mmdetection中faster_rcnn的实现
mmdetection中faster_rcnn的实现
前置内容:
mmdetecion 中类注册的实现(@x.register_module())
内容包括:
faster_rcnn
backbone
neck
rpn_head
faster_rcnn
@DETECTORS.register_module()
class FasterRCNN(TwoStageDetector):
在代码中,fasterRCNN继承了TwoStageDetector,TwoStageDetector继承了BaseDetector,在BaseDetector中实现了forward,其中判断训练和test调用了forward_train和forward_test,我们关注的也就是forward_train()
faster_rcnn依次调用了backbone,neck,rpn,roi,之后计算loss
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
proposals=None,
**kwargs):
x = self.extract_feat(img) # 特征提取+fpn
losses = dict()
# RPN 过程
if self.with_rpn:
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
rpn_losses, proposal_list = self.rpn_head.forward_train(
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=gt_bboxes_ignore,
proposal_cfg=proposal_cfg,
**kwargs)
losses.update(rpn_losses)
else:
proposal_list = proposals
#roi过程
roi_losses = self.roi_head.forward_train(x, img_metas, proposal_list,
gt_bboxes, gt_labels,
gt_bboxes_ignore, gt_masks,
**kwargs)
losses.update(roi_losses)
return losses
backbone
backbone的调用在
x = self.extract_feat(img) # 特征提取+fpn
在传入backbone后直接传入neck(如果有)
def extract_feat(self, img):
"""Directly extract features from the backbone+neck."""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
我们使用的backbone配置文件为:
backbone=dict(
type='ResNet',
depth=50, # 使用res50
num_stages=4, #4层
out_indices=(0, 1, 2, 3), #输出前4层的特征,也就是C2,C3,C4,C5
frozen_stages=1, # 冻结的stage数量,即该stage不更新参数,-1表示所有的stage都更新参数
norm_cfg=dict(type='BN', requires_grad=True), #使用bach_norm
norm_eval=True, #在test时候使用norm
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
配置文件到类的转换可以查看[mmdetecion 中类注册的实现(@x.register_module())]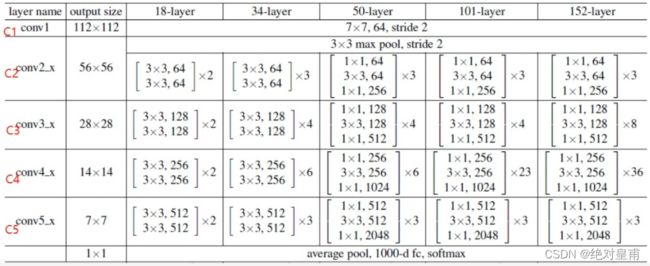
由out_indices=4可以获得我们输出的层数为4,如果batch_size为16,图像大小为800*800,那么最终输出的4个特征分别为:
(16,256,200,200)(16,512,100,100)(16,1024,50,50)(16,2048,25,25)
neck
neck之所以叫neck,他是用于处理特征提取和head之间的内容
以fpn为例:
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
in_channels表示输入的4层,通道数分别为256, 512, 1024, 2048,对应我们上面res50的输出层数和通道数
具体的处理如下图:
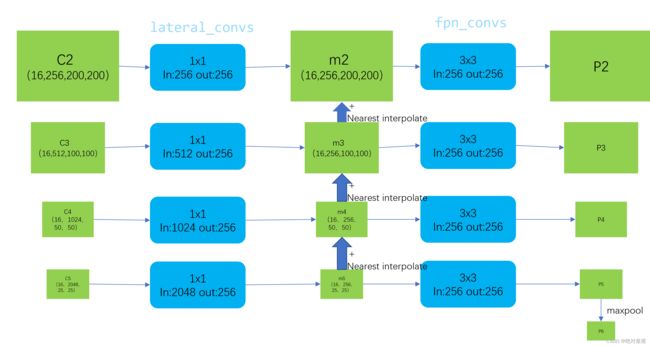
def forward(self, inputs):
"""Forward function."""
assert len(inputs) == len(self.in_channels)
# 使用1x1卷积的部分
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# 经过最近线性插值之后加上,得到m
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
# In some cases, fixing `scale factor` (e.g. 2) is preferred, but
# it cannot co-exist with `size` in `F.interpolate`.
if 'scale_factor' in self.upsample_cfg:
laterals[i - 1] += F.interpolate(laterals[i],
**self.upsample_cfg)
else:
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] += F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
# build outputs
# part 1: from original levels
# 原来部分的输出
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
# part 2: add extra levels
#补充输出,也就是图上的P6
#在配置中,我们的in_chennel是4,那么就有4个原始的输出,但是我们设置的out_num=5,这多余的部分全部使用补充输出
if self.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.add_extra_convs == 'on_input':
extra_source = inputs[self.backbone_end_level - 1]
elif self.add_extra_convs == 'on_lateral':
extra_source = laterals[-1]
elif self.add_extra_convs == 'on_output':
extra_source = outs[-1]
else:
raise NotImplementedError
outs.append(self.fpn_convs[used_backbone_levels](extra_source))
for i in range(used_backbone_levels + 1, self.num_outs):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
return tuple(outs)
rpn_head
在mmdetecion中rpn_head写得相当恼火,由于三重继承的关系,子类里又常常重写父类方法,使用配置文件又使得按住ctrl追踪不了,看代码相当折磨
RPNHead继承AnchorHead继承BaseDenseHead
整个实现在这三个文件中交错分布,看代码的时候需要来回寻找,并且时刻关注子类中是不是重写了方法
rpn_head中执行的是forward_train,其中进行了前向传播之后计算了loss
代码如下:
#前向传播
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
#获取loss
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(
*outs, img_metas=img_metas, cfg=proposal_cfg)
#返回loss和推荐列表
return losses, proposal_list
rpn的前向传播:
def forward_single(self, x):
"""Forward feature map of a single scale level."""
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred
一个3x3的卷积,之后接着两个1x1的卷积

卷积的channel在配置文件中有定义
rpn_head=dict(
type='RPNHead',
#输入卷积的通道
in_channels=256,
#3x3卷积的输出通道
feat_channels=256,
那么最终1x1卷积的输出通道是多少?
我们可以在代码中找到:
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_base_priors * self.cls_out_channels,
1)
self.rpn_reg = nn.Conv2d(self.feat_channels,
self.num_base_priors * 4,
1)
num_base_priors = num(anchor_scales)*num(anchor_ratios)
我们的anchor_scale为[8],num(anchor_scale)=1,anchor_ratios我们使用三种比例,最终的num_base_priors = 3
cls_out_channels:分类的种类
anchor
接下来是anchor的表演时间了
anchor_generator的配置文件如下:
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
strides就是传来的P2,P3,P4,P5,P6的感受野,也就是每一层特征图上的一个像素点对应原图上的像素个数,如果anchor的长宽没有定义,这个值也代表anchor的基础长宽,ratios表示是anchor的3种比例,scales对应anchor的长宽放大倍数
在rpn_body执行结束之后,进入loss中
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device)
首先获得所有的anchor,例如P2生成的anchor为(2002003,4),vaild表示这个anchor是否有效,超出图像范围即为无效
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels)
将所有的anchor和ground_truth进行匹配
loss计算完成之后,获取bbox,得到rpn_proposal,配置文件为:
rpn_proposal=dict(
#每一层都取2000个proposol
nms_pre=2000,
# 每张图最终的数量
max_per_img=1000,
#使用的nms
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
代码解析:
def _get_bboxes_single(self,
cls_score_list,
bbox_pred_list,
score_factor_list,
mlvl_anchors,
img_meta,
cfg,
rescale=False,
with_nms=True,
**kwargs):
cfg = self.test_cfg if cfg is None else cfg
cfg = copy.deepcopy(cfg)
img_shape = img_meta['img_shape']
#不同层的bbox在nms的时候应该是区分开的
level_ids = []
mlvl_scores = []
mlvl_bbox_preds = []
mlvl_valid_anchors = []
nms_pre = cfg.get('nms_pre', -1)
#分别处理P2-P6层
for level_idx in range(len(cls_score_list)):
rpn_cls_score = cls_score_list[level_idx]
rpn_bbox_pred = bbox_pred_list[level_idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.reshape(-1)
scores = rpn_cls_score.sigmoid()
else:
rpn_cls_score = rpn_cls_score.reshape(-1, 2)
scores = rpn_cls_score.softmax(dim=1)[:, 0]
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1, 4)
anchors = mlvl_anchors[level_idx]
if 0 < nms_pre < scores.shape[0]:
#将proposal按照分数排列
ranked_scores, rank_inds = scores.sort(descending=True)
#提取出前{nms_pre}个proposal
topk_inds = rank_inds[:nms_pre]
scores = ranked_scores[:nms_pre]
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
mlvl_scores.append(scores)
mlvl_bbox_preds.append(rpn_bbox_pred)
mlvl_valid_anchors.append(anchors)
level_ids.append(
scores.new_full((scores.size(0), ),
level_idx,
dtype=torch.long))
#将所有的bbox缩放到图像大小,之后一起做nms,返回{max_per_img}个proposal
return self._bbox_post_process(mlvl_scores, mlvl_bbox_preds,
mlvl_valid_anchors, level_ids, cfg,
img_shape)
至此rpn结束
roi_head
roi head 包含几步:
1.对之前的proposal进行assigner操作和sample操作
bbox assigner
bbox assigner是Head模块中重要的组件,负责对bbox(为anchor或者为proposal)进行正负样本分配策略,即确定哪个bbox为正样本,哪个bbox为负样本。
assigner=dict(
type='MaxIoUAssigner',
#与所有gt最大的iou>pos_iou_thr的是正样本
pos_iou_thr=0.7,
#与所有gt最大的iou
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
#正样本比例,不足用负样本补齐
pos_fraction=0.5,
neg_pos_ub=-1,
#添加gt到proposal与否
add_gt_as_proposals=False),
我们使用MaxIoUAssigner分类器,它是一个可以给gt分配多个bbox的分类器
MaxIoUAssigner一共有以下6个步骤:
- 计算所有bbox与所有gt的iou。
- 计算所有bbox与所有gt_ignore的iof,若某个bbox与所有gt_ignore的iof大于ignore_iof_thr ,则把该bbox与所有gt的iou都设为-1。
- 初始化,把所有bbox设置为ignore忽略样本,assigned_gt_inds赋值为-1。
- 获得每个bbox的最近的gt(即argmax gt),若某个bbox与最近的gt的iou(即max iou)都小于neg_iou_thr,那么设置为负样本,assigned_gt_inds赋值为0。
- 若某个bbox与最近的gt的iou(即max iou)大于pos_iou_thr,那么设置为正样本,assigned_gt_inds赋值为该bbox最近的gt(argmax gt)的下标+1,(范围为1~len(gts))。
- (可选步骤,match_low_quality为True),为什么要这步操作呢?因为可能存在某些gt没有被正样本匹配到,这时我们放宽限制。先对每个gt获得最近的bbox,若某个gt与最近bbox的iou大于min_pos_iou,那么该最近bbox(即argmax bbox)设置为gt的下标+1。若与该gt最近的bbox有多个时,我们可以根据gt_max_assign_all确定是否对所有最近bbox还是某个最近bbox赋值。
代码如下:
def assign(self, bboxes, gt_bboxes, gt_bboxes_ignore=None, gt_labels=None):
#gt太大的时候,放在cpu中计算,节约现存
assign_on_cpu = True if (self.gpu_assign_thr > 0) and (
gt_bboxes.shape[0] > self.gpu_assign_thr) else False
if assign_on_cpu:
device = bboxes.device
bboxes = bboxes.cpu()
gt_bboxes = gt_bboxes.cpu()
if gt_bboxes_ignore is not None:
gt_bboxes_ignore = gt_bboxes_ignore.cpu()
if gt_labels is not None:
gt_labels = gt_labels.cpu()
#1.计算所有bbox与所有gt的iou
overlaps = self.iou_calculator(gt_bboxes, bboxes)
#2.计算所有bbox与所有gt_ignore的iof,将所有符合条件的bbox与所有gt的iou设为-1
if (self.ignore_iof_thr > 0 and gt_bboxes_ignore is not None
and gt_bboxes_ignore.numel() > 0 and bboxes.numel() > 0):
#判断前后景是谁
if self.ignore_wrt_candidates:
ignore_overlaps = self.iou_calculator(
bboxes, gt_bboxes_ignore, mode='iof')
ignore_max_overlaps, _ = ignore_overlaps.max(dim=1)
else:
ignore_overlaps = self.iou_calculator(
gt_bboxes_ignore, bboxes, mode='iof')
ignore_max_overlaps, _ = ignore_overlaps.max(dim=0)
overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1
#剩下的几步
assign_result = self.assign_wrt_overlaps(overlaps, gt_labels)
#转移回cpu
if assign_on_cpu:
assign_result.gt_inds = assign_result.gt_inds.to(device)
assign_result.max_overlaps = assign_result.max_overlaps.to(device)
if assign_result.labels is not None:
assign_result.labels = assign_result.labels.to(device)
return assign_result
def assign_wrt_overlaps(self, overlaps, gt_labels=None):
num_gts, num_bboxes = overlaps.size(0), overlaps.size(1)
# 3. 把所有bbox设置为ignore忽略样本(-1)
assigned_gt_inds = overlaps.new_full((num_bboxes, ),
-1,
dtype=torch.long)
if num_gts == 0 or num_bboxes == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = overlaps.new_zeros((num_bboxes, ))
if num_gts == 0:
# No truth, assign everything to background
assigned_gt_inds[:] = 0
if gt_labels is None:
assigned_labels = None
else:
assigned_labels = overlaps.new_full((num_bboxes, ),
-1,
dtype=torch.long)
return AssignResult(
num_gts,
assigned_gt_inds,
max_overlaps,
labels=assigned_labels)
#对于每一个bbox,根据iou取max得出最佳匹配的gt和下标
max_overlaps, argmax_overlaps = overlaps.max(dim=0)
#对于每一个gt,根据iou取max选出最佳匹配的bbox和下标
gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
#4.将所有和最佳匹配的0
if isinstance(self.neg_iou_thr, float):
assigned_gt_inds[(max_overlaps >= 0)
& (max_overlaps < self.neg_iou_thr)] = 0
elif isinstance(self.neg_iou_thr, tuple):
assert len(self.neg_iou_thr) == 2
assigned_gt_inds[(max_overlaps >= self.neg_iou_thr[0])
& (max_overlaps < self.neg_iou_thr[1])] = 0
#5.分配正样本
pos_inds = max_overlaps >= self.pos_iou_thr
assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
#6.处理低匹配度
if self.match_low_quality:
for i in range(num_gts):
if gt_max_overlaps[i] >= self.min_pos_iou:
if self.gt_max_assign_all:
max_iou_inds = overlaps[i, :] == gt_max_overlaps[i]
assigned_gt_inds[max_iou_inds] = i + 1
else:
assigned_gt_inds[gt_argmax_overlaps[i]] = i + 1
if gt_labels is not None:
assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
pos_inds = torch.nonzero(
assigned_gt_inds > 0, as_tuple=False).squeeze()
if pos_inds.numel() > 0:
assigned_labels[pos_inds] = gt_labels[
assigned_gt_inds[pos_inds] - 1]
else:
assigned_labels = None
return AssignResult(
num_gts, assigned_gt_inds, max_overlaps, labels=assigned_labels)
sampler就比较简单了,从之前的结果中随机选取512个,选择25%的正样本,剩下的是负样本
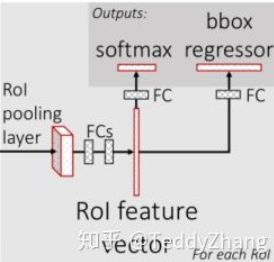
roi_head
roi_head的配置如下:
roi_head=dict(
type='StandardRoIHead',
# 这个组件是用于bbox_head之前的特征提取器,这个提取器把bbox的特征从单张的特征图提取出来,fpn之类的多张特征图需要多次映射
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
# 需要映射的featmap尺度, 这里取得是P2-P5层 这4层
featmap_strides=[4, 8, 16, 32]),
# roi的后续卷积全连接和预测
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=200,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
之后就是比较简单的全连接和卷积了,这里就只放一下别人画的图了
完结撒花