mmdetection各模块拆解(二)一阶段检测模型的构建(以FCOS为例)
一阶段检测模型的构建(以FCOS为例)
- 引言
- 一阶段检测模型的构成
- mmdet中的FCOS模型构建
-
- 方法介绍
- mmdet模型一般构建过程
- FCOS
- SingleStageDetector
- Backbone and Neck
-
- backbone:Resnet
- neck:FPN
- bbox_head
-
- BaseDenseHead
- AnchorFreeHead
- FCOSHead
-
- 初始化
- 前向传播
- 预测目标(target)的生成
- loss的计算
- 小结
- 总结
引言
对于笔者来说,学习mmdetection最重要的就是学会如何DIY自己的模型,那么弄懂经典的模型是如何一步步搭建出来的就显得非常重要。本章将从零开始,解构一阶段检测模型(以FCOS为例)在mmdetection中的构建过程。本文在FCOS的具体代码部分有详细的讲解和注释,和笔者一样有DIY模型需求的同学可以仔细阅读哦~
一阶段检测模型的构成
一阶段检测模型(OneStageDetector)直接在提取到的特征图上进行目标位置和类别的密集预测。一阶段检测器的模型构成较为简单,关键组件为Backbone, Neck, Bbox_head 三部分:
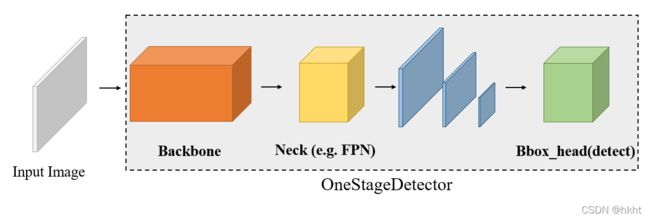
一般而言,不同一阶段检测模型的差异主要集中在检测头(bbox_head)和损失函数(loss)两部分,这两部分也是本章要讨论的重点。
mmdet中的FCOS模型构建
方法介绍
论文地址:FCOS: Fully Convolutional One-Stage Object Detection
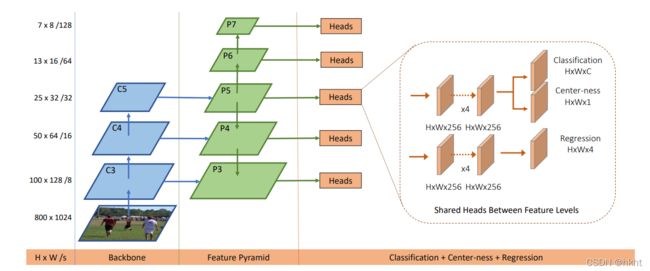
(上图来源于论文原文)
FCOS采用全卷积的网络结构,并且在检测头的分类分支上采取一条额外的中心预测支路来预测目标离中心的偏移程度,能够提升检测边框的质量。这是一篇很有意思的工作,关于模型的具体细节感兴趣的同学可自行阅读原文,本文主要讨论FCOS在mmdetection中的实现过程。
回到上文提到的一阶段检测模型结构“三要素”,FCOS在Backbone上没有特殊的要求,Neck使用的是检测任务中最常用的特征金字塔(FPN),其创新主要体现在bbox_head部分。
mmdet模型一般构建过程
在mmdetection/tools/train.py中,模型是这样构建的:
from mmdet.models import build_detector
"""可以看到,模型的构建取决于cfg.model,cfg.train_cfg,cfg.test_cfg 三个字典"""
model = build_detector(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
"""模型参数初始化"""
model.init_weights()
接下来我们看到FCOS的配置文件,笔者对重要的部分做了注释:
"""model部分"""
model = dict(
"""type指示模型的类(class)"""
type='FCOS',
"""指定backbone,backbone一般是模型中最灵活的部分,可以方便地替换为其他网络"""
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe',
init_cfg=dict(
type='Pretrained',
checkpoint='open-mmlab://detectron/resnet50_caffe')),
"""这里使用FPN做为neck,并指定了FPN的输入、输出通道数、是否使用relu等参数"""
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output', # use P5
num_outs=5,
relu_before_extra_convs=True),
"""这里指定了bbox_head,可以看到type为'FCOShead',是FCOS的核心组件"""
bbox_head=dict(
type='FCOSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
"""loss归属于bbox_head部分,这里指定了检测头三个分支的损失函数"""
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
"""训练和测试的配置部分"""
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
配置文件的基本结构如下图所示,FCOShead为此模型的关键部分:
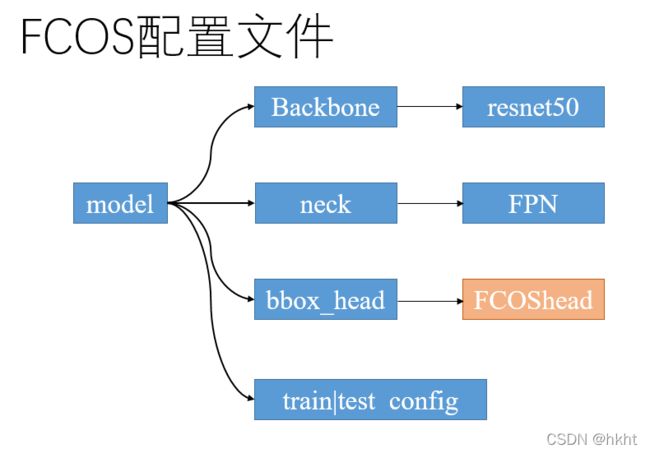
接下来看到检测模型的构建函数build_detector():
from mmcv.utils import Registry
MODELS = Registry('models', parent=MMCV_MODELS)
DETECTORS = MODELS
def build_detector(cfg, train_cfg=None, test_cfg=None):
"""Build detector."""
if train_cfg is not None or test_cfg is not None:
warnings.warn(
'train_cfg and test_cfg is deprecated, '
'please specify them in model', UserWarning)
assert cfg.get('train_cfg') is None or train_cfg is None, \
'train_cfg specified in both outer field and model field '
assert cfg.get('test_cfg') is None or test_cfg is None, \
'test_cfg specified in both outer field and model field '
return DETECTORS.build(
cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
DETECTORS是mmcv的一个注册表实例,DETECTORS.build(cfg)为按照cfg给定的模型类别(关键字’type’)来实例化一个模型。在本例中,模型的类别为 type=‘FCOS’,那么此函数将会构建并返回一个FCOS模型。
FCOS
我们在 mmdetection/mmdet/models/detectors/fcos.py找到FCOS类别的定义:
# Copyright (c) OpenMMLab. All rights reserved.
from ..builder import DETECTORS
from .single_stage import SingleStageDetector
@DETECTORS.register_module()
class FCOS(SingleStageDetector):
"""Implementation of `FCOS `_"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(FCOS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained, init_cfg)
出乎意料,FCOS的定义非常简单,就是继承了SingleStageDetector并做实例化而已。
SingleStageDetector
下面来看一下SingleStageDetector吧,这里同样对重点部分做了一些注释:
@DETECTORS.register_module()
class SingleStageDetector(BaseDetector):
"""一阶段检测器的基类
一阶段检测器在backbone+neck的输出上直接进行密集的边界框预测
"""
def __init__(self,
backbone,
neck=None,
bbox_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(SingleStageDetector, self).__init__(init_cfg)
if pretrained:
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
backbone.pretrained = pretrained
"""创建backbone,build函数作用与build_detecor相同"""
self.backbone = build_backbone(backbone)
if neck is not None:
"""创建neck, 检测中一般使用FPN及其各种变体"""
self.neck = build_neck(neck)
bbox_head.update(train_cfg=train_cfg)
bbox_head.update(test_cfg=test_cfg)
"""创建bbox_head"""
self.bbox_head = build_head(bbox_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
"""特征提取"""
def extract_feat(self, img):
"""使用backbone和neck提取特征"""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def forward_dummy(self, img):
"""前向传播算法 x ---> backbone+neck ---> feat ---> bbox_head ---> outs"""
x = self.extract_feat(img)
outs = self.bbox_head(x)
return outs
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
"""
参数:
img (Tensor): 输入图片,形状为(N,C,H,W),一般来说应当是归一化后的图片.
img_metas (list[dict]): 包含'image_scale','flip','filename','ori_shape'等元信息的字典列表
gt_bboxes (list[Tensor]): 边界框真实标注,形状为(xmin,ymin,xmax,ymax).
gt_labels (list[Tensor]): 边界框的类别
gt_bboxes_ignore (None | list[Tensor]): 指定在计算损失时可以被忽略的边界框.
返回值:
dict[str, Tensor]: 包含多个损失函数的字典.
"""
super(SingleStageDetector, self).forward_train(img, img_metas)
"""提取特征,并用bbox_head的前向传播函数得到损失"""
x = self.extract_feat(img)
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
以上是SingleStageDetector的训练部分,下面看到测试部分:
def simple_test(self, img, img_metas, rescale=False):
"""没有测试阶段数据增强的简单测试函数
参数:
rescale (bool, optional): 是否将检测结果放缩到原有的大小,默认为False.
返回值:
list[list[np.ndarray]]: 每张图片中每一个类别的检测结果,第一个list维度代表不同的图片,第二个list维度代表不同的类别.
"""
"""提取特征并使用bbox_head的simple_test函数进行测试"""
feat = self.extract_feat(img)
results_list = self.bbox_head.simple_test(
feat, img_metas, rescale=rescale)
"""使用bbox2result函数处理检测结果并返回"""
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in results_list
]
return bbox_results
def aug_test(self, imgs, img_metas, rescale=False):
"""与simple_test函数基本一致,只是在测试时使用了数据增强
"""
assert hasattr(self.bbox_head, 'aug_test'), \
f'{self.bbox_head.__class__.__name__}' \
' does not support test-time augmentation'
feats = self.extract_feats(imgs)
"""使用bbox_head的aug_test函数"""
results_list = self.bbox_head.aug_test(
feats, img_metas, rescale=rescale)
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in results_list
]
return bbox_results
通过对SingleStageDetector类代码的分析可以得知,在前向传播和测试等关键步骤中,均使用了bbox_head的训练和测试函数,可见对于一阶段检测模型而言,bbox_head就是最重要的组成部分。
Backbone and Neck
这里只对backbone和neck做一些简单的介绍。
backbone:Resnet
backbone即骨干网络,一般由大量的卷积、池化、归一化、激活层等排列而成,常用于图像特征的提取。在本文中,FCOS使用最经典的resnet50做为骨干网络。在mmdetection中,骨干网络同检测模型中的其他组件一样,也需要进行类的编写和注册:
"""
codes from mmdet/models/bakcbones/resnet.py
"""
@BACKBONES.register_module()
class ResNet(BaseModule):
"""ResNet backbone."""
Resnet的用法非常简单,接受形状为(N,C,H,W)的图片输入,并返回4个stage的输出。这里给出官方的一个例子:
from mmdet.models import ResNet
import torch
m = ResNet(18)
m.eval()
input = torch.rand((1,3,32,32))
level_outputs = m.forward(input)
for level_output in level_outputs:
print(level_output.shape)
得到的结果为:
torch.Size([1, 64, 8, 8])
torch.Size([1, 128, 4, 4])
torch.Size([1, 256, 2, 2])
torch.Size([1, 512, 1, 1])
neck:FPN
特征金字塔网络是检测任务中最常用的neck结构,主要用于多尺度信息的融合:
@NECKS.register_module()
class FPN(BaseModule):
FPN接受多个不同尺度的输入,返回一个包含相同通道数的不同尺度特征的元组:
from mmdet.models import ResNet
from mmdet.models import FPN
import torch
m = ResNet(18)
m.eval()
input = torch.rand((1,3,32,32))
level_outputs = m.forward(input)
in_channels = [64,128,256,512]
fpn = FPN(in_channels=in_channels,out_channels=256,num_outs=len(level_outputs))
fpn.eval()
outputs = fpn.forward(level_outputs)
for output in outputs:
print(output.shape)
上述测试代码得到的结果为:
torch.Size([1, 256, 8, 8])
torch.Size([1, 256, 4, 4])
torch.Size([1, 256, 2, 2])
torch.Size([1, 256, 1, 1])
可见所有的输入的通道数均被处理成256.
bbox_head
终于到了本文的重头戏了,下面对mmdetection中的一阶段检测头进行详细的分析。
首先我们要知道的是,在mmdetection中FCOS检测器遵循如下的类别继承关系:

BaseDenseHead
此类为密集检测头的基类,所有在特征图上直接进行预测的头(包括一阶段检测器和RPN) 从根源上都继承于此类,下面来看一下代码与笔者的注释,源代码见mmdet/models/dense_heads/base_dense_head.py
"""此类别为抽象类"""
class BaseDenseHead(BaseModule, metaclass=ABCMeta):
"""Base class for DenseHeads."""
def __init__(self, init_cfg=None):
super(BaseDenseHead, self).__init__(init_cfg)
"""此类别包含loss和get_bboxes两个抽象方法,子类必须进行复写"""
@abstractmethod
def loss(self, **kwargs):
"""计算检测头的损失."""
pass
@abstractmethod
def get_bboxes(self, **kwargs):
"""将检测头的批次输出转换为边框预测."""
pass
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): 来自特征金字塔的不同尺度输入.
img_metas (list[dict]): 图片的元信息.
gt_bboxes (Tensor): 边界框真实值,形状为(N,4)
gt_labels (Tensor): 边界框的真实类别标签,形状为(N,)
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): 损失函数字典.
proposal_list (list[Tensor]): 每张图片上产生的proposal.
"""
outs = self(x)
"""若给定了gt_labels 将类别标签加入到损失函数的计算中"""
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
"""计算损失函数"""
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
# 返回损失函数字典和(如果需要)生成的proposal
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
def simple_test(self, feats, img_metas, rescale=False):
"""简易的测试函数.
Returns:
list[tuple[Tensor, Tensor]]: 列表中的每一项是长度为2的元组。元组中第一个张量
形状为(N,5), 维度5代表 (tl_x, tl_y, br_x, br_y, score).第二个张量为类别预测结果,
其张量的形状为(N,)
"""
return self.simple_test_bboxes(feats, img_metas, rescale=rescale)
BaseDenseHead为抽象类,其子类必须复写loss()和get_bboxes()两个抽象方法。
AnchorFreeHead
Anchor-free方法指在检测中不事先设定好指定大小的锚框,而是直接进行目标位置的预测。下面先看一下AnchorFreeHead类别的初始化函数:
from abc import abstractmethod
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule
from mmcv.runner import force_fp32
from mmdet.core import multi_apply
from ..builder import HEADS, build_loss
from .base_dense_head import BaseDenseHead
"""初始化函数的参数很多,这里把对每一个参数都做了简单的注释"""
@HEADS.register_module()
class AnchorFreeHead(BaseDenseHead, BBoxTestMixin):
"""Anchor-free head (FCOS, Fovea, RepPoints, etc.).
""" # noqa: W605
_version = 1
def __init__(self,
num_classes, # 检测类别数(不包括背景类)
in_channels, # 输入特征图的通道数
feat_channels=256, # 隐藏层的通道数
stacked_convs=4, # 检测头堆叠的卷积层数
strides=(4, 8, 16, 32, 64), # 不同尺度特征的下采样系数
dcn_on_last_conv=False, # 是否在最后一层卷积层中使用DCN
conv_bias='auto', # 卷积层是否使用偏置,"auto"代表由norm_cfg决定
loss_cls=dict( # 分类的损失函数,默认为FocalLoss
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0), #边框回归的损失,默认为IouLoss
conv_cfg=None,
norm_cfg=None,
train_cfg=None,
test_cfg=None,
init_cfg=dict( # 初始化配置
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='conv_cls',
std=0.01,
bias_prob=0.01))):
super(AnchorFreeHead, self).__init__(init_cfg)
self.num_classes = num_classes
self.cls_out_channels = num_classes
self.in_channels = in_channels
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.strides = strides
self.dcn_on_last_conv = dcn_on_last_conv
assert conv_bias == 'auto' or isinstance(conv_bias, bool)
self.conv_bias = conv_bias
"""构建损失函数"""
self.loss_cls = build_loss(loss_cls)
self.loss_bbox = build_loss(loss_bbox)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.fp16_enabled = False
初始化各层
self._init_layers()
def _init_layers(self):
"""初始化检测头的各层."""
self._init_cls_convs()
self._init_reg_convs()
self._init_predictor()
AnchorFreeHead检测头的组成如下图:
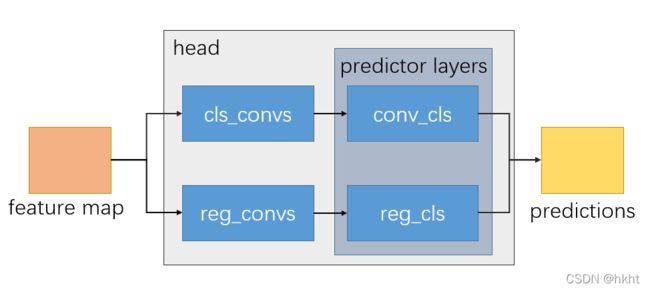
下面看一下各层的初始化函数:
def _init_cls_convs(self):
"""初始化分类卷积层."""
self.cls_convs = nn.ModuleList()
"""分类部分层数由self.stacked_convs参数决定"""
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
if self.dcn_on_last_conv and i == self.stacked_convs - 1:
conv_cfg = dict(type='DCNv2')
else:
conv_cfg = self.conv_cfg
"""这里的ConvModule是mmcv中封装的卷积-归一化-激活层,激活函数默认使用ReLU"""
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.conv_bias))
def _init_reg_convs(self):
"""边框回归层的初始化,代码与_init_cls_convs类似."""
self.reg_convs = nn.ModuleList()
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
if self.dcn_on_last_conv and i == self.stacked_convs - 1:
conv_cfg = dict(type='DCNv2')
else:
conv_cfg = self.conv_cfg
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.conv_bias))
def _init_predictor(self):
"""初始化预测层."""
"""conv_cls的输出通道数为self.cls_out_channels=num_classes,即为类别数"""
self.conv_cls = nn.Conv2d(
self.feat_channels, self.cls_out_channels, 3, padding=1)
"""conv_reg的输出通道数为4,对应边框的4个坐标参数"""
self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
再看到前向传播函数:
def forward(self, feats):
"""前向传播函数.
Args:
feats (tuple[Tensor]): 从上游的网络中得到的特征图,tuple中每一个tensor表示不同
尺度的特征.
Returns:
tuple: 通常包括分类置信度得分和边界框预测结果.
cls_scores (list[Tensor]): 对于不同尺度特征图的分类预测结果,特征图通道数为num_points(预测点数)*num_classes(类别数),即对每一点的每一个类别都进行预测.
bbox_preds (list[Tensor]): 不同尺度特征图的边框偏移量,通道数为num_points*4
"""
"""multi_apply能将输入的参数函数作用到feats中的每个项上"""
return multi_apply(self.forward_single, feats)[:2]
def forward_single(self, x):
"""对单个特征层处理的前向传播函数.
Args:
x (Tensor): FPN feature maps of the specified stride.
Returns:
tuple: 每个类别的置信度得分, 边框预测, 经过cls_convs和reg_convs处理后的特征.
"""
cls_feat = x
reg_feat = x
"""得到分类置信度"""
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
cls_score = self.conv_cls(cls_feat)
"""得到边框预测值"""
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)
bbox_pred = self.conv_reg(reg_feat)
return cls_score, bbox_pred, cls_feat, reg_feat
可以看到AnchorFreeHead的前向传播过程是比较简单的。下面看一下损失函数的计算和测试结果的处理:
"""loss是抽象类方法,意味着具体的模型需要自己定义损失函数"""
@abstractmethod
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""计算检测头的损失函数.
Args:
cls_scores (list[Tensor]): 对于不同尺度特征图的分类预测结果.
bbox_preds (list[Tensor]): 对于不同尺度特征图的边框预测结果.
gt_bboxes (list[Tensor]): 待检测目标边界框真实值.
gt_labels (list[Tensor]): 各边框的类别真实值
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
"""
raise NotImplementedError
@abstractmethod
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def get_bboxes(self,
cls_scores,
bbox_preds,
img_metas,
cfg=None,
rescale=None):
"""这个函数在BaseDenseHead中也见过,也是抽象方法,不多赘述.
"""
raise NotImplementedError
@abstractmethod
def get_targets(self, points, gt_bboxes_list, gt_labels_list):
"""计算分类、回归等任务的预测目标(target),用于损失函数的计算.
Args:
points (list[Tensor]): 特征金字塔每一层的定位点,列表中每一项为(num_points,2).
gt_bboxes_list (list[Tensor]): 真实边框信息,
每一项的形状为 (num_gt, 4).
gt_labels_list (list[Tensor]): 边框的真实类别标签,
每一项的形状为 (num_gt,).
"""
raise NotImplementedError
因为在AnchorFreeHead中不使用Anchor box,我们一般采用定位点的方式作为锚点来计算要预测的目标值,进而计算损失函数并得到预测的边框。定位点的生成方式如下:
def _get_points_single(self,
featmap_size,
stride,
dtype,
device,
flatten=False):
"""获取单一尺度特征图的定位点."""
h, w = featmap_size
"""生成x,y维度的坐标,每个特征图点设为一个定位点"""
x_range = torch.arange(w, device=device).to(dtype)
y_range = torch.arange(h, device=device).to(dtype)
"""使用meshgrid函数生成二维坐标"""
y, x = torch.meshgrid(y_range, x_range)
"""是否展开成一维向量"""
if flatten:
y = y.flatten()
x = x.flatten()
return y, x
def get_points(self, featmap_sizes, dtype, device, flatten=False):
"""为多尺度特征图生成定位点.
Args:
featmap_sizes (list[tuple]): 多尺度特征图的尺寸.
dtype (torch.dtype): 数据类型.
device (torch.device): 计算硬件(cpu or gpu).
Returns:
tuple: 每个特征图的定位点.
"""
mlvl_points = []
for i in range(len(featmap_sizes)):
mlvl_points.append(
self._get_points_single(featmap_sizes[i], self.strides[i],
dtype, device, flatten))
return mlvl_points
这里举例简要给大家介绍一下torch.meshgrid()函数的用法:
import torch
""" meshgrid函数用于生成多维的坐标点
"""
w = 5
h = 5
x_range = torch.arange(w)
y_range = torch.arange(h)
y,x = torch.meshgrid(y_range,x_range)
print(y)
"""
results:
生成了5X5的二维坐标,tensor y代表每一个点的y坐标值
tensor([[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4]])
"""
总结一下AnchorFreeHead中的几个组成部分:
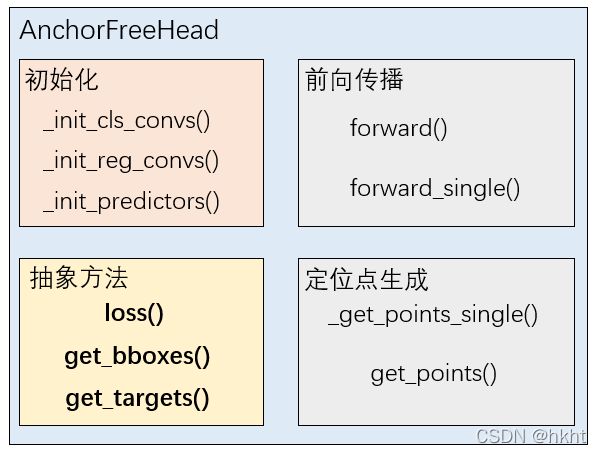
FCOSHead
下面讲解FCOSHead的代码部分,会涉及到FCOS的模型构建细节,感兴趣的同学可以先看看文章。
初始化
先看到FCOSHead的初始化部分:
@HEADS.register_module()
class FCOSHead(AnchorFreeHead):
def __init__(self,
num_classes,# 类别数(不包括背景)
in_channels, # 输入特征图的通道数
regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),
(512, INF)), # 多尺度定位点的回归范围(实际上就是将某一点的回归限定到某一层)
center_sampling=False,
center_sample_radius=1.5,
norm_on_bbox=False,
centerness_on_reg=False,
loss_cls=dict( # 分类损失,默认为Focal Loss
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),# 回归损失
loss_centerness=dict( # 中心预测损失
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True),
init_cfg=dict(
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='conv_cls',
std=0.01,
bias_prob=0.01)),
**kwargs):
self.regress_ranges = regress_ranges
self.center_sampling = center_sampling
self.center_sample_radius = center_sample_radius
self.norm_on_bbox = norm_on_bbox
self.centerness_on_reg = centerness_on_reg
super().__init__(
num_classes,
in_channels,
loss_cls=loss_cls,
loss_bbox=loss_bbox,
norm_cfg=norm_cfg,
init_cfg=init_cfg,
**kwargs)
self.loss_centerness = build_loss(loss_centerness) #构建中心预测损失函数
def _init_layers(self):
"""初始化各层.
首先调用父类AnchorFreeHead的初始化函数,获得self.conv_cls,self.conv_reg, self.cls_convs,
self.reg_convs, self.loss_cls, self.loss_bbox等网络和损失函数部件
"""
super()._init_layers()
"""使用一层卷积预测中心概率值"""
self.conv_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
前向传播
再看到前向传播:
def forward(self, feats):
"""前向传播.
"""
return multi_apply(self.forward_single, feats, self.scales,
self.strides)
def forward_single(self, x, scale, stride):
"""单尺度特征图的前向传播.
"""
"""这里首先使用父类的前向传播函数,得到cls_score, bbox_pred, cls_feat, reg_feat"""
cls_score, bbox_pred, cls_feat, reg_feat = super().forward_single(x)
"""根据参数指定在哪个特征图上进行中心概率值的预测"""
if self.centerness_on_reg:
centerness = self.conv_centerness(reg_feat)
else:
centerness = self.conv_centerness(cls_feat)
# scale the bbox_pred of different level
# float to avoid overflow when enabling FP16
bbox_pred = scale(bbox_pred).float()
"""因为bbox_pred理论上均为非负,因此使用ReLU或者exp保持非负性"""
if self.norm_on_bbox:
bbox_pred = F.relu(bbox_pred)
if not self.training:
bbox_pred *= stride
else:
bbox_pred = bbox_pred.exp()
"""返回分类得分,边框预测,以及中心值预测"""
return cls_score, bbox_pred, centerness
预测目标(target)的生成
损失函数衡量的是预测值和真实值的差异:
L = ( p r e d , t a r g e t ) L = (pred,target) L=(pred,target)
对于分类任务,真实值就是目标所属的类别标签。然而对于边框回归而言,不同的模型通常会回归不同的目标,而且target与尺度有关,这也是检测模型代码编写的最大难点之一。
FCOS是直接在特征图各定位点上进行直接预测,那就先来看看FCOSHead是如何生成定位点的:
def _get_points_single(self,
featmap_size,
stride,
dtype,
device,
flatten=False):
"""首先调用父类AnchorFreeHead的函数生成基本点"""
y, x = super()._get_points_single(featmap_size, stride, dtype, device)
"""将两维度的坐标堆叠到一起,此时points的形状为(h*w,2),并利用stride信息将其转化为中心点并映射到
原来的图像中。
"""
points = torch.stack((x.reshape(-1) * stride, y.reshape(-1) * stride),
dim=-1) + stride // 2
return points
用一张图可以清晰地展示这个函数的功能:

然后看到_get_target_single()函数:
def _get_target_single(self, gt_bboxes, gt_labels, points, regress_ranges,
num_points_per_lvl):
"""为单张图片(注意是单张图片,考虑batch_size,不是单个尺度特征图).
不同尺度的特征图有不同数量的特征点,自然会生成不同数量的定位点,这里用num_points1,num_points2,
...,num_points5来表示(递减)。记录和为sum_points=num_points1 + num_points2 +...+num_points5
Args:
gt_bboxes(Tensor): 形状为(num_gts,4)
gt_labels(Tensor): 形状为(num_gts,)
points(Tensor): 所有尺度特征图的点,形状为(sum_points,2)
regress_ranges(Tensor):所有尺度特征图的点对应的回归范围,形状同points
num_points_per_level()
"""
num_points = points.size(0)
num_gts = gt_labels.size(0)
"""若没有gt_bboxes,返回0值"""
if num_gts == 0:
return gt_labels.new_full((num_points,), self.num_classes), \
gt_bboxes.new_zeros((num_points, 4))
"""计算gt_bboxes的面积"""
areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * (
gt_bboxes[:, 3] - gt_bboxes[:, 1])
# TODO: figure out why these two are different
# areas = areas[None].expand(num_points, num_gts)
"""将areas进行扩展,areas[None]表示在最前面加一个维度,此步完成后areas的形状为(num_points,num_gts)"""
areas = areas[None].repeat(num_points, 1)
"""将regress_ranges进行扩展,最终维度为(num_points,num_gts,2)"""
regress_ranges = regress_ranges[:, None, :].expand(
num_points, num_gts, 2)
"""将gt_bboxes进行扩展,最终维度也为(num_points,num_gts,4)"""
gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
"""获取生成定位点的x,y坐标,并将其均扩展为形状(num_points,num_gts)"""
xs, ys = points[:, 0], points[:, 1]
xs = xs[:, None].expand(num_points, num_gts)
ys = ys[:, None].expand(num_points, num_gts)
"""获取每个生成点对每一个gt_bbox的回归目标
这里解释一下为什么上面要将各个张量的前两个维度都扩展为(num_points,num_gts),就是为了让每一个
生成定位点都与每一个gt_boox计算回归的误差,然后再进行回归任务的分配
这里计算的是中心点到gt_bbox上下左右的差值。
"""
left = xs - gt_bboxes[..., 0]
right = gt_bboxes[..., 2] - xs
top = ys - gt_bboxes[..., 1]
bottom = gt_bboxes[..., 3] - ys
"""将四个维度的回归目标结合,注意stack函数会增加维度,dim=-1导致最终获得的
bbox_targets形状为(num_points,num_gts,4),也就是每个点对每个gt_bbox的密集计算
"""
bbox_targets = torch.stack((left, top, right, bottom), -1)
"""下面将决定哪些bbox_targets可以作为训练的正样本"""
"""1.如果center_sampling==True,即从中心点以radius*stride的范围进行采样(也就是中心点附近),在其中的视为正样本"""
if self.center_sampling:
# condition1: inside a `center bbox`
"""这里半径默认为1.5"""
radius = self.center_sample_radius
"""计算gt_bbox的中心点位置,center_xs,center_ys的形状均为(num_points,num_gts)"""
center_xs = (gt_bboxes[..., 0] + gt_bboxes[..., 2]) / 2
center_ys = (gt_bboxes[..., 1] + gt_bboxes[..., 3]) / 2
center_gts = torch.zeros_like(gt_bboxes)
stride = center_xs.new_zeros(center_xs.shape)
"""将不同尺度特征图上的点投影到原有的大小"""
lvl_begin = 0
for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
lvl_end = lvl_begin + num_points_lvl
"""将原有的stride扩展1.5倍"""
stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius
lvl_begin = lvl_end
"""根据中心点和stride确定正样本的选取范围(xmin,ymin,xmax,ymax)"""
x_mins = center_xs - stride
y_mins = center_ys - stride
x_maxs = center_xs + stride
y_maxs = center_ys + stride
"""torch.where(condition,a,b),条件成立的位置取a值,不成立的位置取b值.
这里四段代码的作用是,保持正样本点同时满足两个条件:
1. 在中心采样范围内:(xmin,ymin,xmax,ymax)
2. 在gt_bboxes得范围内:gt_bboxes
所以会在x_mins和gt_bbox[0]取最大值,在x_max和gt_bbox[2]中取最小值
"""
center_gts[..., 0] = torch.where(x_mins > gt_bboxes[..., 0],
x_mins, gt_bboxes[..., 0])
center_gts[..., 1] = torch.where(y_mins > gt_bboxes[..., 1],
y_mins, gt_bboxes[..., 1])
center_gts[..., 2] = torch.where(x_maxs > gt_bboxes[..., 2],
gt_bboxes[..., 2], x_maxs)
center_gts[..., 3] = torch.where(y_maxs > gt_bboxes[..., 3],
gt_bboxes[..., 3], y_maxs)
"""最终得到的center_gts形状为(num_points,num_gts,4),其意义为规定参与回归的
正样本范围
"""
cb_dist_left = xs - center_gts[..., 0]
cb_dist_right = center_gts[..., 2] - xs
cb_dist_top = ys - center_gts[..., 1]
cb_dist_bottom = center_gts[..., 3] - ys
center_bbox = torch.stack(
(cb_dist_left, cb_dist_top, cb_dist_right, cb_dist_bottom), -1)
"""只有与在center_gts中的点,其mask才为正"""
inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0
else:
"""如果center_sampling=False,就简单地将gt_bbox中的点视为正样本点"""
inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
"""计算要回归的最大target,并根据ranges排除"""
max_regress_distance = bbox_targets.max(-1)[0]
inside_regress_range = (
(max_regress_distance >= regress_ranges[..., 0])
& (max_regress_distance <= regress_ranges[..., 1]))
"""将不在gt_bbox中的点对应的area设为极大"""
areas[inside_gt_bbox_mask == 0] = INF
areas[inside_regress_range == 0] = INF
"""如果一个点仍对应着多个gt_bbox,那么选取gt_bbox面积最小的做为回归目标"""
"""min_area_inds的形状为(num_points,),其中的元素代表gt_bbox的标签,num_pos_points表示
正样本数量.
"""
min_area, min_area_inds = areas.min(dim=1)
labels = gt_labels[min_area_inds]
"""将未能对应上任何一个gt_bbox的点设为背景样本点"""
labels[min_area == INF] = self.num_classes # set as BG
"""这里range(num_points) 和 min_area_inds 等长,表示每一个point最多只选取一个gt_bbox"""
bbox_targets = bbox_targets[range(num_points), min_area_inds]
"""最终的返回值:
labels(Tensor):shape (num_points,)
bbox_targets(Tensor): (num_points,4)
"""
return labels, bbox_targets
可以看到,_get_target_single函数的作用为:为单张图片选取符合条件的正样本点,并且计算出分类和回归的目标,用于后续损失函数的计算。
下面再看到get_targets函数:
def get_targets(,self, points, gt_bboxes_list, gt_labels_list):
"""为多张图片计算分类、回归和中心值预测的target
Args:
points (list[Tensor]): 每个特征层的定位点,list(Tensor(num_points,2))
gt_bboxes_list (list[Tensor]): 每个Tensor的形状为 (num_gt, 4).
gt_labels_list (list[Tensor]):每个Tensor的形状为 (num_gt, ).
Returns:
tuple:
concat_lvl_labels (list[Tensor]):. \
concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
level.
"""
assert len(points) == len(self.regress_ranges)
num_levels = len(points)
"""将regress_ranges扩展,与points的形状对齐"""
expanded_regress_ranges = [
points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
points[i]) for i in range(num_levels)
]
"""这里将所有的regress_ranges和points连接起来,与刚刚的_get_targets_single函数相对应.
concat_points形状为(h1*w1+h2*w2+...+h5*w5,4)"""
concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
concat_points = torch.cat(points, dim=0)
"""统计每层的定位点数量"""
num_points = [center.size(0) for center in points]
"""为每张图片生成labels(shape (num_all_points,))和bbox_targets(num_all_points,4),
并组成两个list"""
labels_list, bbox_targets_list = multi_apply(
self._get_target_single,
gt_bboxes_list,
gt_labels_list,
points=concat_points,
regress_ranges=concat_regress_ranges,
num_points_per_lvl=num_points)
"""此时num_points为一个列表,列表中元素为每一层生成的定位点数。下面的操作将每一张图片
中的points按照不同的level分开,等价于torch.split(labels,[num_lvl1,num_lvl2,...,num_lvl5],dim=0)
"""
labels_list = [labels.split(num_points, 0) for labels in labels_list]
bbox_targets_list = [
bbox_targets.split(num_points, 0)
for bbox_targets in bbox_targets_list
]
"""将不同的图片同一level的label和bbox_target连接起来"""
concat_lvl_labels = []
concat_lvl_bbox_targets = []
for i in range(num_levels):
"""concat_lvl_labels中的Tensor 形状为(num_points_leveli*num_imgs,)
concat_lvl_bbox_targets中Tensor 形状为(num_points_leveli*num_imgs,4)
"""
concat_lvl_labels.append(
torch.cat([labels[i] for labels in labels_list]))
bbox_targets = torch.cat(
[bbox_targets[i] for bbox_targets in bbox_targets_list])
if self.norm_on_bbox:
bbox_targets = bbox_targets / self.strides[i]
concat_lvl_bbox_targets.append(bbox_targets)
"""最终返回的为两个列表,列表中第一维度代表不同的level而不是不同的图片"""
return concat_lvl_labels, concat_lvl_bbox_targets
到这里为止,我们已经生成了分类和回归的target,但是不要忘记FCOS还有一个Centerness预测分支,主要负责衡量定位点和gt_bbox中心的偏移情况,这也是需要生成target的:
def centerness_target(self, pos_bbox_targets):
"""
Args:
pos_bbox_targets(Tensor):只计算正样本的中心偏移量,shape (num_pos_bbox,4)
"""
left_right = pos_bbox_targets[:, [0, 2]]
top_bottom = pos_bbox_targets[:, [1, 3]]
if len(left_right) == 0:
centerness_targets = left_right[..., 0]
else:
centerness_targets = (
left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * (
top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])
"""返回的形状为(num_pos_bbox,)"""
return torch.sqrt(centerness_targets)
centerness度量的计算方式如下: 可见当 l ∗ = r ∗ , t ∗ = b ∗ l^*=r^*,t^*=b^* l∗=r∗,t∗=b∗时,即点恰好位于中心时,centerness=1。
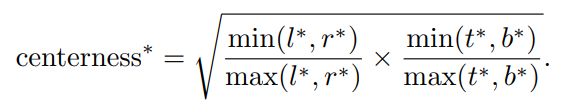
loss的计算
def loss(self,
cls_scores,
bbox_preds,
centernesses,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""计算 bbox_head的损失函数.
Args:
cls_scores (list[Tensor]): 每个level的类别置信度得分,
每一个Tensor的性状为(B,num_points*num_class,H,W).
bbox_preds (list[Tensor]): 每一个level的边框偏移量, Tensor形状为(B,num_points*4,H,W)
centernesses (list[Tensor]): 每一个level的"中心度"预测, 每一个的形状为(B,num_points,H,W).
gt_bboxes (list[Tensor]): 每张图片的真实目标边界框,shape (num_gts,4),(xmin,ymin,xmax,ymax)格式.
gt_labels (list[Tensor]): 每个gt_bbox的类别标签,shape (num_gts,)
Returns:
dict[str, Tensor]:返回一个字典,包含各个损失函数.
"""
assert len(cls_scores) == len(bbox_preds) == len(centernesses)
"""size()[-2:] 表示取H,W,这里表示取每一尺度级别特征图的大小"""
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
"""生成定位点"""
all_level_points = self.get_points(featmap_sizes, bbox_preds[0].dtype,
bbox_preds[0].device)
"""根据定位点和真实标签生成预测目标,这里的labels和bbox_targets均为列表,列表中第一个维度表示不同的
特征尺度。
"""
labels, bbox_targets = self.get_targets(all_level_points, gt_bboxes,
gt_labels)
"""统计要同时处理的图片的数量,也就是batch_size"""
num_imgs = cls_scores[0].size(0)
"""
这里以flatten_cls_score为例解释:在计算损失函数时,原本4D的Tensor不适于计算,因此需要先将他们展开。
在cls_scores中,每一个cls_score表示一个level中conv_cls得到的类别预测结果,
shape = (B,num_points(1)*num_classes,H,W). 首先使用permute(0,2,3,1)j将形状变为(B,H,W,num_classes),
然后继续reshape(-1,self.cls_out_channels),最终的形状为(H*W*num_classes,self.cls_out_channels),也就是
把每一个点的预测结果都线性排列在一起
flatten_bbox_preds,flatten_centerness的处理方式同理。
"""
flatten_cls_scores = [
cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
for cls_score in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
for bbox_pred in bbox_preds
]
flatten_centerness = [
centerness.permute(0, 2, 3, 1).reshape(-1)
for centerness in centernesses
]
"""拆分后将所有的标签和target都连接起来,此时所有的Tensor均等长"""
flatten_cls_scores = torch.cat(flatten_cls_scores)
flatten_bbox_preds = torch.cat(flatten_bbox_preds)
flatten_centerness = torch.cat(flatten_centerness)
flatten_labels = torch.cat(labels)
flatten_bbox_targets = torch.cat(bbox_targets)
"""将定位点也进行扩展、展开,以便生成最终的边框预测结果"""
flatten_points = torch.cat(
[points.repeat(num_imgs, 1) for points in all_level_points])
"""前景(目标)类别范围: [0, num_classes -1], 背景类别标签: num_classes"""
bg_class_ind = self.num_classes
"""Tensor.nonzero()得到非零值索引,这里pos_inds指正样本的索引值"""
pos_inds = ((flatten_labels >= 0)
& (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
num_pos = torch.tensor(
len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)
"""计算分类的损失函数"""
loss_cls = self.loss_cls(
flatten_cls_scores, flatten_labels, avg_factor=num_pos)
"""对于边框回归和中心度预测,只对正样本计算损失函数"""
pos_bbox_preds = flatten_bbox_preds[pos_inds]
pos_centerness = flatten_centerness[pos_inds]
pos_bbox_targets = flatten_bbox_targets[pos_inds]
pos_centerness_targets = self.centerness_target(pos_bbox_targets)
# centerness weighted iou loss
centerness_denorm = max(
reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
if len(pos_inds) > 0:
pos_points = flatten_points[pos_inds]
"""因为IOU Loss需要计算两个边框的IOU,所以先将bbox delta解码为边框再进行计算"""
pos_decoded_bbox_preds = distance2bbox(pos_points, pos_bbox_preds)
pos_decoded_target_preds = distance2bbox(pos_points,
pos_bbox_targets)
loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=centerness_denorm)
loss_centerness = self.loss_centerness(
pos_centerness, pos_centerness_targets, avg_factor=num_pos)
else:
loss_bbox = pos_bbox_preds.sum()
loss_centerness = pos_centerness.sum()
"""最终返回损失函数字典"""
return dict(
loss_cls=loss_cls,
loss_bbox=loss_bbox,
loss_centerness=loss_centerness)
小结
用一张图总结 训练流程:
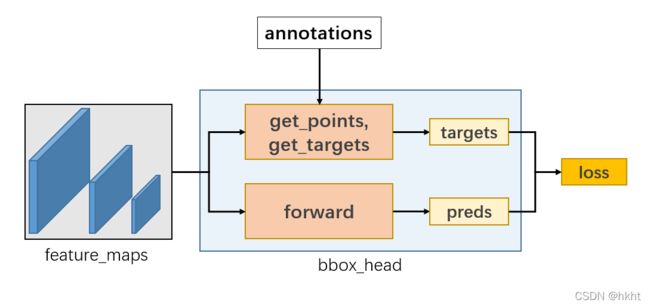
除上述内容以外,FCOSHead中还有_get_bbox()等方法用于生成最终的边框,这里不做重点叙述,感兴趣的同学自己看代码吧~
总结
本章非常非常详细地讲解了FCOS方法的代码构建和运行过程,包括模型整体结构,预测目标值的生成以及损失函数的计算。在这里很佩服mmdetection的代码贡献者们,把模型拆分得很清楚,细细看下来也不难理解。本章的学习就到这里啦,有疑问的同学可以在评论区留言~