅相差2.5,MASK R-CNN的box和mask的mAP也差2.5。这说明,即使YOLACT有能力预测出更精细的mask,但由于检测器部分不够给力,拖了后腿。作者还尝试升级YOLACT中的backbone部分,这的确显著提高了mAP,但box和mask的mAP之间的差距仍只有1.5。