一、监控框架
| Bigdata1 | Bigdata2 | Bigdata3 | |
|---|---|---|---|
| Zabbix | zabbix-server zabbix-agent |
zabbix-agent | zabbix-agent |
| Ganglia | ganglia |
二、Zabbix 4.2.8
2.1 概念
Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件。Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警。这样可以快速反馈服务器的问题。基于已存储的数据,Zabbix提供了出色的报告和数据可视化功能。
2.2 组件
- 主机(Host)
一台你想监控的网络设备,用IP或域名表示。 - 监控项(Item)
你想要接收的主机的特定数据,一个度量数据。 - 触发器(Trigger)
一个被用于定义问题阈值和“评估”监控项接收到的数据的逻辑表达式。 - 动作(Action)
一个对事件做出反应的预定义的操作,比如邮件通知。
2.3 部署
-
每台安装yum的repo文件
sudo rpm -Uvh https://mirrors.aliyun.com/zabbix/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-2.el7.noarch.rpm -
将文件中的镜像域名替换为阿里云
sudo sed -i 's/http:\/\/repo.zabbix.com/https:\/\/mirrors.aliyun.com\/zabbix/g' /etc/yum.repos.d/zabbix.repo -
安装
-
bigdata1:
sudo yum install -y zabbix-server-mysql zabbix-web-mysql zabbix-agent -
bigdata2和bigdata3
bigdata2: sudo yum install -y zabbix-agent bigdata3: sudo yum install -y zabbix-agent
-
-
MySQL创建数据库
mysql -h 192.168.32.244 -uroot -phxr -e"create database zabbix charset utf8 collate utf8_bin";使用zabbix的建表脚本建表
zcat /usr/share/doc/zabbix-server-mysql-4.0.29/create.sql.gz | mysql -h 192.168.32.244 -uroot -phxr zabbix -
配置Zabbix_Server
在bigdata1中的/etc/zabbix/zabbix_server.conf配置文件中添加DBHost=bigdata3 DBName=zabbix DBUser=root DBPassword=hxr在所有节点的/etc/zabbix/zabbix_server.conf配置文件中修改
# 修改 Server=bigdata1 # 注销 # ServerActive=127.0.0.1 # Hostname=Zabbix server -
配置Zabbix Web时区
在/etc/httpd/conf.d/zabbix.conf文件中添加php_value date.timezone Asia/Shanghai
-
启动Zabbix
-
bigdata1启动:
sudo systemctl start/stop zabbix-server zabbix-agent httpd (httpd是访问html等页面的入口)bigdata1设置开机自启:
sudo systemctl enable/disable zabbix-server zabbix-agent httpd -
bigdata2/3启动:
sudo systemctl start/stop zabbix-agent设置开机自启:
sudo systemctl enable/disable zabbix-agent
-
- 访问页面
http://192.168.32.242/zabbix (默认账号密码为 Admin/zabbix)
在页面中完成对Zabbix_Web的数据库等配置
如果配置出现错误,可以在配置文件/etc/zabbix/web/zabbix.conf.php中进行修改
异常日志可以查看 cat /var/log/zabbix/zabbix_server.log
2.4 实现进程监控
配置主机
在配置-> 主机-> 创建主机 中添加需要监控的主机-
配置监控项
创建完主机后,点击监控项进行监控项的创建
如监控datanode进行是否正常运行
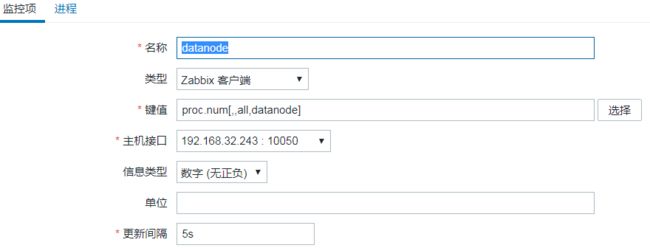 image.png
image.png -
配置触发器
点击触发器进行创建
 image.png
image.png -
通知方式设置
在管理-> 报警媒介类型 中进行通知报警的配置
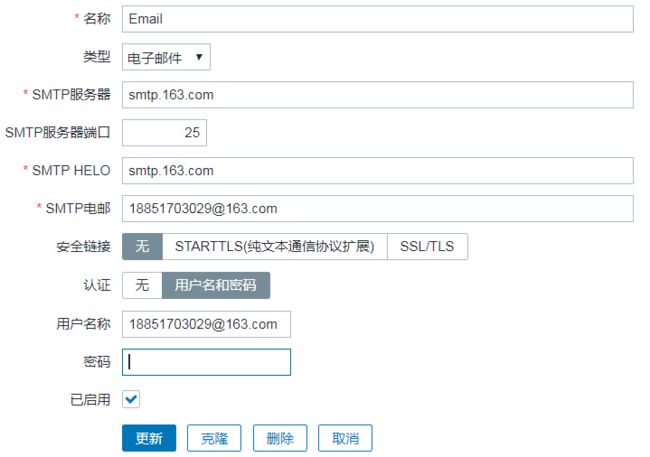 image.png
image.png -
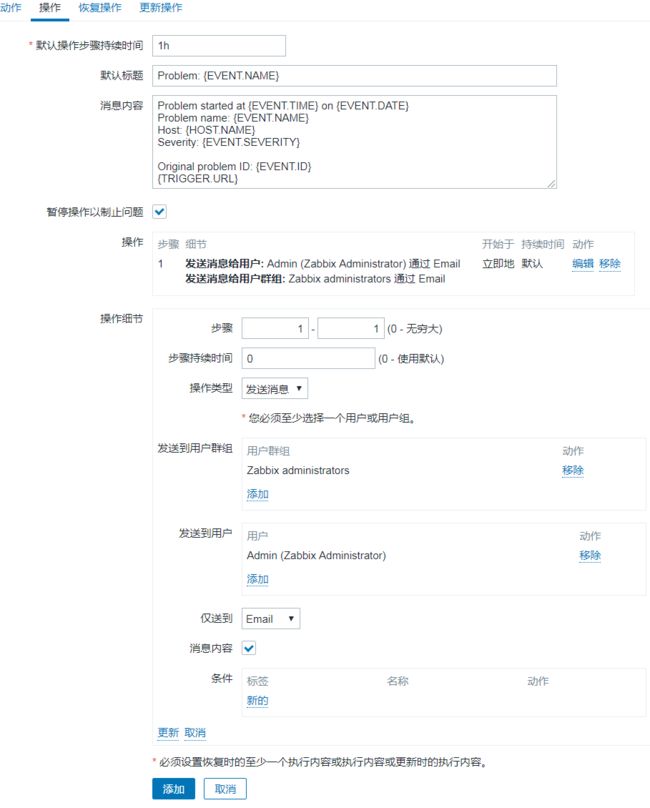
创建动作
在配置-> 动作中创建动作,为触发器设置动作(发邮件)。
 image.png
image.png
-
为用户配置邮箱
在用户的基本资料中配置
 image.png
image.png -
使用模版为每个节点进行配置
默认有很多框架的模板可以选择,如MySQL、redis等。但是没有hadoop的模板,需要自己配置。
在配置-> 模板 中进行模板配置,创建监控项、触发器,然后应用到主机上。
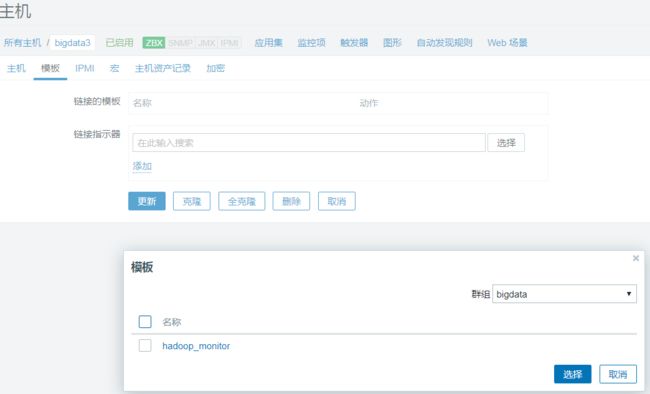 image.png
image.png
注意需要修改动作来为模板的触发器绑定动作。
三、Prometheus
3.1 特点
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统,Prometheus具有以下优点:
3.1.1 易于管理
- Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
- Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。
- 对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
3.1.2 监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
3.1.3 强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
- http_request_status:指标名称(Metrics Name)
- {code='200',content_path='/api/path',environment='produment'}:表示维度的标签,基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
- [value1@timestamp1,value2@timestamp2...]:按照时间的先后顺序 存储的样本值。
3.1.4 强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- 预测在4小时后,磁盘空间占用大致会是什么情况?
- CPU占用率前5位的服务有哪些?(过滤)
3.1.5 高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点
3.1.6 可扩展
可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
3.1.7 易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持:Java,JMX,Python,Go,Ruby,.Net,Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到 Prometheus的监控当中,或者开发自己的监控数据收集程序。
同时这些客户端收集的监控数据,不仅仅支持 Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:Graphite, Statsd, Collected, Scollector, muini, Nagios等。 Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX,CloudWatch,EC2,MySQL,PostgresSQL,Haskell,Bash,SNMP,Consul,Haproxy,Mesos,Bind,CouchDB,Django,Memcached,RabbitMQ,Redis,RethinkDB,Rsyslog等等。
3.1.8 可视化
- Prometheus Server中自带的Prometheus UI,可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案 Promdash。
- 最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。
- 基于Prometheus提供的API还可以实现自己的监控可视化UI。
3.1.9 开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持,因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制,对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。 因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
3.2 Prometheus的架构
3.2.1 Prometheus生态圈组件
- Prometheus Server:主服务器,负责收集和存储时间序列数据
- client libraies:应用程序代码插桩,将监控指标嵌入到被监控应用程序中
- Pushgateway:推送网关,为支持short-lived作业提供一个推送网关
- exporter:专门为一些应用开发的数据摄取组件—exporter,例如:HAProxy、StatsD、Graphite等等。
- Alertmanager:专门用于处理alert的组件
3.2.2 架构理解
1. 存储计算层
- Prometheus Server,里面包含了存储引擎和计算引擎。
- Retrieval组件为取数组件,它会主动从Pushgateway或者Exporter拉取指标数据。
- Service discovery,可以动态发现要监控的目标。
- TSDB,数据核心存储与查询。
- HTTP server,对外提供HTTP服务。
2. 采集层
采集层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业。
- 短作业:直接通过API,在退出时间指标推送给Pushgateway。如Flink任务每次在不同节点上启动一个executor执行短作业,结束时推送给Pushgateway,Prometheus从Pushgateway获取数据。
- 长作业:Retrieval组件直接从Job或者Exporter拉取数据。
3. 应用层
应用层主要分为两种,一种是AlertManager,另一种是数据可视化。
- AlertManager
对接Pagerduty,是一套付费的监控报警系统。可实现短信报警、5分钟无人ack打电话通知、仍然无人ack,通知值班人员Manager...
Emial,发送邮件
... ... - 数据可视化
Prometheus build-in WebUI
Grafana
其他基于API开发的客户端
3.3 安装
3.3.1 安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
- 解压压缩包 prometheus-2.30.3.linux-amd64.tar.gz
- 修改配置文件 prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.101.174:9090"]
- job_name: "pushgateway"
static_configs:
- targets: ['192.168.101.174:9091']
labels:
instance: pushgateway
- job_name: "node exporter"
static_configs:
- targets: ['192.168.101.179:9100','192.168.101.180:9100','192.168.101.181:9100']
- job_name: "process exporter"
static_configs:
- targets: ['192.168.101.179:9256','192.168.101.180:9256','192.168.101.181:9256','192.168.101.176:9256']
- 启动服务
nohup ./prometheus --config.file=./prometheus.yml 1>./prometheus.log 2>&1 &
prometheus启动命令添加参数
--web.enable-lifecycle然后热重启:curl -XPOST http://localhost:9090/-/reload
alertmanager热重启:curl -XPOST http://localhost:9093/-/reload
3.3.2 安装Pushgateway
- 解压压缩包 pushgateway-1.4.2.linux-amd64.tar.gz
- 启动服务
./pushgateway
3.3.3 安装Node Exporter(选择性安装)
- 解压压缩包node_exporter-1.2.2.linux-amd64.tar.gz
- 启动服务
./node_exporter
3.3.4 安装process-exporter
process-exporter 可以监控应用的运行状态(譬如监控redis、mysql的进程资源等)。
解压压缩包 process-exporter-0.7.8.linux-amd64
配置需要监控的进程的名称,他会去搜索该进程从而得到其需要的监控信息,其实也就是我们常做的“ps -efl | grep xxx”命令来查看对应的进程。在各自节点创建配置文件process_config.yml,并配置如下,用于监测大数据框架中主要进程的状况:
bigdata1节点
process_names:
- name: "{{.Matches}}"
cmdline:
- 'NameNode'
- name: "{{.Matches}}"
cmdline:
- 'DataNode'
- name: "{{.Matches}}"
cmdline:
- 'NodeManager'
- name: "{{.Matches}}"
cmdline:
- 'QuorumPeerMain'
- name: "{{.Matches}}"
cmdline:
- 'Kafka'
- name: "{{.Matches}}"
cmdline:
- 'flume'
- 'edb_order_kafka2hdfs.job'
- name: "{{.Matches}}"
cmdline:
- 'AzkabanExecutorServer'
- name: "{{.Matches}}"
cmdline:
- 'HiveServer2'
- name: "{{.Matches}}"
cmdline:
- 'node_exporter'
- name: "{{.Matches}}"
cmdline:
- 'rangerusersync'
- name: "{{.Matches}}"
cmdline:
- 'rangeradmin'
bigdata2节点
process_names:
- name: "{{.Matches}}"
cmdline:
- 'ResourceManager'
- name: "{{.Matches}}"
cmdline:
- 'DataNode'
- name: "{{.Matches}}"
cmdline:
- 'NodeManager'
- name: "{{.Matches}}"
cmdline:
- 'QuorumPeerMain'
- name: "{{.Matches}}"
cmdline:
- 'Kafka'
- name: "{{.Matches}}"
cmdline:
- 'flume-1.7.0/job/youmeng_order_kafka2hdfs.job'
- name: "{{.Matches}}"
cmdline:
- 'flume-1.7.0/job/youmeng_active_kafka2hdfs.job'
- name: "{{.Matches}}"
cmdline:
- 'AzkabanExecutorServer'
- name: "{{.Matches}}"
cmdline:
- 'AzkabanWebServer'
- name: "{{.Matches}}"
cmdline:
- 'node_exporter'
bigdata3节点
process_names:
- name: "{{.Matches}}"
cmdline:
- 'SecondaryNameNode'
- name: "{{.Matches}}"
cmdline:
- 'DataNode'
- name: "{{.Matches}}"
cmdline:
- 'NodeManager'
- name: "{{.Matches}}"
cmdline:
- 'JobHistoryServer'
- name: "{{.Matches}}"
cmdline:
- 'QuorumPeerMain'
- name: "{{.Matches}}"
cmdline:
- 'Kafka'
- name: "{{.Matches}}"
cmdline:
- 'AzkabanExecutorServer'
- name: "{{.Matches}}"
cmdline:
- 'node_exporter'
| name参数 | 说明 |
|---|---|
| {{.Comm}} | 包含原始可执行文件的基本名称,即第二个字段 /proc/ |
| {{.ExeBase}} | 包含可执行文件的基名 |
| {{.ExeFull}} | 包含可执行文件的完全限定路径 |
| {{.Username}} | 包含有效用户的用户名 |
| {{.Matches}} | map包含应用cmdline regexps产生的所有匹配项 |
例:
[root@izx7dvghztbiorz process-exporter]# ps -ef | grep redis
redis 771 1 0 Jun05 ? 00:45:49 /usr/bin/redis-server *:6379
| name参数 | 匹配关键词 | 说明 |
|---|---|---|
| {{.Comm}} | groupname="redis-server" | exe或者sh文件名称 |
| {{.ExeBase}} | groupname="redis-server *:6379" | / |
| {{.ExeFull}} | groupname="/usr/bin/redis-server *:6379" | ps中的进程完成信息 |
| {{.Username}} | groupname="redis" | 使用进程所属的用户进行分组 |
| {{.Matches}} | groupname="map[:redis]" | 表示配置到关键字“redis” |
启动进程
process-exporter -config.path process_config.yml
启动后可以通过执行命令curl 192.168.101.79:9256/metrics来获取监控数据。将process-exporter添加到prometheus中。在prometheus.yml中添加
- job_name: "process exporter"
static_configs:
- targets: ['192.168.101.179:9256','192.168.101.180:9256','192.168.101.181:9256']
重启prometheus。
3.3.5 安装alertmanager
3.3.6 设置开机自启动
以node_exporter和process_exporter为例:
- 编辑脚本
①node_exporter脚本
[Unit]
Description=node_export
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=hxr
ExecStart=/opt/module/node_exporter-1.2.2/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
根据实际情况修改Service中的User和ExecStart的属性,然后将将本放到 /usr/lib/systemd/system/node_exporter.service 路径下。
②process_exporter脚本
[Unit]
Description=process_exporter
Documentation=https://github.com/ncabatoff/process-exporter
After=network.target
[Service]
Type=simple
User=root
EnvironmentFile="CONFIG=-config.path /opt/module/process-exporter-0.5.0/process_config.yml"
ExecStart=/opt/module/process-exporter-0.5.0/process-exporter ${CONFIG}
Restart=on-failure
[Install]
WantedBy=multi-user.target
设为开机自启动
systemctl enable node_exporter.service启动服务
systemctl start node_exporter.service
3.3.7 安装Flume-exporter(监控Flume)
下载Flume_exporter,解压后进行安装
# 首先安装Golang
yum -y install epel-release
yum -y install golang
# 解压flume_exporter
tar -zxvf flume_exporter-0.0.2.tar.gz -C /opt/module
cd /opt/module/flume_exporter-0.0.2/
# 编译
make build
配置config.yml
# Example usage:
# Flume JSON Reporting metrics
agents:
- name: "flume-agents"
enabled: true
# multiple urls can be separated by ,
urls: ["http://localhost:36001/metrics","http://localhost:36002/metrics"]
需要保证flume启动了JSON Reporting,如
sudo -i -u hxr bash -c 'nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a2 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/feiyan_model_kafka2hdfs.job -Dflume.root.logger=INFO,LOGFILE -Dflume.log.file=feiyan_model_kafka2hdfs.log -Xms512m -Xmx512m -Dflume.monitoring.type=http -Dflume.monitoring.port=36001 1>/dev/null 2>&1 &';
启动flume_exporter
nohup /opt/module/flume_exporter-master/flume_exporter-master --metric-file /opt/module/flume_exporter-master/metrics.yml --config-file=/opt/module/flume_exporter-master/config.yml 1>/opt/module/flume_exporter-master/flume_exporter-master.log 2>&1 &
启动后可以查看Flume的JSON Reporting,也可以查看Flume_exporter的日志
配置Prometheus拉取Flume_exporter日志信息
- job_name: "flume exporter"
static_configs:
- targets: ['192.168.101.181:9360']
- labels:
job: flume
alias: flume_feiyan_model
热重启Prometheus
curl -X POST http://localhost:9090/-/reload,然后访问Prometheus UI,输入Flume某一参数查询条件FLUME_CHANNEL_ChannelSize可以得到监控到的值。
配置Grafana
3.4 PromQL
Prometheus通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而label则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。
3.4.1基本用法
3.4.1.1查询时间序列
当Prometheus通过Exporter采集到相应的监控指标样本数据后,我们就可以通过PromQL对监控样本数据进行查询。
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如:
prometheus_http_requests_total
等同于:
prometheus_http_requests_total{}
该表达式会返回指标名称为prometheus_http_requests_total的所有时间序列:
prometheus_http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}= ([email protected])
prometheus_http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}= ([[email protected]](mailto:[email protected]))
PromQL还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
PromQL支持使用 = 和 != 两种完全匹配模式:
- 通过使用 label=value 可以选择那些 标签满足表达式定义的时间序列;
- 反之使用 label!=value 则可以根据标签匹配排除时间序列;
例如,如果我们只需要查询所有prometheus_http_requests_total时间序列中满足标签instance为localhost:9090的时间 序列,则可以使用如下表达式:
prometheus_http_requests_total{instance="localhost:9090"}
反之使用 instance!="localhost:9090" 则可以排除这些时间序列:
prometheus_http_requests_total{instance!="localhost:9090"}
PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之间使用 | 进行分离:
- 使用 label=~regx 表示选择那些标签符合正则表达式定义的时间序列;
- 反之使用 label!~regx 进行排除;
例如,如果想查询多个环节下的时间序列序列可以使用如下表达式:
prometheus_http_requests_total{environment=~"staging|testing|development",method!="GET"}
排除用法
prometheus_http_requests_total{environment!~"staging|testing|development",method!="GET"}
3.4.1.2 范围查询
直接通过类似于PromQL表达式httprequeststotal查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。而相应的这样的表达式称之为__瞬时向量表达式。
而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器 [] 进行定义。 例如,通过以下表达式可以选择最近5分钟内的所有样本数据:
prometheus_http_request_total{}[5m]
该表达式将会返回查询到的时间序列中最近5分钟的所有样本数据:
prometheus_http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=[
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
] 9. prometheus_http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}=[
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
]
通过区间向量表达式查询到的结果我们称为区间向量。 除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
3.4.1.3 时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
http_request_total{} # 瞬时向量表达式,选择当前最新的数据
http_request_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5分钟内的数据。
而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为offset。 可以使用offset时间位移操作:
prometheus_http_request_total{} offset 5m
prometheus_http_request_total{}[1d] offset 1d
3.4.1.4 使用聚合操作
一般来说,如果描述样本特征的标签(label)在并非唯一的情况下,通过PromQL查询数据,会返回多条满足这些特征维度的时间序列。而PromQL提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列:
# 查询系统所有http请求的总量
sum(prometheus_http_request_total)
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu_seconds_total) by (mode)
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu_seconds_total{mode!='idle'}[5m])) / sum(irate(node_cpu _ seconds_total [5m]))) by (instance)
3.4.1.5 标量和字符串
除了使用瞬时向量表达式和区间向量表达式以外,PromQL还直接支持用户使用标量(Scalar)和字符串(String)。
- 标量(Scalar):一个浮点型的数字值
标量只有一个数字,没有时序。 例如:
10
需要注意的是,当使用表达式count(prometheus_http_requests_total),返回的数据类型,依然是瞬时向量。用户可以通过内置函数scalar()将单个瞬时向量转换为标量。 - 字符串(String):一个简单的字符串值
直接使用字符串,作为PromQL表达式,则会直接返回字符串。"this is a string" 'these are unescaped: \n \\ \t' `these are not unescaped: \n ' " \t`
3.4.1.6 合法的PromQL表达式
所有的PromQL表达式都必须至少包含一个指标名称(例如http_request_total),或者一个不会匹配到空字符串的标签过滤器(例如{code=”200”})。
因此以下两种方式,均为合法的表达式:
prometheus_http_request_total # 合法
prometheus_http_request_total{} # 合法
{method="get"} # 合法
而如下表达式,则不合法:
{job=~".*"} # 不合法
同时,除了使用 {label=value} 的形式以外,我们还可以使用内置的 name 标签来指定监控指标名称:
{__name__=~"prometheus_http_request_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法
3.4.2 PromQL操作符
使用PromQL除了能够方便的按照查询和过滤时间序列以外,PromQL还支持丰富的操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等。
3.4.2.1 数学运算
PromQL支持的所有数学运算符如下所示:
- + (加法)
- - (减法)
- * (乘法)
- / (除法)
- % (求余)
- ^ (幂运算)
3.4.2.2
Prometheus支持以下布尔运算符如下:
- == (相等)
- != (不相等)
- >(大于)
- < (小于)
- >= (大于等于)
- <= (小于等于)
使用bool修饰符改变布尔运算符的行为
布尔运算符的默认行为是对时序数据进行过滤。而在其它的情况下我们可能需要的是真正的布尔结果。例如,只需要 知道当前模块的HTTP请求量是否>=1000,如果大于等于1000则返回1(true)否则返回0(false)。这时可以使 用bool修饰符改变布尔运算的默认行为。 例如:
prometheus_http_requests_total > bool 1000
使用bool修改符后,布尔运算不会对时间序列进行过滤,而是直接依次瞬时向量中的各个样本数据与标量的比较结果 0或者1。从而形成一条新的时间序列。
prometheus_http_requests_total{code="200",handler="query",instance="localhost:9090",job="prometheus",method="get"} 1
prometheus_http_requests_total{code="200",handler="query_range",instance="localhost:9090",job="prometheus",method="get"} 0
同时需要注意的是,如果是在两个标量之间使用布尔运算,则必须使用bool修饰符
2 == bool 2 # 结果为1
3.4.2.3 使用集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,我们称为瞬时向量。 通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。
目前,Prometheus支持以下集合运算符:
- and (并且)
- or (或者)
- unless (排除)
vector1 and vector2 会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2 中的元素组成。
vector1 or vector2 会产生一个新的向量,该向量包含vector1中所有的样本数据,以及vector2中没有与 vector1匹配到的样本数据。
vector1 unless vector2 会产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成。
3.4.2.4 操作符优先级
对于复杂类型的表达式,需要了解运算操作的运行优先级。例如,查询主机的CPU使用率,可以使用表达式:
100 * (1 - avg (irate(node_cpu_seconds_total{mode='idle'}[5m])) by(job) )
其中irate是PromQL中的内置函数,用于计算区间向量中时间序列每秒的即时增长率。在PromQL操作符中优先级由高到低依次为:
- ^
- *, /, %
- +, -
- ==, !=, <=, =, >
- and, unless
- or
3.4.2.5 PromQL聚合操作
Prometheus还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行 聚合,形成一个新的时间序列。
- sum (求和)
- min (最小值)
- max (最大值)
- avg (平均值)
- stddev (标准差)
- stdvar (标准差异)
- count (计数)
- count_values (对value进行计数)
- bottomk (后n条时序)
- topk (前n条时序)
- quantile (分布统计)
使用聚合操作的语法如下:
([parameter,] ) [without|by ( 其中只有 count_values , quantile , topk , bottomk 支持参数(parameter)。
without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过without和by可以按照样本的问题对数据进行聚合。
例如:
sum(prometheus_http_requests_total) without (instance)
等价于
sum(prometheus_http_requests_total) by (code,handler,job,method)
如果只需要计算整个应用的HTTP请求总量,可以直接使用表达式:
sum(prometheus_http_requests_total)
count_values用于时间序列中每一个样本值出现的次数。count_values会
为每一个唯一的样本值输出一个时间序列,并且每一个时间序列包含一个额外的标签。 例如:
count_values("count", prometheus_http_requests_total)
topk和bottomk则用于对样本值进行排序,返回当前样本值前n位,或者后n位的时间序列。
获取HTTP请求数前5位的时序样本数据,可以使用表达式:
topk(5, prometheus_http_requests_total)
quantile用于计算当前样本数据值的分布情况quantile(φ, express)其中0 ≤ φ ≤ 1。
例如,当φ为0.5时,即表示找到当前样本数据中的中位数:
quantile(0.5, prometheus_http_requests_total)
3.5 Flink的集成
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志。比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
Flink官方支持Prometheus,并且提供了对接Prometheus的jar包,很方便就可以集成。
drwxr-xr-x. 2 hxr hxr 114 7月 23 11:53 external-resource-gpu
drwxr-xr-x. 2 hxr hxr 46 12月 2 2020 metrics-datadog
drwxr-xr-x. 2 hxr hxr 47 7月 23 11:53 metrics-graphite
drwxr-xr-x. 2 hxr hxr 47 7月 23 11:53 metrics-influx
drwxr-xr-x. 2 hxr hxr 42 7月 23 11:53 metrics-jmx
drwxr-xr-x. 2 hxr hxr 49 7月 23 11:53 metrics-prometheus
drwxr-xr-x. 2 hxr hxr 44 7月 23 11:53 metrics-slf4j
drwxr-xr-x. 2 hxr hxr 45 7月 23 11:53 metrics-statsd
-rwxr-xr-x. 1 hxr hxr 654 6月 18 2020 README.txt
3.5.1 拷贝jar包
将flink-metrics-prometheus-1.12.0.jar拷贝到
[root@bigdata1 metrics-prometheus]$ cp /opt/module/flink-1.12.0/plugins/metrics-prometheus/flink-metrics-prometheus-1.12.0.jar /opt/module/flink-1.12.0/lib/
Flink 的 Classpath 位于lib目录下,所以插件的jar包需要放到该目录下.
3.5.2 修改Flink配置
进入到Flink的conf目录,修改flink-conf.yaml
[root@bigdata1 conf]$ vim flink-conf.yaml
添加如下配置:
##### 与Prometheus集成配置 #####
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
# PushGateway的主机名与端口号
metrics.reporter.promgateway.host: hadoop1
metrics.reporter.promgateway.port: 9091
# Flink metric在前端展示的标签(前缀)与随机后缀
metrics.reporter.promgateway.jobName: flink-metrics-ppg
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 30 SECONDS
四、Grafana
Zabbix和Prometheus都可以集成Grafana。
4.1 部署
- 下载Grafana安装包
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.2.2.linux-amd64.tar.gz
- 使用rpm安装Grafana
[hxr@bigdata3 software]$ tar -zxvf grafana-enterprise-8.2.2.linux-amd64.tar.gz -C /opt/module/
启动命令为
/opt/module/grafana-8.2.2/bin/grafana-server web 1>/opt/module/grafana-8.2.2/grafana.log 2>&1
- 设置为服务并开机自启
编辑脚本 grafana.service 如下,并将其放到目录/usr/lib/systemd/system/下
[Unit]
Description=grafana
Documentation=https://github.com/grafana/grafana
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/opt/module/grafana-8.2.2
ExecStart=/opt/module/grafana-8.2.2/bin/grafana-server web 1>/opt/module/grafana-8.2.2/grafana.log 2>&1
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动服务systemctl start grafana
开机自启systemctl enable grafana
4.2 集成
4.2.1 集成Prometheus
4.2.1.1 配置数据源
点击 Configuration->Data Sources->Add data source,找到Prometheus并点击Select。
添加Prometheus数据源属性如下
URL:http://192.168.101.174:9090
点击下方的Save&Test,如果显示成功则添加数据源成功。
4.2.1.2 手动创建仪表盘
点击左边栏 Create -> Dashboard -> Add an empty panel 即可进入仪表盘编辑页面。
点击Metrics browser即可在其中选择或编辑 PromQL语句,将数据以图表的形式显示。可以配置多个监控项。
任务失败监控
以Flink监控为例:
这一个指标监控主要是基于flink_jobmanager_job_uptime 这个指标进行了监控。原理是在job任务存活时,会按照配置metrics.reporter.promgateway.interval上报频率递增。基于这个特点,当任务失败后这个数值就不会改变,就能监控到任务失败。
添加监控项:
30秒为数据上报到 promgateway 频率,除以100为了数据好看,当job任务失败后数 flink上报的promgateway 的 flink_jobmanager_job_uptime指标值不会变化。((flink_jobmanager_job_uptime)-(flink_jobmanager_job_uptime offset 30s))/100 值就会是0,可以配置告警。
配置告警:
在Panel页面中点击 Alert -> Create Alert 即可进入告警配置页面
在告警通知中可以邮件和webhook,webhook可以调用相关接口,执行一些动作。webhook需要提前配置,在这里配置告警时就可以直接引入。
网络延时或任务重启监控
这个告警也是基于flink_jobmanager_job_uptime 指标,在出现网络延时或者重启后进行监控通知,监控指标如下:
((flink_jobmanager_job_uptime offset 30s)-(flink_jobmanager_job_uptime))/1000
1)延时会导致值突然小于-30(正常情况为-30)
2)重启会导致flink_jobmanager_job_uptime指标清零从新从0值上报,导致查询公式值突然大于0(正常情况为-30)
添加监控项:
配置告警规则:
重启次数
基于flink_jobmanager_job_numRestarts 指标,表示flink job的重启次数。一般设置重启策略后,在任务异常重启后这个数值会递增+1。可以单纯的监控重启次数,也可以每次重启都进行告警(差值)。
利用当前值减去30秒前的值,如果等于1证明重启了一次。
添加告警规则:
4.2.1.3 添加模板
手动一个个添加Dashboard比较繁琐,Grafana社区鼓励用户分享Dashboard,通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard模板。
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard。
添加Node_export模板
搜索一个高赞,更新时间比较新且适合项目需求的模板,点击Download JSON将json脚本下载到本地。
然后进入Grafana UI ,点击 Create -> Import -> Upload JSON file ,选择下载的json脚本进行导入。
可以修改该Panel的名称和所属组,选择数据源为Prometheus,点击Import即可创建完成。
添加Flink模板
同理,搜索并选择合适的Flink模板,将JSON脚本下载到本地,导入到Grafana中。
添加Process Exporter模版
官网推荐的模版为https://grafana.net/dashboards/249
添加Flume Exporter模板
Flume Exporter推荐使用 Grafana Dashboard ID: 10736
导入Grafana Dashboard ID为10736的模板
然后配置数据源为Prometheus。
4.2.2 集成Zabbix
需要先在grafana的UI界面中安装zabbix:
在 Configuration -> plugins 中搜索zabbix插件,随后install插件,安装完成后在config中点击enable激活插件。
随后就可以在Add Data Source中找到zabbix插件。
添加Zabbix数据源属性如下
Url:http://192.168.32.242/zabbix/api_jsonrpc.php
Username: Admin
Password:zabbix
点击 Save&test 即可添加数据源。
4.3 告警通知
Granfana从Prometheus获取数据并按用户配置的告警规则向告警模块发送告警信息,然后由这些模块对告警信息进行管理,包括去重、分组、静音、抑制、聚合,最终通过电子邮件、webhook等方式将告警信息通知路由给对应的联系人。
4.3.1 直接使用Grafana发送告警信息
Grafana支持多种告警模式。
如果希望通过邮箱发送告警信息,则配置如下:
- 修改配置文件custom.ini,添加smtp信息
[smtp]
enabled = true
host = smtp.163.com:25 #smtp服务器的地址和端口
user = 188****[email protected] #你登录邮箱的账号
password = NUJPIDR********* #你邮箱账号的密码
from_address = 188****[email protected] #发邮件的账号
from_name = Grafana #自定义的名字
配置Notification channels
在 Alerting->Notification channels 中选择 add channel,type选择Email,
配置完成后点击保存Channel。配置发送告警
我需要监控大数据框架的进程有没有掉,可以先创建查询(通过PromQL进行查询)
然后添加Alert
可以通过Test rule来测试当前条件下是否会发送报警信息。
保存后就会将告警信息发送到配置的channel中,信息如下
如果需要配置重复报警repeat_interval间隔,可以在channel中设置。
如果无法显示图片,需要安装插件Grafana Image Renderer。安装完成之后通过命令ldd grafana-8.2.2/data/plugins/grafana-image-renderer/chrome-linux/chrome查看缺失的环境依赖并安装。
4.3.2 集成AlterManager组件实现告警
解压组件的压缩包 alertmanager-0.23.0.linux-amd64.tar.gz
编辑配置文件 alertmanager.yml
global: #全局配置,主要配置告警方式,如邮件等
resolve_timeout: 5m #解析的超时时间
smtp_smarthost: 'smtp.163.com' #邮箱smtp地址
smtp_from: '188****[email protected]' #来自哪个邮箱发出的
smtp_auth_username: '188****[email protected]' #邮箱的用户名
smtp_auth_password: 'NUJPID**********' #这里是邮箱的授权密码,不是登录密码
smtp_require_tls: false #是否启用tls
route: #设置报警的分发策略,通过route实现告警的分配,所有的报警都会发送到receiver参数配置的接收器中
group_by: ['alertname'] #采用哪个标签进行分组,对告警通知按标签(label进行分组),将具有相同标签或相同警告名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送
group_wait: 30s #分组等待的时间,收到报警后并不是马上发送出去,看看还有没有alertname这个标签的报警发过来,如果有的话,一起发出报警
group_interval: 5m #上一组报警与下一组报警的间隔时间
repeat_interval: 1h #告警通知成功发送后,若问题一直未恢复,需要再次发送的间隔
receiver: 'email' #报警接收人
receivers:
- name: 'email' #谁来接收这个报警
email_configs: #email的配置
- to: '[email protected]' #报警接收人的邮件地址
- to: '[email protected]' #可以写多个邮件地址
send_resolved: true #发送恢复通知
inhibit_rules: #抑制规则,报警抑制角色,用于报警收敛,发送关键报警
- source_match: #匹配到这个报警发生后,其它报警被抑制掉,
severity: 'critical' #报警级别为critical
target_match: #其它报警
severity: 'warning' #报警级别为warning
equal: ['alertname', 'dev', 'instance'] #对此处配置的标签进行报警抑制
配置参数route说明:Prometheus的告警最先到达根路由(route),是所有告警的入口点,不能包含任何匹配项。另外,根路由需要配置一个接收器(receiver),用来处理哪些没有匹配到任何子路由的告警(如果没有子路由,则全部由根路由发送告警)
Receiver支持的告警模式:
- email_config:发送告警邮件
- slack_config:发送告警信息到slack
- webhook_config:访问配置的url
- pagerduty_config:发送告警信息到pagerduty
- wechat_configs:发送告警信息到钉钉。Alertmanger 从 v0.12 开始已经默认支持企业微信了.
receivers: - name: 'wechat' wechat_configs: - corp_id: 'xxx' #企业微信账号唯一 ID, 可以在我的企业中查看 to_party: '1' #需要发送的组 agent_id: '1000002' #第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看 api_secret: 'xxxx' #第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看 send_resolved: true #发送恢复通知
- 启动alertmanager
alertmanager/alertmanager --config.file=/usr/local/alertmanager/grafana.yml --storage.path=/usr/local/alertmanager/data/ --log.level=debug
-
配置Grafana的Notification Channel
在 Alerting->Notification channels 中选择 add channel,type选择Prometheus Alertmanager,Url写alertmanager所在节点,如192.168.101.174:9093。
配置完成后点击保存Channel。注意: prometheus 默认时区为UTC且无法改变时区,官方建议在用户的web ui 中重新设置时区,因此我们的报警时间应该+8:00
配置Grafana的发送报警信息
同理,只需要将Alert中的Send to添加为配置的alertmanager channel即可。
4.3.3 集成第三方平台睿象云实现告警
注册睿象云账户并登录
点击 智能告警平台 -> 集成,在其中创建Grafana应用,创建完成后得到一个AppKey,可以拼接得到一个Url:http://api.aiops.com/alert/api/event/grafana/v1/${AppKey}
Grafana添加新的channel,channel类型为Webhook,Url处填写上一步得到的url。
在睿象云 [智能告警平台] 的 [配置] 中点击新建分派,和通知策略,保存完成后即可接收Grafana发送的告警信息,并通过配置的方式将信息转发到指定的用户。
五、附
5.1 UI界面
http://192.168.32.242/zabbix Zabbix(Admin:zabbix,报警邮箱[email protected])
5.2 端口
| 组件 | 端口号 | 说明 |
|---|---|---|
| Zabbix | 10051:Zabbix_Server通讯端口 | |
| Prometheus | 9090:prometheus 9100:node-productor 9104:mysqld-exporter 3000:Grafana |
5.3 各jps进程名对应的组件
zabbix作为服务运行,不是java程序。
Prometheus和Grafana以docker容器形式启动。
Ganlia同样以docker容器形式启动。
5.4 命令相关
Zabbix
-
bigdata1启动:
sudo systemctl start/stop zabbix-server zabbix-agent httpd (httpd是访问html等页面的入口)bigdata1设置开机自启:
sudo systemctl enable/disable zabbix-server zabbix-agent httpd -
bigdata2/3启动:
sudo systemctl start/stop zabbix-agent设置开机自启:
sudo systemctl enable/disable zabbix-agent
5.5 组件启停脚本
#!/bin/bash
case $1 in
"start"){
echo '----- 启动 prometheus -----'
nohup /opt/module/prometheus-2.30.3/prometheus --web.enable-admin-api --config.file=/opt/module/prometheus-2.30.3/prometheus.yml > /opt/module/prometheus-2.30.3/prometheus.log 2>&1 &
echo '----- 启动 pushgateway -----'
nohup /opt/module/pushgateway-1.4.2/pushgateway --web.listen-address :9091 > /opt/module/pushgateway-1.4.2/pushgateway.log 2>&1 &
echo '----- 启动 grafana -----'
nohup /opt/module/grafana-8.2.2/bin/grafana-server --homepath /opt/module/grafana-8.2.2 web > /opt/module/grafana-8.2.2/grafana.log 2>&1 &
};;
"stop"){
echo '----- 停止 grafana -----'
pgrep -f grafana | xargs kill
echo '----- 停止 pushgateway -----'
pgrep -f pushgateway | xargs kill
echo '----- 停止 prometheus -----'
pgrep -f prometheus | xargs kill
};;
esac