【神经网络】学习笔记十四——Seq2Seq模型
本文简要介绍seq2seq,即序列到序列的基本知识,是深度学习和NLP中一个重要的知识。
从三部分来说,seq2seq基本简介,应用场景和原理解析。
一、什么是Seq2Seq
所谓Seq2Seq(Sequence to Sequence),即序列到序列模型,就是一种能够根据给定的序列,通过特定的生成方法生成另一个序列的方法,同时这两个序列可以不等长。这种结构又叫Encoder-Decoder模型,即编码-解码模型,其是RNN的一个变种,为了解决RNN要求序列等长的问题。
举一个简单的例子,在机器翻译中,源语言和目标语言的长度往往不相等。如,当我们使用机器翻译时:输入(Hello) -->输出(你好)。再比如在人机对话中,我们问机器:“你是谁?”,机器会返回答案“我是某某某”。
机器翻译,人机对话,聊天机器人等,都用到了我们所说的Seq2Seq,如图是一个简单的邮件对话的场景。
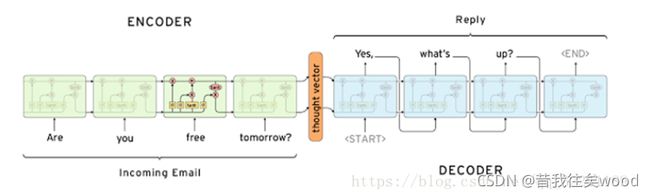
结构如上图所示,在编码过程中,输入序列通过Encoder,得到语义向量C,语义向量C作为Decoder的初始状态 h0,参与解码过程,生成输出序列。此处Encoder和Decoder都是RNN单元,C可以看作输入序列内容的一个集合,输入序列所有的语义信息都包含在C这个向量里面。详见第三部分原理解析。
同时,Seq2Seq使用的都是RNN单元,一般为LSTM和GRU。
二、Seq2Seq的应用场景
Seq2Seq的应用随着计算机科学与技术的发展,已经在很多领域产生了应用,如:
(1)机器翻译:Seq2Seq最经典的应用,当前著名的Google翻译就是完全基于 Seq2Seq+Attention机制开发的。
(2)文本摘要自动生成:输入一段文本,输出这段文本的摘要序列。
(3)聊天机器人:第二个经典应用,输入一段文本,输出一段文本作为回答。
(4)语音识别:输入语音信号序列,输出文本序列。
(5)阅读理解:将输入的文章和问题分别编码,再对其解码得到问题的答案。
(6)图片描述自动生成:自动生成图片的描述。
(7)机器写诗歌,代码补全,故事风格改写,生成commit message等。
三、 Seq2Seq原理解析
3.1 最基础的结构

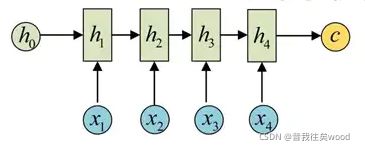
如上图,Seq2Seq最基础的结构由三部分组成,编码器,语义向量C和解码器,C是连接二者的。编码器通过学习,将输入序列编码成一个固定大小的状态向量C,作为解码器的输入,解码器RNN通过对C的学习进行输出。
再补充一遍,此处解码器和编码器都代表一个RNN,通常为LSTM和GRU。
3.2 Seq2Seq结构详解
其基本思想利用两个RNN,一个作为Encoder,一个作为Decoder。前者负责将输入的文本序列压缩成指定长度的向量,即语义向量C,这个向量可以看作输入序列的语义,这个过程成为编码。
编码一般有两种方式,将RNN最后一个状态做一个变换得到语义向量,或者将输入序列的所有隐含状态做一个变换得到语义向量。
Decoder负责根据语义向量生成指定的序列,即解决问题的序列,即解码。如下图,最简单的方式是将语义向量C作为初始状态输入到Encoder的RNN中,得到输出序列。此时上一时刻的输出会成为当前时刻的输入,而且语义向量C只作为初始状态参与运算,后面运算与C无关。
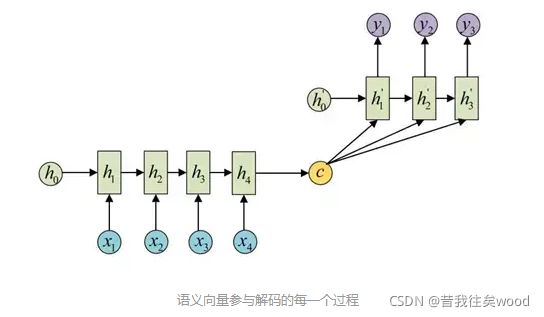
第二种方式语义向量C参与序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但C参与每个时刻的运算。

3.3 Seq2Seq训练原理
首先,对于普通RNN的训练,我们比较理解,简单来说就是学习概率分布,然后预测,比如输入前t 个 时刻数据,预测 t+1 时刻的数据。常见的是字符预测或者温度预测。一般我们在输出层(即预测结果层)使用softmax函数,就得到每个分类的概率,然后哪个最大哪个就为预测结果。
简单来说,对于普通RNN的一个训练样本x1,x2,……,xT,其计算的概率是当x1,x2,……,x(T-1)成立时时,xT成立的概率。即整个序列的概率为:
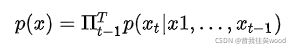
而对于两个RNN组成的解码编码器,其是输入一个序列,结果是输出一个序列,即输入序列成立的前提下,输出序列成立的概率,即整个序列的概率为:
![]()
然后结果就是求概率最大的输出序列,作为结果即可。
3.4 典型实例
首先来一波显然的实例,机器自动作诗的实例:

说明一下,在本图中有两个点:
(1)解码Decoder每个阶段,每次都会参照中间状态向量C(下边Attention会用到这个),而不是只作为初始状态;
(2)目前,输入的语句序列一般为倒序输入;
其次,来看一个加了Attention机制的Seq2Seq:
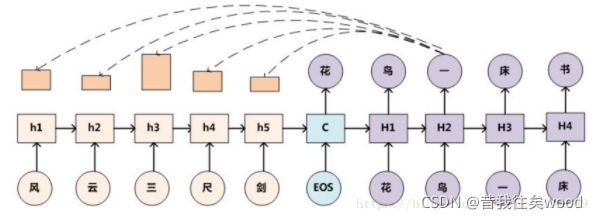
LSTM模型虽然具有记忆性,但是当编码阶段Encoder输入序列过长时,解码阶段的LSTM也无法很好的针对过早的输入序列解码,所以Attention注意力分配的机制被提出。此时,在解码的每一步解码时,都能有一个输入,对输入序列所有隐藏层信息h1,h2,……进行加权求和(显然对应的 Ht 和 ht 权重最大,其他的权重相对较小)。即每次预测该步时就先把所有输入序列的隐藏层信息都看一遍,决定预测当前词和输入序列的哪些词最相关,提高预测质量。
这里再多余的详细解释一下计算过程。
Attention机制表示在解码Decoder阶段,每次都需要有三个输入,解码阶段上一层的隐藏状态S(i-1),上一阶段的预测输入y(i),本次预测对应的编码阶段的上下文向量C(i),则本次解码阶段的新状态S(i)由三者的一个非线性函数得出:
![]()
其中,S(i-1)和y(i)分别为解码阶段上一个状态的隐藏状态和预测输出值,C(i)为编码阶段每个时刻输出状态的加权平均和,计算如下:
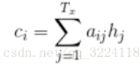
其中a(ij)是输入 i 对应的状态 h(j) 的权重大小,计算公式为:
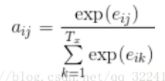
其中 e(ij) 计算公式为:
![]()
四、Seq2Seq训练以及数据处理
这里说一下数据预处理和怎么去训练的。
有同学可能要问,CNN是卷积层连接全连接层,最后输出层有若干个分类,哪个类别概率最大就是哪个,那RNN作为预测数据的网络,输出的不应该是预测的一个什么值嘛?这个预测的值是怎么回事,输出的预测值不应该是一个数字嘛,一个随机数?那怎么通过RNN的训练得出输出这个随机数呢?
其实不是的,所有的神经网络,训练最后输出的,都一定是概率。即最后的全连接层,得到结果的分类层都是有很多的类别,然后哪个概率最大就选哪个。
就拿人机对话为例,我们输入一句话,机器输出对应回答的句子,处理方法如下:
(1)假设有10000个问答句作为训练样本,我们统计得到1000个互异的字和每个字出现的次数;
(2)根据统计得到的这1000个字,按照字数从多到少排序,即0-999结束,得到字典表;
(3)基于得到字典表,对问答句进行one-hot编码;
(4)由于编码难度较大且0多,我们进行embedding降维,得到特征矩阵;
(5)得到特征矩阵后就可以作为输入,然后预测时输出的值是分类个数为1000的分类器,哪个概率最大预测所得就是对应的哪个字。
总结重点:
总的来说Seq2Seq就是两个RNN拼起来的一个具有特殊用处的神经网络,可以用来机器翻译,人机对话等。注意理解下面几点:
(1)三部分:解码器,编码器,连接前两者(两个RNN)的语义向量C;
(2)C一般作为解码器RNN的初始状态h0,也有可能每步都参与运算;
(3)理解上一时刻的输出作为当前时刻的输入;
(4)理解RNN预测是怎么实现的,数据经过处理。