深度学习—常见的神经网络结构
一、卷积神经网络结构
常见的卷积神经网络结构: 服务器上:LeNet、AlexNet、VGG、InceptionV1-V4、Inception-ResNet、ResNet 手机上:SqueezNet、NASNet
二、卷积参数量的计算
1、卷积层参数量
需要与上一节中的进行区分卷积核计算参数进行区分
卷积层参数量parameter=(W×H×C+1)*Cout
其中,W为卷积核的宽;H为卷积核的高;+1为偏执量;C为上一层通道数;Cout为下一层通道数
1、全连接层参数量
全连接层的参数量parameter=(Nin+1)*Nout
其中,Nout输入的特征向量权重;Nin输出的特征向量权重;+1为偏执量
三、Lenet网络模型
Lenet是一个基础网络结构,其网络结构如下:
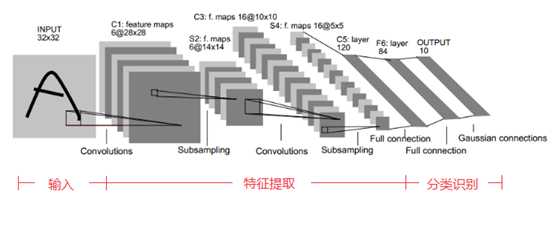
Lenet模型总结: 1、卷积神经网络使用一个三层的序列组合:卷积、下采样(池化)、非线性映射(LeNet-5最重要的特性,奠定了目前深层卷积网络的基础) 2、使用卷积提取空间特征 3、使用映射的空间均值进行下采样 4、使用TANH或sigmoid进行非线性映射 5、多层神经网络MLP作为最终分类器
四、ALexnet网络模型
ALexnet使用了8层卷积神经网络,赢得了2012ImageNet挑战赛,错误率为16.4%,在这之前是28.2%,其网络结构如下:
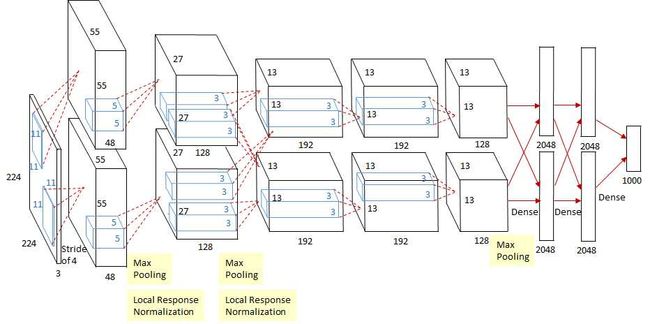
以第一步操作为例进行讲解:
输入:224*224*3
经过卷积:
卷积:11*11;步长:4;补边:0
卷积核形状:48*3*11*11
输出:2*48*55*55
ALexnet模型小结: 1、AlexNet 跟LeNet结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集ImageNet.它是浅层神经网络和深度神经网络的分界线。虽然看上去AlexNet的实现比LeNet的实现也就多了几行代码而已,但这个观念上的转变和真正优秀实验结果的产生令学术界付出了很多年。 2、由五层卷积和三层 全连接组成,输入图像为三通道224×224大小,网络规模远大于LeNet(32×32) 3、所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快 4、在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模 5、使用**随机丢弃技术(dropout)**选择性地忽略训练中的单个神经元, 可以作为正则项防止过拟合,提升模型鲁棒性,避免模型的过拟合
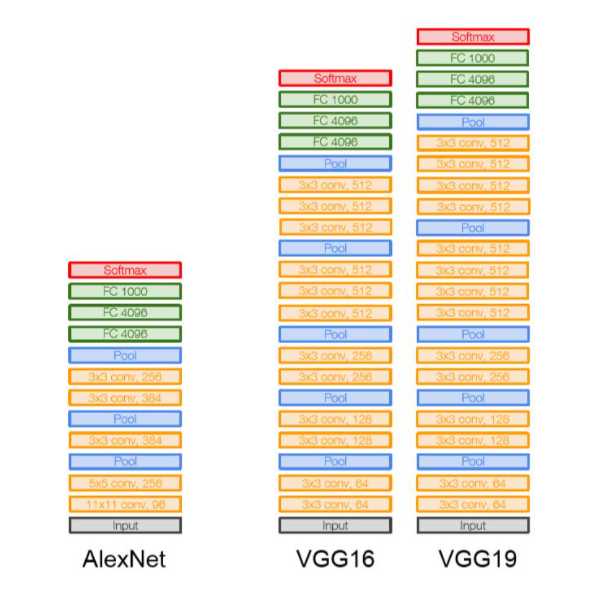
五、VGG网络模型
VGGNet由牛津大学提出,是首批把图像分类的错误率降低到10%以内的模型,该网络采用3×3卷积核的思想是后来许多模型基础。 VGGNet基本单元都一样:卷积、池化、全连接模块,常用的是VGG16-3以及VGG19
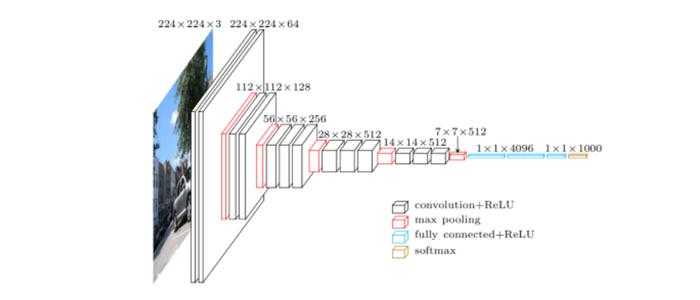
输入层:224*224*3
卷积:3*3(全程都这个大小),补边:1(默认),步长:1(计算得出)
计算公式:N=(W-F+2P)/S+1
计算:(224-3+2*1)/x+1=224
x=1
卷积核尺寸:64*3*3*3
输出层:224*224*64
池化:2*2,步长:2
输出层:112*112*64
卷积:3*3(全程都这个大小),补边:1
计算:(224-3+2*1)+1=224
卷积核尺寸:128*64*3*3
输出层:112*112*128
..........
..........
..........
其余过程与上述过程类似
遇到一个max pooling除以2
在VGG16中只算卷积层,池化层不算,故16层
VGG模型小结 1、整个网络都使用 了同样大小的卷积核尺寸3 X3和最大池化尺寸2 X2。 2、1 X1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。 3、两个3 X3的卷积层串联相当于1个5 X5的卷积层,感受野大小为5 X5。同样地,3个3 X3的卷积层串联的效果则相当于1个7 X7的卷积层。这样的连接方式使得网络参数量更小。而且多层的激活函数令网络对特征的学习能力更强。 4、VGGNet 在训练时有一个小技巧,先训练浅层的的简单网络VGGII,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
网络框架核心思想:用3×3可以代替5×5 对于特征图5×5大小进行特征提取,变成1×1大小,使用不同卷积核进行对比 在这里插入图片描述](https://img-blog.csdnimg.cn/20210520125413271.png)
| 卷积核大小 | 卷积核参数 |
|---|---|
| 3×3 | 18 |
| 5×5 | 25 |
六、Googlent网络模型
googlenet作为2014年ILSVRC在分类任务上的冠军,以6.65的错误率%超过VGG等模型,其网络结构核心部分为inception块 Vgg在深度做扩展;Googlenet在广度上做扩展,inception块模型如下:
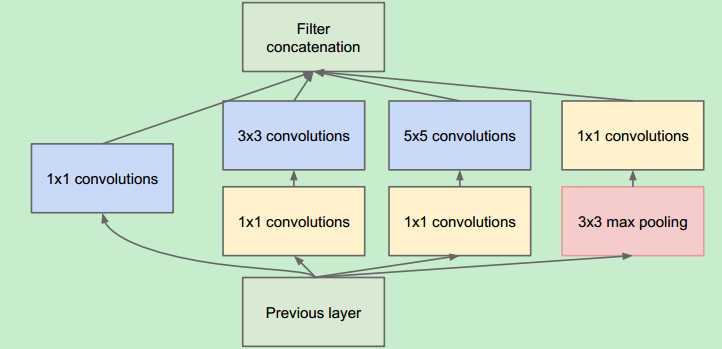
具体分析inception块:
输入层(任意一步的特征图):以输入层为:224*224*3为例
输入层:224*224*3
第一部分:使用1*1卷积,目标得到输出层224*224*100
第二部分:使用1*1卷积,目标得到输出层224*224*10
使用3*3卷积,补边1,目标得到输出层224*224*100
第三部分:使用1*1卷积,目标得到输出层224*224*10
使用5*5卷积,补边2,目标得到输出层224*224*100
第四部分:使用3*3池化,目标得到输出层224*224*3
(池化操作,特征图层数不变 )
使用1*1卷积,目标得到输出层224*224*100
最后进行层数拼接得到输出层:224*224*400
| 各部分 | 输入层 | 输出层 | 输出层 | 参数量总数 |
|---|---|---|---|---|
| 第一部分 | 224×224×3 | ———— | 224×224×100 | 100×3×3×3 |
| 第二部分 | 224×224×3 | 224×224×10 | 224×224×100 | 10×3×1×1+10×100×3×3 |
| 第三部分 | 224×224×3 | 224×224×10 | 224×224×100 | 10×3×1×1+100 ×10×5×5 |
| 第四部分 | 224×224×3 | 224×224×3 | 224×224×100 | 100×3×3×3 |
正常参数应该会变得小,但是224这个参数不好,无法体现,从多个角度观察,可以缩小参数
Googlenet模型小结 1、采用不同大小的卷 积核意味着不同大小的感受紧,最后拼接意味着不同尺度特征的融合: 2、之所以卷积核 大小采用1.3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0. 1. 2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了: 3、网络越到后面, 特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3×3 和5×5卷积的比例也要增加。但是,使用5×5的卷积核仍然会带来巨大的计算量。为此, 采用1×1卷积核来进行降维。
七、ResNet网络模型
通俗来讲,就是在一个浅层的网络模型上进行改造,然后将新的模型与原来的浅层模型相比较,这里有个底线就是,改造后的模型至少不应该比原来的模型表现要差。因为新加的层可以让它的结果为0,这样它就等同于原来的模型了。这个假设是ReNet的出发点,核心就是残差块。如下图所示
residual结构(残差结构)
residual结构描述
输入层:256*256
左侧参数量:3*3*256*256+*3*256*256=1179684
用1×1的卷积核用来降维和升维
右侧参数量:1*1*256*64+3*3*64*64+1*1*64*256=69632
ResNet模型小结 1.超深的网络结构(突破1000层) 2.提出residual模块 3.使用Batch Normalization加速训练(丢弃dropout) 4.除了残差块,还使用批量归一化:BN层
八、DenseNet网络模型
CVPR2017年的Best paper,从特征角度考虑,通过特征重用和旁路设置(Bypass)设置,既大幅度减少网络的参数量,又在一定程度上缓解了gradient vanishing问题。
DenseNet模型小结 1、相比ResNet拥有更少的参数数量; 2、旁路加强了特征的重用; 3、网络更易于训练,并具有一一定的正则效果; 4、缓解了gradient vanishing利model degradation的问题。
九、SENet网络模型
SENet是Image2017(收官赛)的冠军模型,全称为压缩和激励网络
| 年份 | 网络模型 | 错误率 |
|---|---|---|
| 2014 | Google LeNet | 6.67% |
| 2015 | ResNet | 3.57% |
| 2016 | —– | 2.99% |
| 2017 | SENET | 2.25% |
网络过程: (1)进行卷积,变成HWC, (2)C个通道编变成一个一维通道,11C个数值 (3)对特征图不同通道赋值权重
(1)**Squeeze部分:**即为压缩部分,原始feature map的维度为HWC,其中H是高度(Height) ,W是宽度(width),C是通道数(channel) 。Squeeze做的事情是把HWC压缩为11C,相当于把HW压缩成一维了,实际中般是用Eglobal average pooling实现的。HW压缩成一维后,相当于这一维参数获得了之前HW全局的视野,感受区域更广。 (2) **Excitation部分:**得到Squeeze的11*C的表示后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。
十、模型的问题及解决方法
1、1×1卷积核的好处
进行一次线性变换,重新组织特征 将特征图通道数进行升维和降维
2、过拟合与欠拟合
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。过度的拟合了训练数据,而没有考虑到泛化能力。见下图,为了解决这一问题使用dropout的方式解决。
使用dropout的方式在网络正向传播过程中随机失活一部分神经元,dropout随机冻结神经元,类似于一个随机森林,在训练过程中每次冻结一些,在梯度回传的过程中,提高泛化性。
3、深层次网络的问题
神经网络叠的越深,学习出的效果一定越好吗? 人们发现当模型层数到达某种程度,模型效果将会不升反降,也就是说模型发生退化(degradation)情况 下图左侧为训练误差,右侧为测试误差,20层的误差低于56层
网络继续加深————产生退化————梯度消失、爆炸